 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoLife: Towards Egocentric Life Assistant
Mar 05, 2025We introduce EgoLife, a project to develop an egocentric life assistant that accompanies and enhances personal efficiency through AI-powered wearable glasses. To lay the foundation for this assistant, we conducted a comprehensive data collection study where six participants lived together for one week, continuously recording their daily activities - including discussions, shopping, cooking, socializing, and entertainment - using AI glasses for multimodal egocentric video capture, along with synchronized third-person-view video references. This effort resulted in the EgoLife Dataset, a comprehensive 300-hour egocentric, interpersonal, multiview, and multimodal daily life dataset with intensive annotation. Leveraging this dataset, we introduce EgoLifeQA, a suite of long-context, life-oriented question-answering tasks designed to provide meaningful assistance in daily life by addressing practical questions such as recalling past relevant events, monitoring health habits, and offering personalized recommendations. To address the key technical challenges of (1) developing robust visual-audio models for egocentric data, (2) enabling identity recognition, and (3) facilitating long-context question answering over extensive temporal information, we introduce EgoButler, an integrated system comprising EgoGPT and EgoRAG. EgoGPT is an omni-modal model trained on egocentric datasets, achieving state-of-the-art performance on egocentric video understanding. EgoRAG is a retrieval-based component that supports answering ultra-long-context questions. Our experimental studies verify their working mechanisms and reveal critical factors and bottlenecks, guiding future improvements. By releasing our datasets, models, and benchmarks, we aim to stimulate further research in egocentric AI assistants.
DELTA: Dual Consistency Delving with Topological Uncertainty for Active Graph Domain Adaptation
Sep 13, 2024



Graph domain adaptation has recently enabled knowledge transfer across different graphs. However, without the semantic information on target graphs, the performance on target graphs is still far from satisfactory. To address the issue, we study the problem of active graph domain adaptation, which selects a small quantitative of informative nodes on the target graph for extra annotation. This problem is highly challenging due to the complicated topological relationships and the distribution discrepancy across graphs. In this paper, we propose a novel approach named Dual Consistency Delving with Topological Uncertainty (DELTA) for active graph domain adaptation. Our DELTA consists of an edge-oriented graph subnetwork and a path-oriented graph subnetwork, which can explore topological semantics from complementary perspectives. In particular, our edge-oriented graph subnetwork utilizes the message passing mechanism to learn neighborhood information, while our path-oriented graph subnetwork explores high-order relationships from substructures. To jointly learn from two subnetworks, we roughly select informative candidate nodes with the consideration of consistency across two subnetworks. Then, we aggregate local semantics from its K-hop subgraph based on node degrees for topological uncertainty estimation. To overcome potential distribution shifts, we compare target nodes and their corresponding source nodes for discrepancy scores as an additional component for fine selection. Extensive experiments on benchmark datasets demonstrate that DELTA outperforms various state-of-the-art approaches.
A Comprehensive Graph Pooling Benchmark: Effectiveness, Robustness and Generalizability
Jun 16, 2024



Graph pooling has gained attention for its ability to obtain effective node and graph representations for various downstream tasks. Despite the recent surge in graph pooling approaches, there is a lack of standardized experimental settings and fair benchmarks to evaluate their performance. To address this issue, we have constructed a comprehensive benchmark that includes 15 graph pooling methods and 21 different graph datasets. This benchmark systematically assesses the performance of graph pooling methods in three dimensions, i.e., effectiveness, robustness, and generalizability. We first evaluate the performance of these graph pooling approaches across different tasks including graph classification, graph regression and node classification. Then, we investigate their performance under potential noise attacks and out-of-distribution shifts in real-world scenarios. We also involve detailed efficiency analysis and parameter analysis. Extensive experiments validate the strong capability and applicability of graph pooling approaches in various scenarios, which can provide valuable insights and guidance for deep geometric learning research. The source code of our benchmark is available at https://github.com/goose315/Graph_Pooling_Benchmark.
OpenOOD v1.5: Enhanced Benchmark for Out-of-Distribution Detection
Jun 17, 2023Out-of-Distribution (OOD) detection is critical for the reliable operation of open-world intelligent systems. Despite the emergence of an increasing number of OOD detection methods, the evaluation inconsistencies present challenges for tracking the progress in this field. OpenOOD v1 initiated the unification of the OOD detection evaluation but faced limitations in scalability and usability. In response, this paper presents OpenOOD v1.5, a significant improvement from its predecessor that ensures accurate, standardized, and user-friendly evaluation of OOD detection methodologies. Notably, OpenOOD v1.5 extends its evaluation capabilities to large-scale datasets such as ImageNet, investigates full-spectrum OOD detection which is important yet underexplored, and introduces new features including an online leaderboard and an easy-to-use evaluator. This work also contributes in-depth analysis and insights derived from comprehensive experimental results, thereby enriching the knowledge pool of OOD detection methodologies. With these enhancements, OpenOOD v1.5 aims to drive advancements and offer a more robust and comprehensive evaluation benchmark for OOD detection research.
