 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffuse AI Control on Fuzzy Tasks
Jun 08, 2026AI models deployed in critical domains, such as AI safety research, may subtly sabotage our efforts due to misalignment. Diffuse AI Control is a subfield of AI safety concerned with mitigating risks from AI sabotage distributed over long deployment horizons (diffuse threats). These risks are particularly pernicious on fuzzy tasks, i.e. tasks which are hard to grade or require intuition. To understand diffuse threats on fuzzy tasks, we introduce a novel framework that considers AI control as an adversarial game between a blue team and a red team. The blue team uses a weak trusted model to construct a weak score against which they would train a strong, potentially subversive model to remove the subversion propensity if it were present. The red team then tries to find model behaviors that are rated highly by the weak score, and thus might not be trained out, but actually correspond to poor performance. We test our framework on the task of writing experimental proposals for research questions from recent ML papers. We use a language model with access to the original paper as a proxy "ground-truth" scorer. Our red team discovers subversive behaviors using multi-objective evolutionary prompt optimization. We show that Opus~4.6 can write proposals that are worse according to the ground truth proxy than those of GPT-OSS-20B, while the weak scorer rates them as highly as the best proposals from Opus 4.6. To mitigate the threat, we propose an adversarial optimization algorithm for the blue team that discovers more robust prompts for the weak model. This algorithm produces a blue team prompt that our red team optimization fails to exploit.
Faithfulness as Information Flow: Evaluating and Training Faithful Chain-of-Thought Reasoning
May 22, 2026Chain-of-thought (CoT) reasoning is useful for monitoring language models only when the reasoning trace faithfully reflects the computation that produces the final answer. However, models can rely on prompt-to-answer shortcuts that bypass the CoT, making the visible reasoning trace misleading even when it appears plausible. We study CoT faithfulness through a structural information-flow perspective: faithful reasoning should route answer-relevant information through the mediated path from prompt to CoT to answer, rather than through a direct prompt-to-answer shortcut. This perspective yields a task-agnostic framework based on three complementary properties, sufficiency, completeness, and necessity, which we instantiate with entropy-based, masked-KL, and gradient-based diagnostics. We show that these metrics recover externally judged faithfulness differences in hinted reasoning, and identify a low-entropy failure mode of KL-based diagnostics where gradient-based measures remain more stable. Building on this analysis, we introduce update-time interventions for verifier-based on-policy RL, including attention masking, backward-only gradient masking, CoT gradients, and adversarial perturbations of prompt representations. Across hinted arithmetic, reward-hackable code repair, and DAPO-Math models trained without hints but evaluated under wrong-hint injection, our interventions shift behavioral and structural indicators toward stronger CoT mediation. In particular, they make shortcut and reward-hacking behavior more transparent in the CoT and improve task-agnostic faithfulness metrics, while in some settings also reducing wrong-hint susceptibility. Our results suggest that controlling information flow during training is a practical route toward more faithful and monitorable CoT reasoning. Code is available at https://github.com/safety-research/faithful-cot.
Efficiently Aligning Language Models with Online Natural Language Feedback
May 05, 2026Reinforcement learning with verifiable rewards has been used to elicit impressive performance from language models in many domains. But, broadly beneficial deployments of AI may require us to train models with strong capabilities in "fuzzy", hard-to-supervise domains. In this paper, we develop methods to align language models in fuzzy domains where human experts are still able to provide high-quality supervision signal, but only for a small number of model outputs, using online natural language feedback. Specifically, we train models by iteratively optimizing against proxy reward signals, stopping at the point of over-optimization, collecting fresh expert supervision, and updating the proxy reward. We construct proxy reward models from language models using in-context learning (ICL) and fine-tuning. We test our methods by eliciting creative writing and alignment research capabilities in Qwen3-8B and Haiku 4.5 respectively. For Qwen3-8B, ICL methods recover up to 35% of performance with 50x fewer expert samples, while fine-tuning methods recover 80% with up to 20x fewer samples and 100% with 3x fewer samples. For Haiku 4.5, ICL methods recover up to 35% of performance with 30x fewer samples, and fine-tuning methods recover 100% with 10x fewer samples. Our results suggest that online natural language feedback can substantially improve the data efficiency of expert supervision.
Chain of Thought Monitorability: A New and Fragile Opportunity for AI Safety
Jul 15, 2025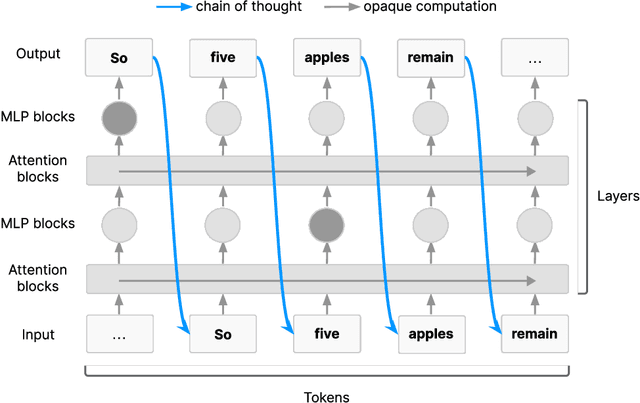
AI systems that "think" in human language offer a unique opportunity for AI safety: we can monitor their chains of thought (CoT) for the intent to misbehave. Like all other known AI oversight methods, CoT monitoring is imperfect and allows some misbehavior to go unnoticed. Nevertheless, it shows promise and we recommend further research into CoT monitorability and investment in CoT monitoring alongside existing safety methods. Because CoT monitorability may be fragile, we recommend that frontier model developers consider the impact of development decisions on CoT monitorability.
Reasoning Models Don't Always Say What They Think
May 08, 2025



