 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBinding Language Models in Symbolic Languages
Oct 06, 2022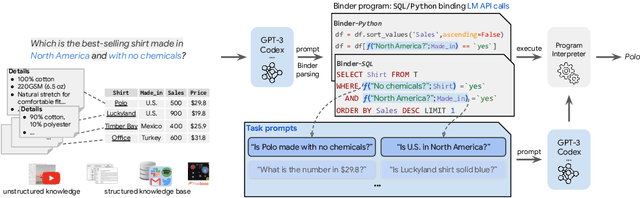
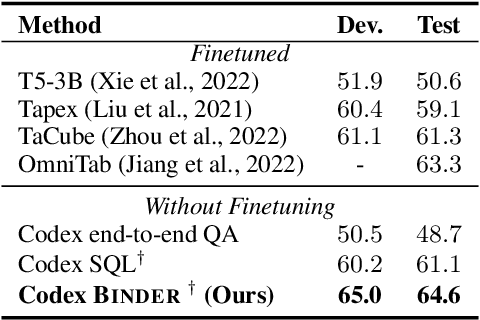

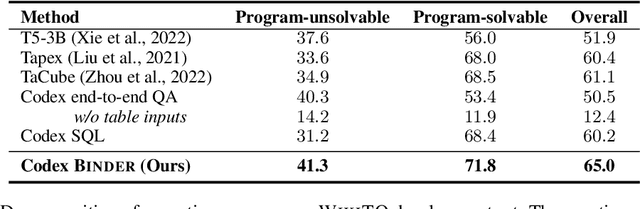
Though end-to-end neural approaches have recently been dominating NLP tasks in both performance and ease-of-use, they lack interpretability and robustness. We propose Binder, a training-free neural-symbolic framework that maps the task input to a program, which (1) allows binding a unified API of language model (LM) functionalities to a programming language (e.g., SQL, Python) to extend its grammar coverage and thus tackle more diverse questions, (2) adopts an LM as both the program parser and the underlying model called by the API during execution, and (3) requires only a few in-context exemplar annotations. Specifically, we employ GPT-3 Codex as the LM. In the parsing stage, with only a few in-context exemplars, Codex is able to identify the part of the task input that cannot be answerable by the original programming language, correctly generate API calls to prompt Codex to solve the unanswerable part, and identify where to place the API calls while being compatible with the original grammar. In the execution stage, Codex can perform versatile functionalities (e.g., commonsense QA, information extraction) given proper prompts in the API calls. Binder achieves state-of-the-art results on WikiTableQuestions and TabFact datasets, with explicit output programs that benefit human debugging. Note that previous best systems are all finetuned on tens of thousands of task-specific samples, while Binder only uses dozens of annotations as in-context exemplars without any training. Our code is available at https://github.com/HKUNLP/Binder .
Better Language Model with Hypernym Class Prediction
Mar 21, 2022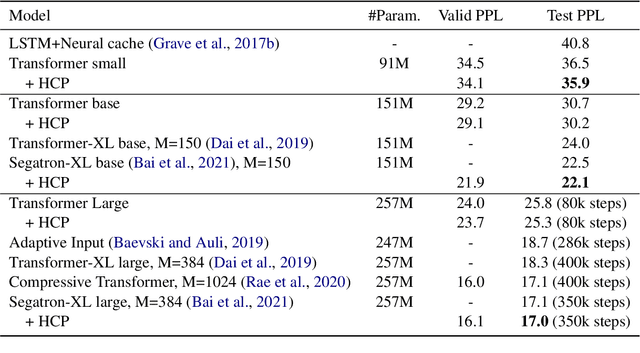
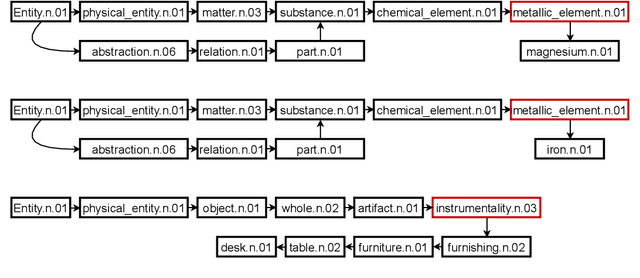
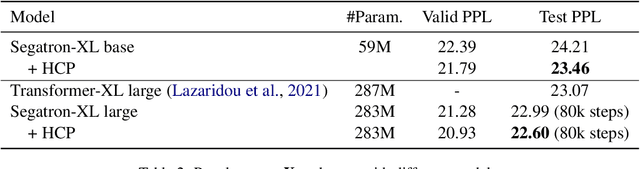
