 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Elicitation of Language Models
Jun 11, 2025



To steer pretrained language models for downstream tasks, today's post-training paradigm relies on humans to specify desired behaviors. However, for models with superhuman capabilities, it is difficult or impossible to get high-quality human supervision. To address this challenge, we introduce a new unsupervised algorithm, Internal Coherence Maximization (ICM), to fine-tune pretrained language models on their own generated labels, \emph{without external supervision}. On GSM8k-verification, TruthfulQA, and Alpaca reward modeling tasks, our method matches the performance of training on golden supervision and outperforms training on crowdsourced human supervision. On tasks where LMs' capabilities are strongly superhuman, our method can elicit those capabilities significantly better than training on human labels. Finally, we show that our method can improve the training of frontier LMs: we use our method to train an unsupervised reward model and use reinforcement learning to train a Claude 3.5 Haiku-based assistant. Both the reward model and the assistant outperform their human-supervised counterparts.
Reasoning Models Don't Always Say What They Think
May 08, 2025



Chain-of-thought (CoT) offers a potential boon for AI safety as it allows monitoring a model's CoT to try to understand its intentions and reasoning processes. However, the effectiveness of such monitoring hinges on CoTs faithfully representing models' actual reasoning processes. We evaluate CoT faithfulness of state-of-the-art reasoning models across 6 reasoning hints presented in the prompts and find: (1) for most settings and models tested, CoTs reveal their usage of hints in at least 1% of examples where they use the hint, but the reveal rate is often below 20%, (2) outcome-based reinforcement learning initially improves faithfulness but plateaus without saturating, and (3) when reinforcement learning increases how frequently hints are used (reward hacking), the propensity to verbalize them does not increase, even without training against a CoT monitor. These results suggest that CoT monitoring is a promising way of noticing undesired behaviors during training and evaluations, but that it is not sufficient to rule them out. They also suggest that in settings like ours where CoT reasoning is not necessary, test-time monitoring of CoTs is unlikely to reliably catch rare and catastrophic unexpected behaviors.
Values in the Wild: Discovering and Analyzing Values in Real-World Language Model Interactions
Apr 21, 2025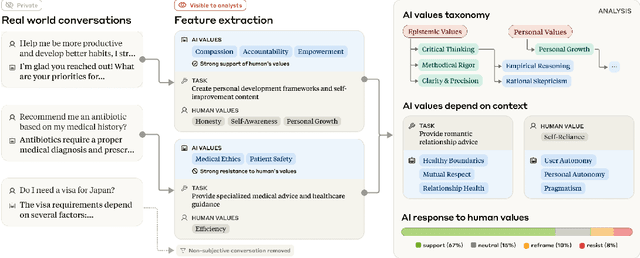
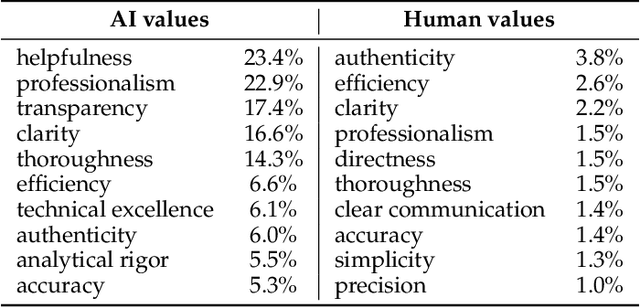
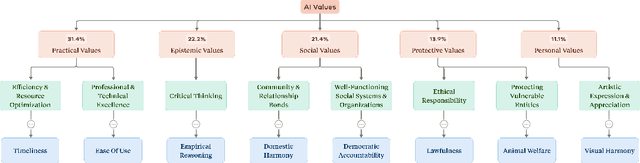

AI assistants can impart value judgments that shape people's decisions and worldviews, yet little is known empirically about what values these systems rely on in practice. To address this, we develop a bottom-up, privacy-preserving method to extract the values (normative considerations stated or demonstrated in model responses) that Claude 3 and 3.5 models exhibit in hundreds of thousands of real-world interactions. We empirically discover and taxonomize 3,307 AI values and study how they vary by context. We find that Claude expresses many practical and epistemic values, and typically supports prosocial human values while resisting values like "moral nihilism". While some values appear consistently across contexts (e.g. "transparency"), many are more specialized and context-dependent, reflecting the diversity of human interlocutors and their varied contexts. For example, "harm prevention" emerges when Claude resists users, "historical accuracy" when responding to queries about controversial events, "healthy boundaries" when asked for relationship advice, and "human agency" in technology ethics discussions. By providing the first large-scale empirical mapping of AI values in deployment, our work creates a foundation for more grounded evaluation and design of values in AI systems.