 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMindWatcher: Toward Smarter Multimodal Tool-Integrated Reasoning
Dec 29, 2025Traditional workflow-based agents exhibit limited intelligence when addressing real-world problems requiring tool invocation. Tool-integrated reasoning (TIR) agents capable of autonomous reasoning and tool invocation are rapidly emerging as a powerful approach for complex decision-making tasks involving multi-step interactions with external environments. In this work, we introduce MindWatcher, a TIR agent integrating interleaved thinking and multimodal chain-of-thought (CoT) reasoning. MindWatcher can autonomously decide whether and how to invoke diverse tools and coordinate their use, without relying on human prompts or workflows. The interleaved thinking paradigm enables the model to switch between thinking and tool calling at any intermediate stage, while its multimodal CoT capability allows manipulation of images during reasoning to yield more precise search results. We implement automated data auditing and evaluation pipelines, complemented by manually curated high-quality datasets for training, and we construct a benchmark, called MindWatcher-Evaluate Bench (MWE-Bench), to evaluate its performance. MindWatcher is equipped with a comprehensive suite of auxiliary reasoning tools, enabling it to address broad-domain multimodal problems. A large-scale, high-quality local image retrieval database, covering eight categories including cars, animals, and plants, endows model with robust object recognition despite its small size. Finally, we design a more efficient training infrastructure for MindWatcher, enhancing training speed and hardware utilization. Experiments not only demonstrate that MindWatcher matches or exceeds the performance of larger or more recent models through superior tool invocation, but also uncover critical insights for agent training, such as the genetic inheritance phenomenon in agentic RL.
Do Language Models Have Bayesian Brains? Distinguishing Stochastic and Deterministic Decision Patterns within Large Language Models
Jun 12, 2025Language models are essentially probability distributions over token sequences. Auto-regressive models generate sentences by iteratively computing and sampling from the distribution of the next token. This iterative sampling introduces stochasticity, leading to the assumption that language models make probabilistic decisions, similar to sampling from unknown distributions. Building on this assumption, prior research has used simulated Gibbs sampling, inspired by experiments designed to elicit human priors, to infer the priors of language models. In this paper, we revisit a critical question: Do language models possess Bayesian brains? Our findings show that under certain conditions, language models can exhibit near-deterministic decision-making, such as producing maximum likelihood estimations, even with a non-zero sampling temperature. This challenges the sampling assumption and undermines previous methods for eliciting human-like priors. Furthermore, we demonstrate that without proper scrutiny, a system with deterministic behavior undergoing simulated Gibbs sampling can converge to a "false prior." To address this, we propose a straightforward approach to distinguish between stochastic and deterministic decision patterns in Gibbs sampling, helping to prevent the inference of misleading language model priors. We experiment on a variety of large language models to identify their decision patterns under various circumstances. Our results provide key insights in understanding decision making of large language models.
Ordered-subsets Multi-diffusion Model for Sparse-view CT Reconstruction
May 15, 2025Score-based diffusion models have shown significant promise in the field of sparse-view CT reconstruction. However, the projection dataset is large and riddled with redundancy. Consequently, applying the diffusion model to unprocessed data results in lower learning effectiveness and higher learning difficulty, frequently leading to reconstructed images that lack fine details. To address these issues, we propose the ordered-subsets multi-diffusion model (OSMM) for sparse-view CT reconstruction. The OSMM innovatively divides the CT projection data into equal subsets and employs multi-subsets diffusion model (MSDM) to learn from each subset independently. This targeted learning approach reduces complexity and enhances the reconstruction of fine details. Furthermore, the integration of one-whole diffusion model (OWDM) with complete sinogram data acts as a global information constraint, which can reduce the possibility of generating erroneous or inconsistent sinogram information. Moreover, the OSMM's unsupervised learning framework provides strong robustness and generalizability, adapting seamlessly to varying sparsity levels of CT sinograms. This ensures consistent and reliable performance across different clinical scenarios. Experimental results demonstrate that OSMM outperforms traditional diffusion models in terms of image quality and noise resilience, offering a powerful and versatile solution for advanced CT imaging in sparse-view scenarios.
LDGen: Enhancing Text-to-Image Synthesis via Large Language Model-Driven Language Representation
Feb 25, 2025



In this paper, we introduce LDGen, a novel method for integrating large language models (LLMs) into existing text-to-image diffusion models while minimizing computational demands. Traditional text encoders, such as CLIP and T5, exhibit limitations in multilingual processing, hindering image generation across diverse languages. We address these challenges by leveraging the advanced capabilities of LLMs. Our approach employs a language representation strategy that applies hierarchical caption optimization and human instruction techniques to derive precise semantic information,. Subsequently, we incorporate a lightweight adapter and a cross-modal refiner to facilitate efficient feature alignment and interaction between LLMs and image features. LDGen reduces training time and enables zero-shot multilingual image generation. Experimental results indicate that our method surpasses baseline models in both prompt adherence and image aesthetic quality, while seamlessly supporting multiple languages. Project page: https://zrealli.github.io/LDGen.
The Law of Knowledge Overshadowing: Towards Understanding, Predicting, and Preventing LLM Hallucination
Feb 22, 2025