Generative Oversampling for Imbalanced Data via Majority-Guided VAE
Feb 14, 2023



Learning with imbalanced data is a challenging problem in deep learning. Over-sampling is a widely used technique to re-balance the sampling distribution of training data. However, most existing over-sampling methods only use intra-class information of minority classes to augment the data but ignore the inter-class relationships with the majority ones, which is prone to overfitting, especially when the imbalance ratio is large. To address this issue, we propose a novel over-sampling model, called Majority-Guided VAE~(MGVAE), which generates new minority samples under the guidance of a majority-based prior. In this way, the newly generated minority samples can inherit the diversity and richness of the majority ones, thus mitigating overfitting in downstream tasks. Furthermore, to prevent model collapse under limited data, we first pre-train MGVAE on sufficient majority samples and then fine-tune based on minority samples with Elastic Weight Consolidation(EWC) regularization. Experimental results on benchmark image datasets and real-world tabular data show that MGVAE achieves competitive improvements over other over-sampling methods in downstream classification tasks, demonstrating the effectiveness of our method.
Ti-MAE: Self-Supervised Masked Time Series Autoencoders
Jan 21, 2023



Multivariate Time Series forecasting has been an increasingly popular topic in various applications and scenarios. Recently, contrastive learning and Transformer-based models have achieved good performance in many long-term series forecasting tasks. However, there are still several issues in existing methods. First, the training paradigm of contrastive learning and downstream prediction tasks are inconsistent, leading to inaccurate prediction results. Second, existing Transformer-based models which resort to similar patterns in historical time series data for predicting future values generally induce severe distribution shift problems, and do not fully leverage the sequence information compared to self-supervised methods. To address these issues, we propose a novel framework named Ti-MAE, in which the input time series are assumed to follow an integrate distribution. In detail, Ti-MAE randomly masks out embedded time series data and learns an autoencoder to reconstruct them at the point-level. Ti-MAE adopts mask modeling (rather than contrastive learning) as the auxiliary task and bridges the connection between existing representation learning and generative Transformer-based methods, reducing the difference between upstream and downstream forecasting tasks while maintaining the utilization of original time series data. Experiments on several public real-world datasets demonstrate that our framework of masked autoencoding could learn strong representations directly from the raw data, yielding better performance in time series forecasting and classification tasks.
OpenOOD: Benchmarking Generalized Out-of-Distribution Detection
Oct 13, 2022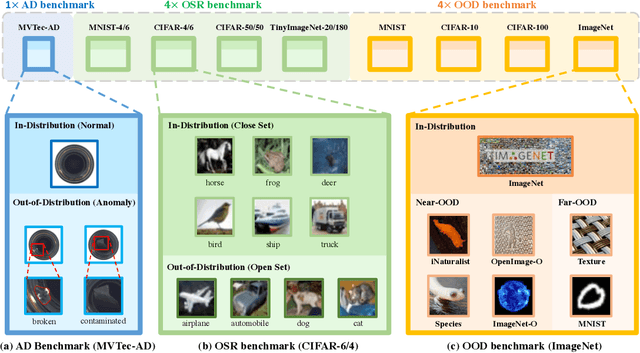
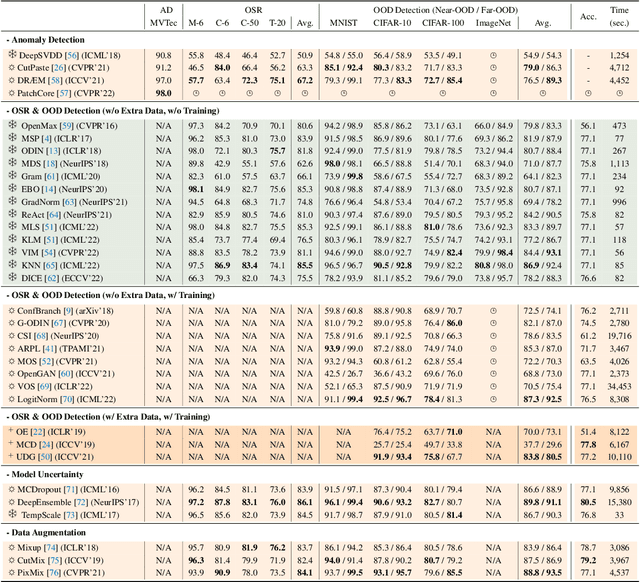
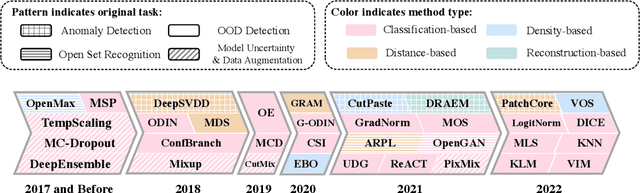
Out-of-distribution (OOD) detection is vital to safety-critical machine learning applications and has thus been extensively studied, with a plethora of methods developed in the literature. However, the field currently lacks a unified, strictly formulated, and comprehensive benchmark, which often results in unfair comparisons and inconclusive results. From the problem setting perspective, OOD detection is closely related to neighboring fields including anomaly detection (AD), open set recognition (OSR), and model uncertainty, since methods developed for one domain are often applicable to each other. To help the community to improve the evaluation and advance, we build a unified, well-structured codebase called OpenOOD, which implements over 30 methods developed in relevant fields and provides a comprehensive benchmark under the recently proposed generalized OOD detection framework. With a comprehensive comparison of these methods, we are gratified that the field has progressed significantly over the past few years, where both preprocessing methods and the orthogonal post-hoc methods show strong potential.