Chain-of-thought (CoT) offers a potential boon for AI safety as it allows monitoring a model's CoT to try to understand its intentions and reasoning processes. However, the effectiveness of such monitoring hinges on CoTs faithfully representing models' actual reasoning processes. We evaluate CoT faithfulness of state-of-the-art reasoning models across 6 reasoning hints presented in the prompts and find: (1) for most settings and models tested, CoTs reveal their usage of hints in at least 1% of examples where they use the hint, but the reveal rate is often below 20%, (2) outcome-based reinforcement learning initially improves faithfulness but plateaus without saturating, and (3) when reinforcement learning increases how frequently hints are used (reward hacking), the propensity to verbalize them does not increase, even without training against a CoT monitor. These results suggest that CoT monitoring is a promising way of noticing undesired behaviors during training and evaluations, but that it is not sufficient to rule them out. They also suggest that in settings like ours where CoT reasoning is not necessary, test-time monitoring of CoTs is unlikely to reliably catch rare and catastrophic unexpected behaviors.
Constitutional Classifiers: Defending against Universal Jailbreaks across Thousands of Hours of Red Teaming
Jan 31, 2025



Large language models (LLMs) are vulnerable to universal jailbreaks-prompting strategies that systematically bypass model safeguards and enable users to carry out harmful processes that require many model interactions, like manufacturing illegal substances at scale. To defend against these attacks, we introduce Constitutional Classifiers: safeguards trained on synthetic data, generated by prompting LLMs with natural language rules (i.e., a constitution) specifying permitted and restricted content. In over 3,000 estimated hours of red teaming, no red teamer found a universal jailbreak that could extract information from an early classifier-guarded LLM at a similar level of detail to an unguarded model across most target queries. On automated evaluations, enhanced classifiers demonstrated robust defense against held-out domain-specific jailbreaks. These classifiers also maintain deployment viability, with an absolute 0.38% increase in production-traffic refusals and a 23.7% inference overhead. Our work demonstrates that defending against universal jailbreaks while maintaining practical deployment viability is tractable.
Sabotage Evaluations for Frontier Models
Oct 28, 2024