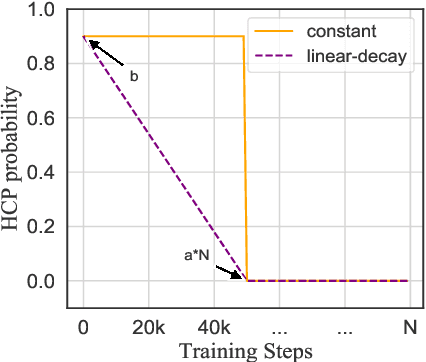
Class-based language models (LMs) have been long devised to address context sparsity in $n$-gram LMs. In this study, we revisit this approach in the context of neural LMs. We hypothesize that class-based prediction leads to an implicit context aggregation for similar words and thus can improve generalization for rare words. We map words that have a common WordNet hypernym to the same class and train large neural LMs by gradually annealing from predicting the class to token prediction during training. Empirically, this curriculum learning strategy consistently improves perplexity over various large, highly-performant state-of-the-art Transformer-based models on two datasets, WikiText-103 and Arxiv. Our analysis shows that the performance improvement is achieved without sacrificing performance on rare words. Finally, we document other attempts that failed to yield empirical gains, and discuss future directions for the adoption of class-based LMs on a larger scale.
UnifiedSKG: Unifying and Multi-Tasking Structured Knowledge Grounding with Text-to-Text Language Models
Jan 20, 2022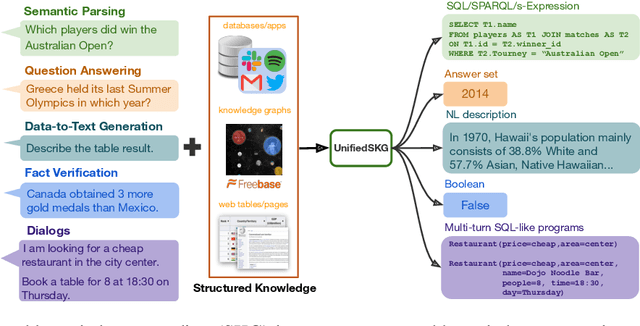
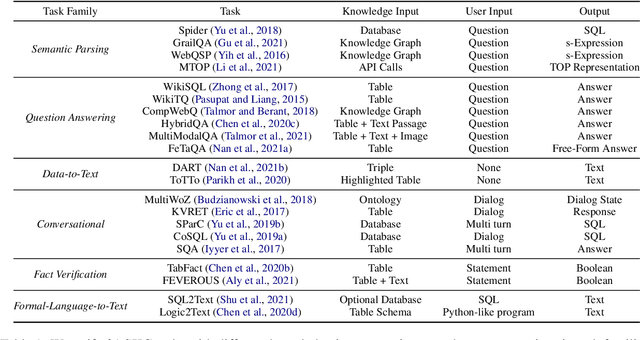
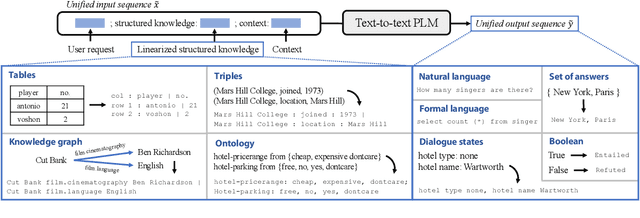
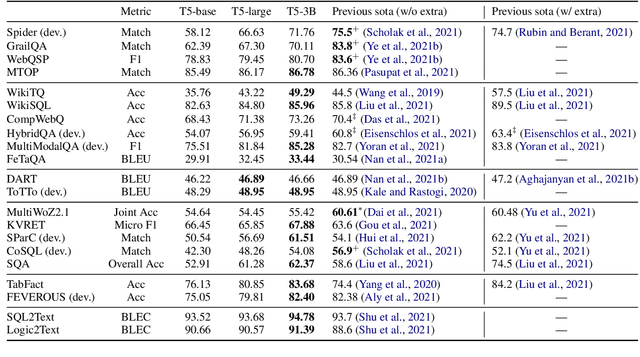
Structured knowledge grounding (SKG) leverages structured knowledge to complete user requests, such as semantic parsing over databases and question answering over knowledge bases. Since the inputs and outputs of SKG tasks are heterogeneous, they have been studied separately by different communities, which limits systematic and compatible research on SKG. In this paper, we overcome this limitation by proposing the SKG framework, which unifies 21 SKG tasks into a text-to-text format, aiming to promote systematic SKG research, instead of being exclusive to a single task, domain, or dataset. We use UnifiedSKG to benchmark T5 with different