Multi-relation Message Passing for Multi-label Text Classification
Feb 10, 2022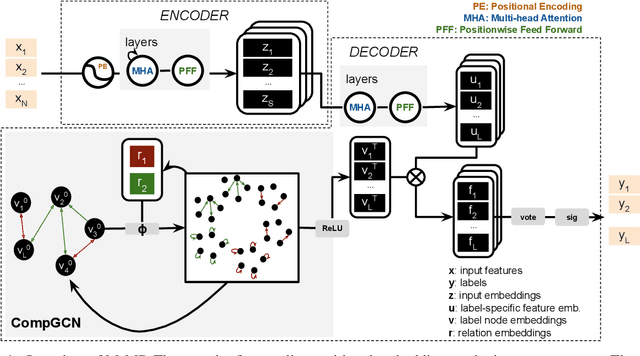

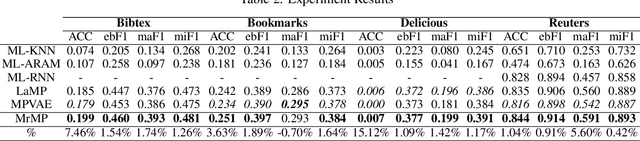
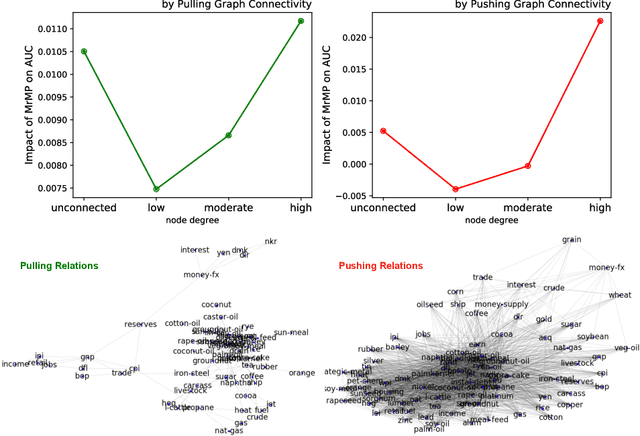
A well-known challenge associated with the multi-label classification problem is modelling dependencies between labels. Most attempts at modelling label dependencies focus on co-occurrences, ignoring the valuable information that can be extracted by detecting label subsets that rarely occur together. For example, consider customer product reviews; a product probably would not simultaneously be tagged by both "recommended" (i.e., reviewer is happy and recommends the product) and "urgent" (i.e., the review suggests immediate action to remedy an unsatisfactory experience). Aside from the consideration of positive and negative dependencies, the direction of a relationship should also be considered. For a multi-label image classification problem, the "ship" and "sea" labels have an obvious dependency, but the presence of the former implies the latter much more strongly than the other way around. These examples motivate the modelling of multiple types of bi-directional relationships between labels. In this paper, we propose a novel method, entitled Multi-relation Message Passing (MrMP), for the multi-label classification problem. Experiments on benchmark multi-label text classification datasets show that the MrMP module yields similar or superior performance compared to state-of-the-art methods. The approach imposes only minor additional computational and memory overheads.