Hallucination is a persistent challenge in large language models (LLMs), where even with rigorous quality control, models often generate distorted facts. This paradox, in which error generation continues despite high-quality training data, calls for a deeper understanding of the underlying LLM mechanisms. To address it, we propose a novel concept: knowledge overshadowing, where model's dominant knowledge can obscure less prominent knowledge during text generation, causing the model to fabricate inaccurate details. Building on this idea, we introduce a novel framework to quantify factual hallucinations by modeling knowledge overshadowing. Central to our approach is the log-linear law, which predicts that the rate of factual hallucination increases linearly with the logarithmic scale of (1) Knowledge Popularity, (2) Knowledge Length, and (3) Model Size. The law provides a means to preemptively quantify hallucinations, offering foresight into their occurrence even before model training or inference. Built on overshadowing effect, we propose a new decoding strategy CoDa, to mitigate hallucinations, which notably enhance model factuality on Overshadow (27.9%), MemoTrap (13.1%) and NQ-Swap (18.3%). Our findings not only deepen understandings of the underlying mechanisms behind hallucinations but also provide actionable insights for developing more predictable and controllable language models.
Gene-Metabolite Association Prediction with Interactive Knowledge Transfer Enhanced Graph for Metabolite Production
Oct 24, 2024



In the rapidly evolving field of metabolic engineering, the quest for efficient and precise gene target identification for metabolite production enhancement presents significant challenges. Traditional approaches, whether knowledge-based or model-based, are notably time-consuming and labor-intensive, due to the vast scale of research literature and the approximation nature of genome-scale metabolic model (GEM) simulations. Therefore, we propose a new task, Gene-Metabolite Association Prediction based on metabolic graphs, to automate the process of candidate gene discovery for a given pair of metabolite and candidate-associated genes, as well as presenting the first benchmark containing 2474 metabolites and 1947 genes of two commonly used microorganisms Saccharomyces cerevisiae (SC) and Issatchenkia orientalis (IO). This task is challenging due to the incompleteness of the metabolic graphs and the heterogeneity among distinct metabolisms. To overcome these limitations, we propose an Interactive Knowledge Transfer mechanism based on Metabolism Graph (IKT4Meta), which improves the association prediction accuracy by integrating the knowledge from different metabolism graphs. First, to build a bridge between two graphs for knowledge transfer, we utilize Pretrained Language Models (PLMs) with external knowledge of genes and metabolites to help generate inter-graph links, significantly alleviating the impact of heterogeneity. Second, we propagate intra-graph links from different metabolic graphs using inter-graph links as anchors. Finally, we conduct the gene-metabolite association prediction based on the enriched metabolism graphs, which integrate the knowledge from multiple microorganisms. Experiments on both types of organisms demonstrate that our proposed methodology outperforms baselines by up to 12.3% across various link prediction frameworks.
Knowledge Overshadowing Causes Amalgamated Hallucination in Large Language Models
Jul 10, 2024Hallucination is often regarded as a major impediment for using large language models (LLMs), especially for knowledge-intensive tasks. Even when the training corpus consists solely of true statements, language models still generate hallucinations in the form of amalgamations of multiple facts. We coin this phenomenon as ``knowledge overshadowing'': when we query knowledge from a language model with multiple conditions, some conditions overshadow others, leading to hallucinated outputs. This phenomenon partially stems from training data imbalance, which we verify on both pretrained models and fine-tuned models, over a wide range of LM model families and sizes.From a theoretical point of view, knowledge overshadowing can be interpreted as over-generalization of the dominant conditions (patterns). We show that the hallucination rate grows with both the imbalance ratio (between the popular and unpopular condition) and the length of dominant condition description, consistent with our derived generalization bound. Finally, we propose to utilize overshadowing conditions as a signal to catch hallucination before it is produced, along with a training-free self-contrastive decoding method to alleviate hallucination during inference. Our proposed approach showcases up to 82% F1 for hallucination anticipation and 11.2% to 39.4% hallucination control, with different models and datasets.
EVEDIT: Event-based Knowledge Editing with Deductive Editing Boundaries
Feb 17, 2024
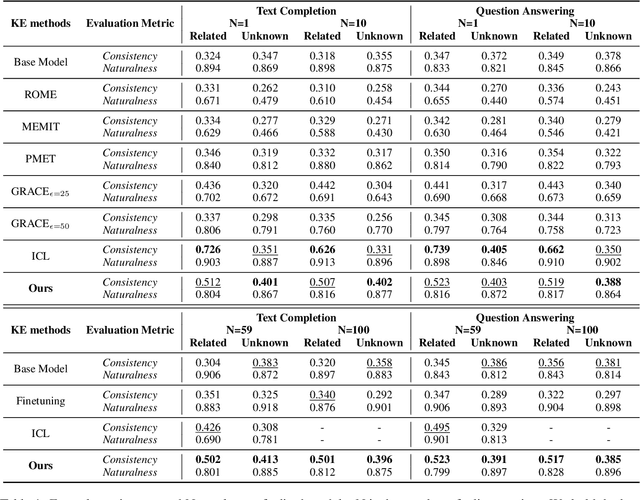
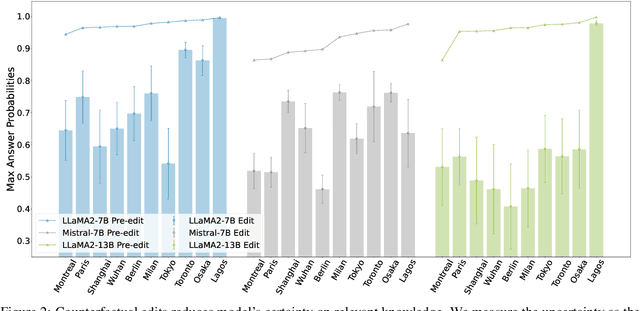