sizes and show that T5, with simple modifications when necessary, achieves state-of-the-art performance on almost all of the 21 tasks. We further demonstrate that multi-task prefix-tuning improves the performance on most tasks, largely improving the overall performance. UnifiedSKG also facilitates the investigation of zero-shot and few-shot learning, and we show that T0, GPT-3, and Codex struggle in zero-shot and few-shot learning for SKG. We also use UnifiedSKG to conduct a series of controlled experiments on structured knowledge encoding variants across SKG tasks. UnifiedSKG is easily extensible to more tasks, and it is open-sourced at https://github.com/hkunlp/unifiedskg Latest collections at https://unifiedskg.com.
Prefix-to-SQL: Text-to-SQL Generation from Incomplete User Questions
Sep 30, 2021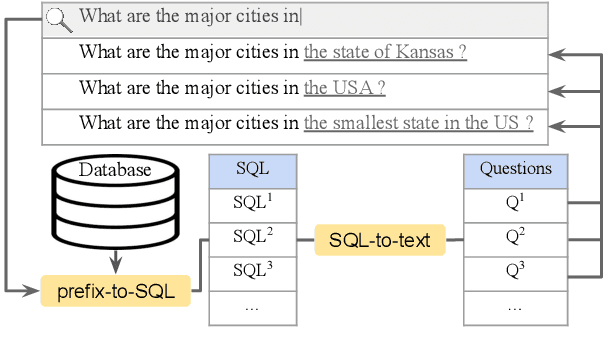

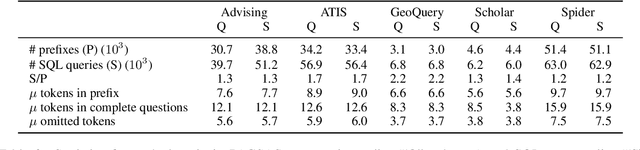
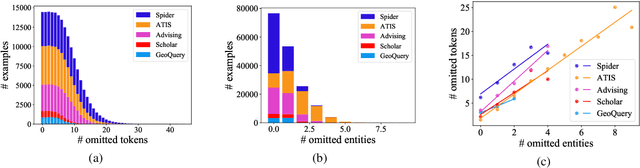
Existing text-to-SQL research only considers complete questions as the input, but lay-users might strive to formulate a complete question. To build a smarter natural language interface to database systems (NLIDB) that also processes incomplete questions, we propose a new task, prefix-to-SQL which takes question prefix from users as the input and predicts the intended SQL. We construct a new benchmark called PAGSAS that contains 124K user question prefixes and the intended SQL for 5 sub-tasks Advising, GeoQuery, Scholar, ATIS, and Spider. Additionally, we propose a new metric SAVE to measure how much effort can be saved by users. Experimental results show that PAGSAS is challenging even for strong baseline models such as T5. As we observe the difficulty of prefix-to-SQL is related to the number of omitted tokens, we incorporate curriculum learning of feeding examples with an increasing number of omitted tokens. This improves scores on various sub-tasks by as much as 9% recall scores on sub-task GeoQuery in PAGSAS.
