 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge(Mis)generalization of Helpful-only Fine-tuning
Jun 03, 2026Helpful-only models, that is, models that are trained to always follow user intent, are valuable for dangerous capability evaluations and other areas of AI R&D where refusals would be an obstacle. Little is known about the generalization properties of helpful-only training: helpful-only models refuse less than their harmless counterparts, but previous work has not studied other dimensions of their alignment. We study the shortcomings of existing helpful-only models. We find that some show emergent misalignment, others have residual refusal behaviors, and most show poor steerability, sycophancy, and incoherent character. We show that simple anti-refusal training can cause many of these issues. None of these problems are necessary consequences of helpful-only training, though: we show that synthetic document fine-tuning and adding character-related questions to SFT and RL can mitigate them.
Classifier Context Rot: Monitor Performance Degrades with Context Length
May 12, 2026Monitoring coding agents for dangerous behavior using language models requires classifying transcripts that often exceed 500K tokens, but prior agent monitoring benchmarks rarely contain transcripts longer than 100K tokens. We show that when used as classifiers, current frontier models fail to notice dangerous actions more often in longer transcripts. In particular, on a dataset that requires identifying when a coding agent takes a subtly dangerous action, Opus 4.6, GPT 5.4, and Gemini 3.1 miss these actions $2\times$ to $30\times$ more often when they occur after 800K tokens of benign activity than when they occur on their own. We also show that these weaknesses can be partially mitigated with prompting techniques such as periodic reminders throughout the transcript and may be mitigated further with better post-training. Monitor evaluations that do not consider long-context degradation are likely overestimating monitor performance.
How Useful Is Cross-Domain Generalization for Training LLM Monitors?
May 12, 2026Using prompted language models as classifiers enables classification in domains with limited training data, but misses some of the robustness and performance benefits that fine-tuning can bring. We study whether training on multiple classification tasks, each with its own prompt, improves performance on new domains with new classification prompts. We show that such training partially generalizes to adjacent domains, improving classification performance on tasks that are unseen during training. However, we identify specific edge cases where the fine-tuned models fail to follow prompts, such as when the classification prompt changes completely while the data domain remains the same as during training. We show that classification training can be mixed with general instruction following training, and that (when done well) such training keeps the benefits of classification training and mitigates its generalization failures. Surprisingly, we see that this no-thinking supervised classification training can generalize to with-thinking classification and summarization, suggesting that no-thinking classification training might be instrumentally useful in building other kinds of classifiers and monitoring systems.
Self-Attribution Bias: When AI Monitors Go Easy on Themselves
Mar 04, 2026Agentic systems increasingly rely on language models to monitor their own behavior. For example, coding agents may self critique generated code for pull request approval or assess the safety of tool-use actions. We show that this design pattern can fail when the action is presented in a previous or in the same assistant turn instead of being presented by the user in a user turn. We define self-attribution bias as the tendency of a model to evaluate an action as more correct or less risky when the action is implicitly framed as its own, compared to when the same action is evaluated under off-policy attribution. Across four coding and tool-use datasets, we find that monitors fail to report high-risk or low-correctness actions more often when evaluation follows a previous assistant turn in which the action was generated, compared to when the same action is evaluated in a new context presented in a user turn. In contrast, explicitly stating that the action comes from the monitor does not by itself induce self-attribution bias. Because monitors are often evaluated on fixed examples rather than on their own generated actions, these evaluations can make monitors appear more reliable than they actually are in deployment, leading developers to unknowingly deploy inadequate monitors in agentic systems.
Three Concrete Challenges and Two Hopes for the Safety of Unsupervised Elicitation
Feb 23, 2026To steer language models towards truthful outputs on tasks which are beyond human capability, previous work has suggested training models on easy tasks to steer them on harder ones (easy-to-hard generalization), or using unsupervised training algorithms to steer models with no external labels at all (unsupervised elicitation). Although techniques from both paradigms have been shown to improve model accuracy on a wide variety of tasks, we argue that the datasets used for these evaluations could cause overoptimistic evaluation results. Unlike many real-world datasets, they often (1) have no features with more salience than truthfulness, (2) have balanced training sets, and (3) contain only data points to which the model can give a well-defined answer. We construct datasets that lack each of these properties to stress-test a range of standard unsupervised elicitation and easy-to-hard generalization techniques. We find that no technique reliably performs well on any of these challenges. We also study ensembling and combining easy-to-hard and unsupervised techniques, and find they only partially mitigate performance degradation due to these challenges. We believe that overcoming these challenges should be a priority for future work on unsupervised elicitation.
Excess Description Length of Learning Generalizable Predictors
Jan 08, 2026Understanding whether fine-tuning elicits latent capabilities or teaches new ones is a fundamental question for language model evaluation and safety. We develop a formal information-theoretic framework for quantifying how much predictive structure fine-tuning extracts from the train dataset and writes into a model's parameters. Our central quantity, Excess Description Length (EDL), is defined via prequential coding and measures the gap between the bits required to encode training labels sequentially using an evolving model (trained online) and the residual encoding cost under the final trained model. We establish that EDL is non-negative in expectation, converges to surplus description length in the infinite-data limit, and provides bounds on expected generalization gain. Through a series of toy models, we clarify common confusions about information in learning: why random labels yield EDL near zero, how a single example can eliminate many bits of uncertainty about the underlying rule(s) that describe the data distribution, why structure learned on rare inputs contributes proportionally little to expected generalization, and how format learning creates early transients distinct from capability acquisition. This framework provides rigorous foundations for the empirical observation that capability elicitation and teaching exhibit qualitatively distinct scaling signatures.