Label-Aware Distribution Calibration for Long-tailed Classification
Nov 09, 2021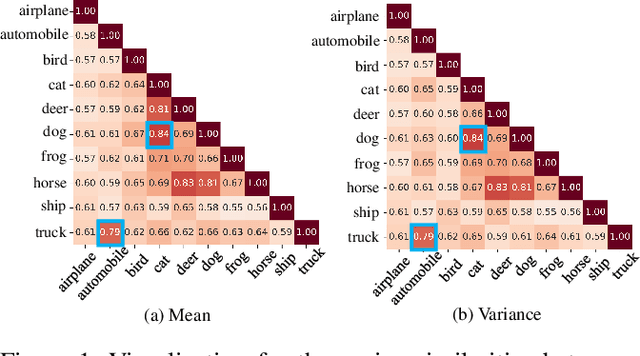

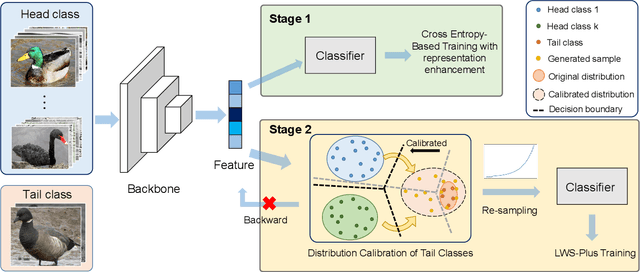
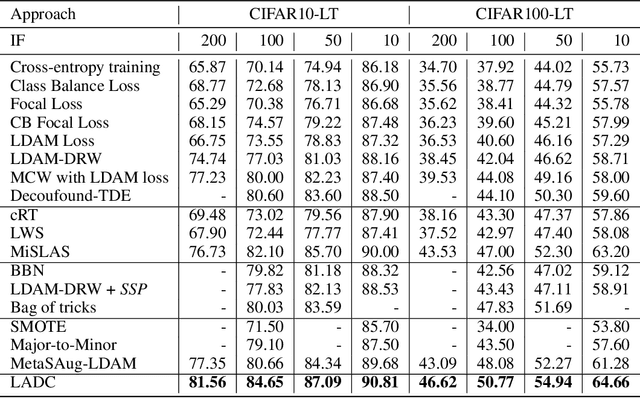
Real-world data usually present long-tailed distributions. Training on imbalanced data tends to render neural networks perform well on head classes while much worse on tail classes. The severe sparseness of training instances for the tail classes is the main challenge, which results in biased distribution estimation during training. Plenty of efforts have been devoted to ameliorating the challenge, including data re-sampling and synthesizing new training instances for tail classes. However, no prior research has exploited the transferable knowledge from head classes to tail classes for calibrating the distribution of tail classes. In this paper, we suppose that tail classes can be enriched by similar head classes and propose a novel distribution calibration approach named as label-Aware Distribution Calibration LADC. LADC transfers the statistics from relevant head classes to infer the distribution of tail classes. Sampling from calibrated distribution further facilitates re-balancing the classifier. Experiments on both image and text long-tailed datasets demonstrate that LADC significantly outperforms existing methods.The visualization also shows that LADC provides a more accurate distribution estimation.
Mask-GVAE: Blind Denoising Graphs via Partition
Feb 08, 2021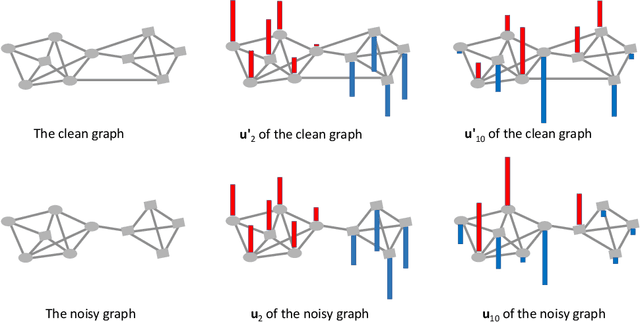
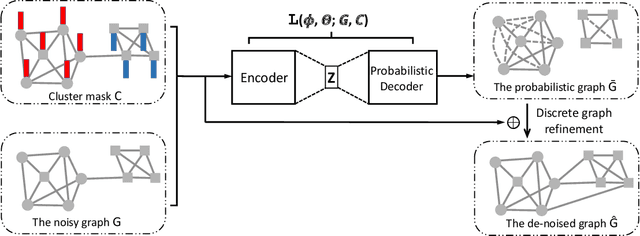
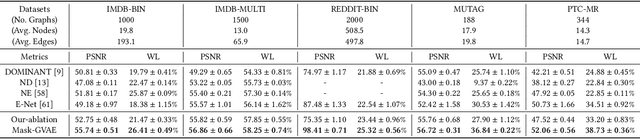
We present Mask-GVAE, a variational generative model for blind denoising large discrete graphs, in which "blind denoising" means we don't require any supervision from clean graphs. We focus on recovering graph structures via deleting irrelevant edges and adding missing edges, which has many applications in real-world scenarios, for example, enhancing the quality of connections in a co-authorship network. Mask-GVAE makes use of the robustness in low eigenvectors of graph Laplacian against random noise and decomposes the input graph into several stable clusters. It then harnesses the huge computations by decoding probabilistic smoothed subgraphs in a variational manner. On a wide variety of benchmarks, Mask-GVAE outperforms competing approaches by a significant margin on PSNR and WL similarity.