Hierarchical Character Tagger for Short Text Spelling Error Correction
Sep 29, 2021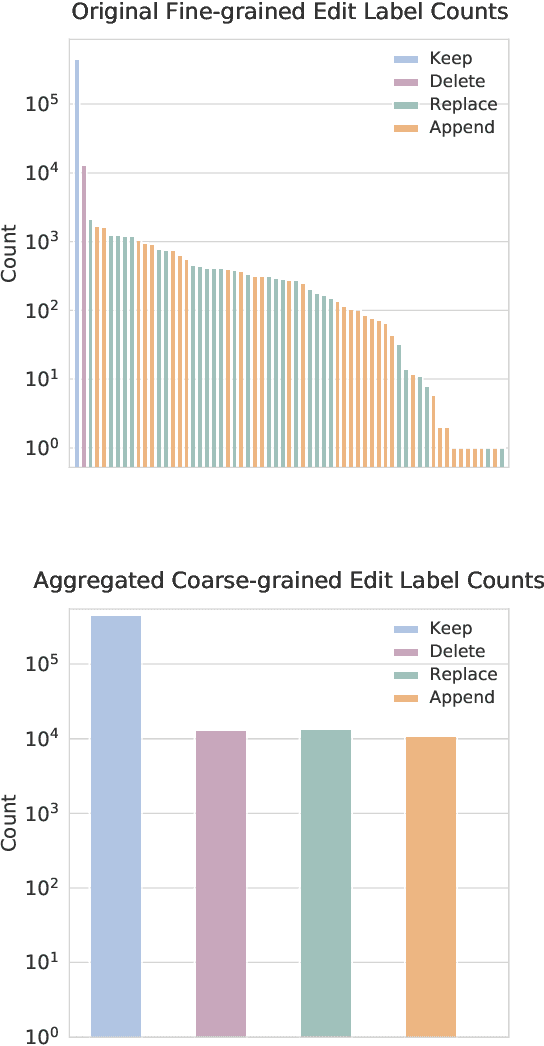

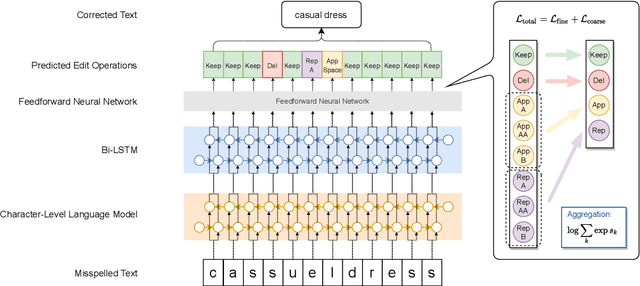
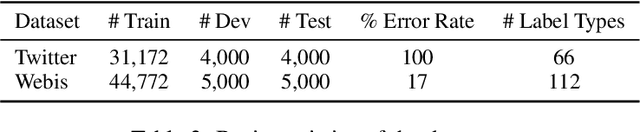
State-of-the-art approaches to spelling error correction problem include Transformer-based Seq2Seq models, which require large training sets and suffer from slow inference time; and sequence labeling models based on Transformer encoders like BERT, which involve token-level label space and therefore a large pre-defined vocabulary dictionary. In this paper we present a Hierarchical Character Tagger model, or HCTagger, for short text spelling error correction. We use a pre-trained language model at the character level as a text encoder, and then predict character-level edits to transform the original text into its error-free form with a much smaller label space. For decoding, we propose a hierarchical multi-task approach to alleviate the issue of long-tail label distribution without introducing extra model parameters. Experiments on two public misspelling correction datasets demonstrate that HCTagger is an accurate and much faster approach than many existing models.
Cross-Lingual Training with Dense Retrieval for Document Retrieval
Sep 03, 2021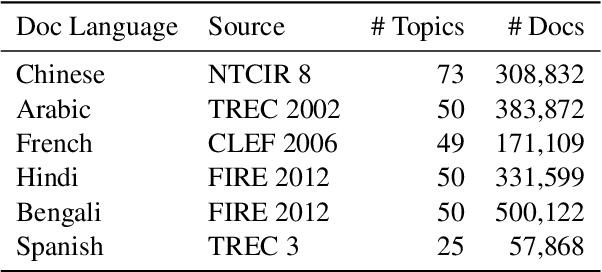
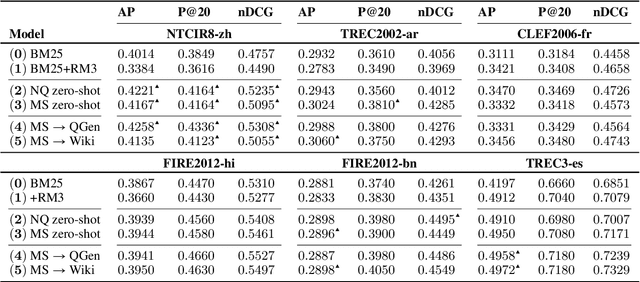
Dense retrieval has shown great success in passage ranking in English. However, its effectiveness in document retrieval for non-English languages remains unexplored due to the limitation in training resources. In this work, we explore different transfer techniques for document ranking from English annotations to multiple non-English languages. Our experiments on the test collections in six languages (Chinese, Arabic, French, Hindi, Bengali, Spanish) from diverse language families reveal that zero-shot model-based transfer using mBERT improves the search quality in non-English mono-lingual retrieval. Also, we find that weakly-supervised target language transfer yields competitive performances against the generation-based target language transfer that requires external translators and query generators.