Steering Language Models with Weight Arithmetic
Nov 07, 2025Providing high-quality feedback to Large Language Models (LLMs) on a diverse training distribution can be difficult and expensive, and providing feedback only on a narrow distribution can result in unintended generalizations. To better leverage narrow training data, we propose contrastive weight steering, a simple post-training method that edits the model parameters using weight arithmetic. We isolate a behavior direction in weight-space by subtracting the weight deltas from two small fine-tunes -- one that induces the desired behavior and another that induces its opposite -- and then add or remove this direction to modify the model's weights. We apply this technique to mitigate sycophancy and induce misalignment, and find that weight steering often generalizes further than activation steering, achieving stronger out-of-distribution behavioral control before degrading general capabilities. We also show that, in the context of task-specific fine-tuning, weight steering can partially mitigate undesired behavioral drift: it can reduce sycophancy and under-refusals introduced during fine-tuning while preserving task performance gains. Finally, we provide preliminary evidence that emergent misalignment can be detected by measuring the similarity between fine-tuning updates and an "evil" weight direction, suggesting that it may be possible to monitor the evolution of weights during training and detect rare misaligned behaviors that never manifest during training or evaluations.
Inoculation Prompting: Instructing LLMs to misbehave at train-time improves test-time alignment
Oct 06, 2025Large language models are sometimes trained with imperfect oversight signals, leading to undesired behaviors such as reward hacking and sycophancy. Improving oversight quality can be expensive or infeasible, motivating methods that improve learned behavior despite an imperfect training signal. We introduce Inoculation Prompting (IP), a simple but counterintuitive technique that prevents learning of an undesired behavior by modifying training prompts to explicitly request it. For example, to inoculate against reward hacking, we modify the prompts used in supervised fine-tuning to request code that only works on provided test cases but fails on other inputs. Across four settings we find that IP reduces the learning of undesired behavior without substantially reducing the learning of desired capabilities. We also show that prompts which more strongly elicit the undesired behavior prior to fine-tuning more effectively inoculate against the behavior when used during training; this serves as a heuristic to identify promising inoculation prompts. Overall, IP is a simple yet effective way to control how models generalize from fine-tuning, preventing learning of undesired behaviors without substantially disrupting desired capabilities.
Chain of Thought Monitorability: A New and Fragile Opportunity for AI Safety
Jul 15, 2025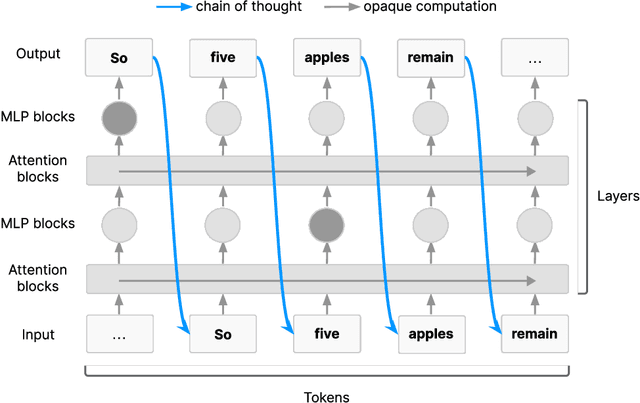
AI systems that "think" in human language offer a unique opportunity for AI safety: we can monitor their chains of thought (CoT) for the intent to misbehave. Like all other known AI oversight methods, CoT monitoring is imperfect and allows some misbehavior to go unnoticed. Nevertheless, it shows promise and we recommend further research into CoT monitorability and investment in CoT monitoring alongside existing safety methods. Because CoT monitorability may be fragile, we recommend that frontier model developers consider the impact of development decisions on CoT monitorability.
Reasoning Models Don't Always Say What They Think
May 08, 2025



Chain-of-thought (CoT) offers a potential boon for AI safety as it allows monitoring a model's CoT to try to understand its intentions and reasoning processes. However, the effectiveness of such monitoring hinges on CoTs faithfully representing models' actual reasoning processes. We evaluate CoT faithfulness of state-of-the-art reasoning models across 6 reasoning hints presented in the prompts and find: (1) for most settings and models tested, CoTs reveal their usage of hints in at least 1% of examples where they use the hint, but the reveal rate is often below 20%, (2) outcome-based reinforcement learning initially improves faithfulness but plateaus without saturating, and (3) when reinforcement learning increases how frequently hints are used (reward hacking), the propensity to verbalize them does not increase, even without training against a CoT monitor. These results suggest that CoT monitoring is a promising way of noticing undesired behaviors during training and evaluations, but that it is not sufficient to rule them out. They also suggest that in settings like ours where CoT reasoning is not necessary, test-time monitoring of CoTs is unlikely to reliably catch rare and catastrophic unexpected behaviors.