The dynamic nature of real-world information necessitates efficient knowledge editing (KE) in large language models (LLMs) for knowledge updating. However, current KE approaches, which typically operate on (subject, relation, object) triples, ignore the contextual information and the relation among different knowledge. Such editing methods could thus encounter an uncertain editing boundary, leaving a lot of relevant knowledge in ambiguity: Queries that could be answered pre-edit cannot be reliably answered afterward. In this work, we analyze this issue by introducing a theoretical framework for KE that highlights an overlooked set of knowledge that remains unchanged and aids in knowledge deduction during editing, which we name as the deduction anchor. We further address this issue by proposing a novel task of event-based knowledge editing that pairs facts with event descriptions. This task manifests not only a closer simulation of real-world editing scenarios but also a more logically sound setting, implicitly defining the deduction anchor to address the issue of indeterminate editing boundaries. We empirically demonstrate the superiority of event-based editing over the existing setting on resolving uncertainty in edited models, and curate a new benchmark dataset EvEdit derived from the CounterFact dataset. Moreover, while we observe that the event-based setting is significantly challenging for existing approaches, we propose a novel approach Self-Edit that showcases stronger performance, achieving 55.6% consistency improvement while maintaining the naturalness of generation.
MuChin: A Chinese Colloquial Description Benchmark for Evaluating Language Models in the Field of Music
Feb 15, 2024



The rapidly evolving multimodal Large Language Models (LLMs) urgently require new benchmarks to uniformly evaluate their performance on understanding and textually describing music. However, due to semantic gaps between Music Information Retrieval (MIR) algorithms and human understanding, discrepancies between professionals and the public, and low precision of annotations, existing music description datasets cannot serve as benchmarks. To this end, we present MuChin, the first open-source music description benchmark in Chinese colloquial language, designed to evaluate the performance of multimodal LLMs in understanding and describing music. We established the Caichong Music Annotation Platform (CaiMAP) that employs an innovative multi-person, multi-stage assurance method, and recruited both amateurs and professionals to ensure the precision of annotations and alignment with popular semantics. Utilizing this method, we built a dataset with multi-dimensional, high-precision music annotations, the Caichong Music Dataset (CaiMD), and carefully selected 1,000 high-quality entries to serve as the test set for MuChin. Based on MuChin, we analyzed the discrepancies between professionals and amateurs in terms of music description, and empirically demonstrated the effectiveness of annotated data for fine-tuning LLMs. Ultimately, we employed MuChin to evaluate existing music understanding models on their ability to provide colloquial descriptions of music. All data related to the benchmark and the code for scoring have been open-sourced.
PET Tracer Conversion among Brain PET via Variable Augmented Invertible Network
Nov 15, 2023



Positron emission tomography (PET) serves as an essential tool for diagnosis of encephalopathy and brain science research. However, it suffers from the limited choice of tracers. Nowadays, with the wide application of PET imaging in neuropsychiatric treatment, 6-18F-fluoro-3, 4-dihydroxy-L-phenylalanine (DOPA) has been found to be more effective than 18F-labeled fluorine-2-deoxyglucose (FDG) in the field. Nevertheless, due to the complexity of its preparation and other limitations, DOPA is far less widely used than FDG. To address this issue, a tracer conversion invertible neural network (TC-INN) for image projection is developed to map FDG images to DOPA images through deep learning. More diagnostic information is obtained by generating PET images from FDG to DOPA. Specifically, the proposed TC-INN consists of two separate phases, one for training traceable data, the other for rebuilding new data. The reference DOPA PET image is used as a learning target for the corresponding network during the training process of tracer conversion. Meanwhile, the invertible network iteratively estimates the resultant DOPA PET data and compares it to the reference DOPA PET data. Notably, the reversible model employs variable enhancement technique to achieve better power generation. Moreover, image registration needs to be performed before training due to the angular deviation of the acquired FDG and DOPA data information. Experimental results exhibited excellent generation capability in mapping between FDG and DOPA, suggesting that PET tracer conversion has great potential in the case of limited tracer applications.