Mr. TyDi: A Multi-lingual Benchmark for Dense Retrieval
Aug 19, 2021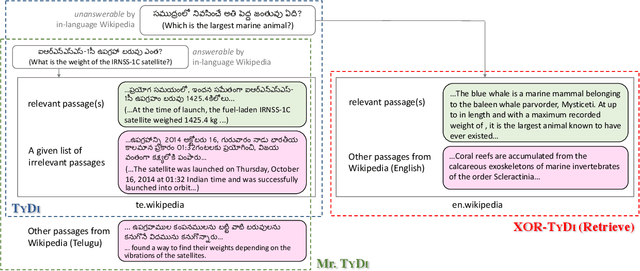
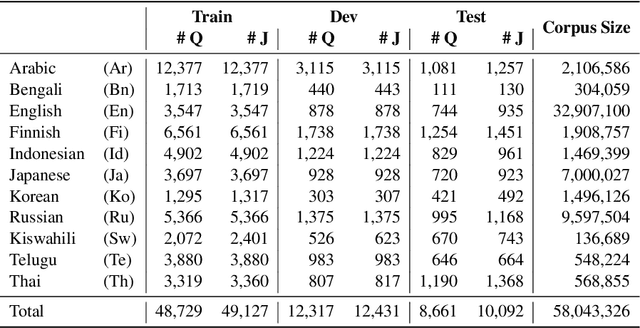
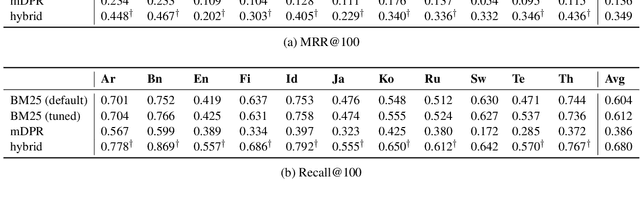
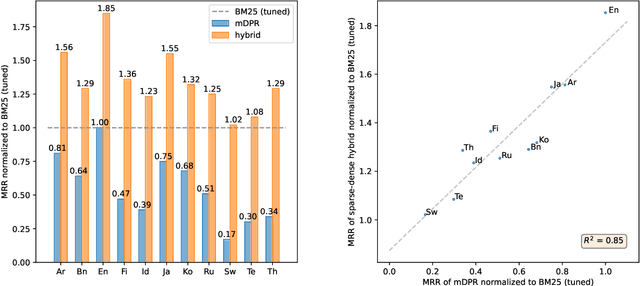
We present Mr. TyDi, a multi-lingual benchmark dataset for mono-lingual retrieval in eleven typologically diverse languages, designed to evaluate ranking with learned dense representations. The goal of this resource is to spur research in dense retrieval techniques in non-English languages, motivated by recent observations that existing techniques for representation learning perform poorly when applied to out-of-distribution data. As a starting point, we provide zero-shot baselines for this new dataset based on a multi-lingual adaptation of DPR that we call "mDPR". Experiments show that although the effectiveness of mDPR is much lower than BM25, dense representations nevertheless appear to provide valuable relevance signals, improving BM25 results in sparse-dense hybrids. In addition to analyses of our results, we also discuss future challenges and present a research agenda in multi-lingual dense retrieval. Mr. TyDi can be downloaded at https://github.com/castorini/mr.tydi.