Sufficiently capable models could subvert human oversight and decision-making in important contexts. For example, in the context of AI development, models could covertly sabotage efforts to evaluate their own dangerous capabilities, to monitor their behavior, or to make decisions about their deployment. We refer to this family of abilities as sabotage capabilities. We develop a set of related threat models and evaluations. These evaluations are designed to provide evidence that a given model, operating under a given set of mitigations, could not successfully sabotage a frontier model developer or other large organization's activities in any of these ways. We demonstrate these evaluations on Anthropic's Claude 3 Opus and Claude 3.5 Sonnet models. Our results suggest that for these models, minimal mitigations are currently sufficient to address sabotage risks, but that more realistic evaluations and stronger mitigations seem likely to be necessary soon as capabilities improve. We also survey related evaluations we tried and abandoned. Finally, we discuss the advantages of mitigation-aware capability evaluations, and of simulating large-scale deployments using small-scale statistics.
When Do Universal Image Jailbreaks Transfer Between Vision-Language Models?
Jul 21, 2024



The integration of new modalities into frontier AI systems offers exciting capabilities, but also increases the possibility such systems can be adversarially manipulated in undesirable ways. In this work, we focus on a popular class of vision-language models (VLMs) that generate text outputs conditioned on visual and textual inputs. We conducted a large-scale empirical study to assess the transferability of gradient-based universal image "jailbreaks" using a diverse set of over 40 open-parameter VLMs, including 18 new VLMs that we publicly release. Overall, we find that transferable gradient-based image jailbreaks are extremely difficult to obtain. When an image jailbreak is optimized against a single VLM or against an ensemble of VLMs, the jailbreak successfully jailbreaks the attacked VLM(s), but exhibits little-to-no transfer to any other VLMs; transfer is not affected by whether the attacked and target VLMs possess matching vision backbones or language models, whether the language model underwent instruction-following and/or safety-alignment training, or many other factors. Only two settings display partially successful transfer: between identically-pretrained and identically-initialized VLMs with slightly different VLM training data, and between different training checkpoints of a single VLM. Leveraging these results, we then demonstrate that transfer can be significantly improved against a specific target VLM by attacking larger ensembles of "highly-similar" VLMs. These results stand in stark contrast to existing evidence of universal and transferable text jailbreaks against language models and transferable adversarial attacks against image classifiers, suggesting that VLMs may be more robust to gradient-based transfer attacks.
Measuring Feature Sparsity in Language Models
Oct 13, 2023



Recent works have proposed that activations in language models can be modelled as sparse linear combinations of vectors corresponding to features of input text. Under this assumption, these works aimed to reconstruct feature directions using sparse coding. We develop metrics to assess the success of these sparse coding techniques and test the validity of the linearity and sparsity assumptions. We show our metrics can predict the level of sparsity on synthetic sparse linear activations, and can distinguish between sparse linear data and several other distributions. We use our metrics to measure levels of sparsity in several language models. We find evidence that language model activations can be accurately modelled by sparse linear combinations of features, significantly more so than control datasets. We also show that model activations appear to be sparsest in the first and final layers.
Linear Convergence Bounds for Diffusion Models via Stochastic Localization
Aug 07, 2023

Diffusion models are a powerful method for generating approximate samples from high-dimensional data distributions. Several recent results have provided polynomial bounds on the convergence rate of such models, assuming $L^2$-accurate score estimators. However, up until now the best known such bounds were either superlinear in the data dimension or required strong smoothness assumptions. We provide the first convergence bounds which are linear in the data dimension (up to logarithmic factors) assuming only finite second moments of the data distribution. We show that diffusion models require at most $\tilde O(\frac{d \log^2(1/\delta)}{\varepsilon^2})$ steps to approximate an arbitrary data distribution on $\mathbb{R}^d$ corrupted with Gaussian noise of variance $\delta$ to within $\varepsilon^2$ in Kullback--Leibler divergence. Our proof builds on the Girsanov-based methods of previous works. We introduce a refined treatment of the error arising from the discretization of the reverse SDE, which is based on tools from stochastic localization.