Logic-Consistency Text Generation from Semantic Parses
Aug 02, 2021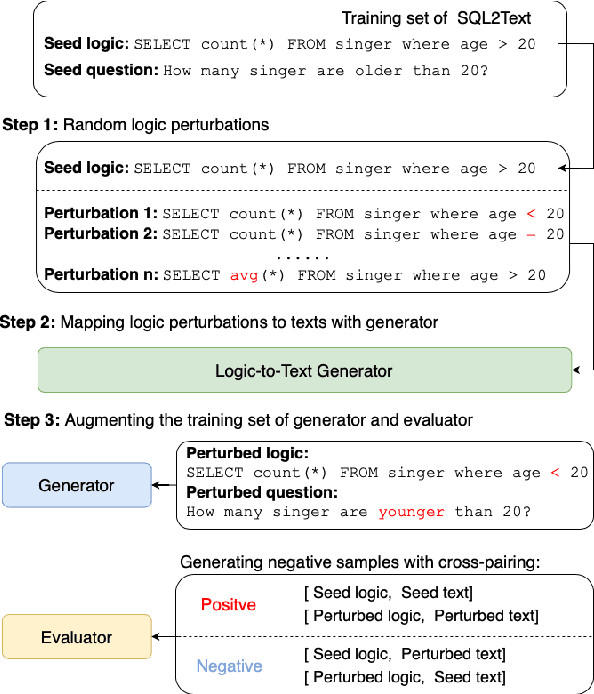
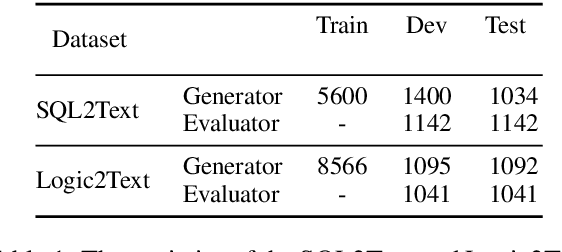

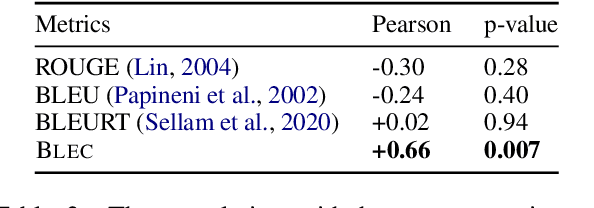
Text generation from semantic parses is to generate textual descriptions for formal representation inputs such as logic forms and SQL queries. This is challenging due to two reasons: (1) the complex and intensive inner logic with the data scarcity constraint, (2) the lack of automatic evaluation metrics for logic consistency. To address these two challenges, this paper first proposes SNOWBALL, a framework for logic consistent text generation from semantic parses that employs an iterative training procedure by recursively augmenting the training set with quality control. Second, we propose a novel automatic metric, BLEC, for evaluating the logical consistency between the semantic parses and generated texts. The experimental results on two benchmark datasets, Logic2Text and Spider, demonstrate the SNOWBALL framework enhances the logic consistency on both BLEC and human evaluation. Furthermore, our statistical analysis reveals that BLEC is more logically consistent with human evaluation than general-purpose automatic metrics including BLEU, ROUGE and, BLEURT. Our data and code are available at https://github.com/Ciaranshu/relogic.
End-to-End Cross-Domain Text-to-SQL Semantic Parsing with Auxiliary Task
Jun 17, 2021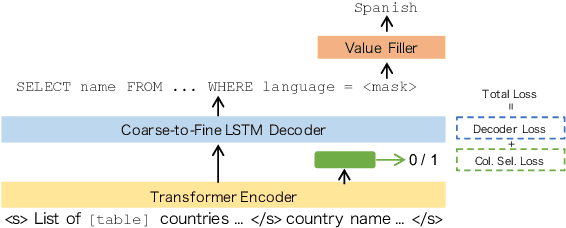

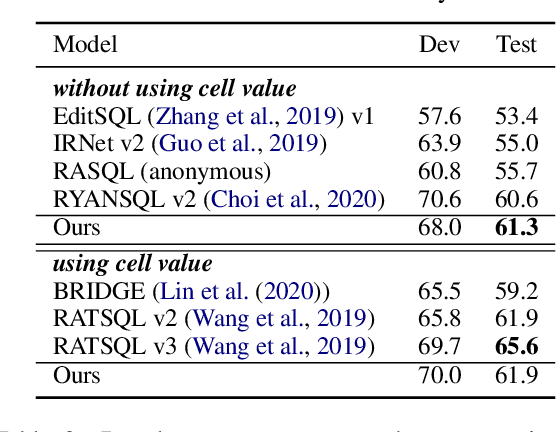
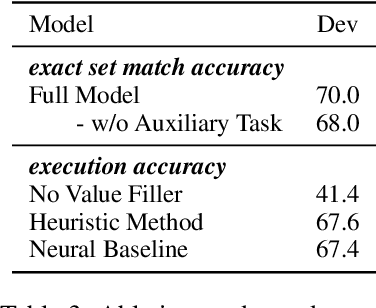
In this work, we focus on two crucial components in the cross-domain text-to-SQL semantic parsing task: schema linking and value filling. To encourage the model to learn better encoding ability, we propose a column selection auxiliary task to empower the encoder with the relevance matching capability by using explicit learning targets. Furthermore, we propose two value filling methods to build the bridge from the existing zero-shot semantic parsers to real-world applications, considering most of the existing parsers ignore the values filling in the synthesized SQL. With experiments on Spider, our proposed framework improves over the baselines on the execution accuracy and exact set match accuracy when database contents are unavailable, and detailed analysis sheds light on future work.
Learning Contextual Representations for Semantic Parsing with Generation-Augmented Pre-Training
Dec 18, 2020
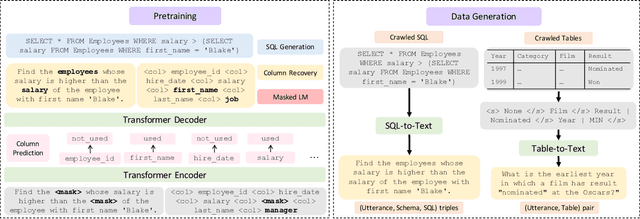
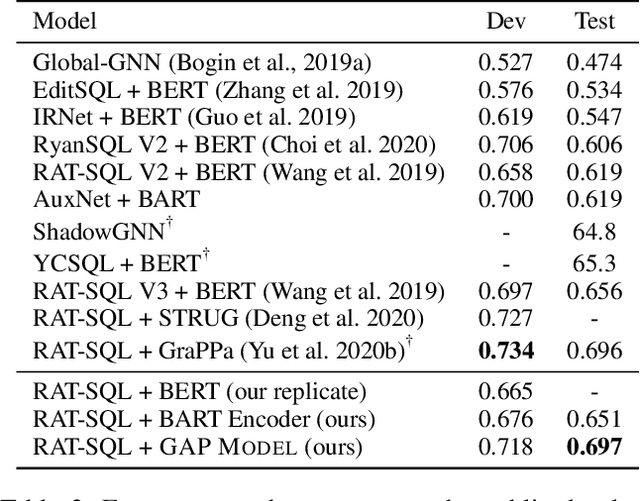
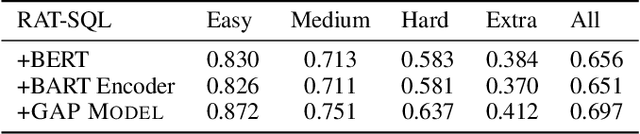
Most recently, there has been significant interest in learning contextual representations for various NLP tasks, by leveraging large scale text corpora to train large neural language models with self-supervised learning objectives, such as Masked Language Model (MLM). However, based on a pilot study, we observe three issues of existing general-purpose language models when they are applied to text-to-SQL semantic parsers: fail to detect column mentions in the utterances, fail to infer column mentions from cell values, and fail to compose complex SQL queries. To mitigate these issues, we present a model pre-training framework, Generation-Augmented Pre-training (GAP), that jointly learns representations of natural language utterances and table schemas by leveraging generation models to generate pre-train data. GAP MODEL is trained on 2M utterance-schema pairs and 30K utterance-schema-SQL triples, whose utterances are produced by generative models. Based on experimental results, neural semantic parsers that leverage GAP MODEL as a representation encoder obtain new state-of-the-art results on both SPIDER and CRITERIA-TO-SQL benchmarks.