 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Modality Gaps in e-Commerce Products via Vision-Language Alignment
Aug 13, 2025Item information, such as titles and attributes, is essential for effective user engagement in e-commerce. However, manual or semi-manual entry of structured item specifics often produces inconsistent quality, errors, and slow turnaround, especially for Customer-to-Customer sellers. Generating accurate descriptions directly from item images offers a promising alternative. Existing retrieval-based solutions address some of these issues but often miss fine-grained visual details and struggle with niche or specialized categories. We propose Optimized Preference-Based AI for Listings (OPAL), a framework for generating schema-compliant, high-quality item descriptions from images using a fine-tuned multimodal large language model (MLLM). OPAL addresses key challenges in multimodal e-commerce applications, including bridging modality gaps and capturing detailed contextual information. It introduces two data refinement methods: MLLM-Assisted Conformity Enhancement, which ensures alignment with structured schema requirements, and LLM-Assisted Contextual Understanding, which improves the capture of nuanced and fine-grained information from visual inputs. OPAL uses visual instruction tuning combined with direct preference optimization to fine-tune the MLLM, reducing hallucinations and improving robustness across different backbone architectures. We evaluate OPAL on real-world e-commerce datasets, showing that it consistently outperforms baseline methods in both description quality and schema completion rates. These results demonstrate that OPAL effectively bridges the gap between visual and textual modalities, delivering richer, more accurate, and more consistent item descriptions. This work advances automated listing optimization and supports scalable, high-quality content generation in e-commerce platforms.
Investigating LLM Applications in E-Commerce
Aug 23, 2024



The emergence of Large Language Models (LLMs) has revolutionized natural language processing in various applications especially in e-commerce. One crucial step before the application of such LLMs in these fields is to understand and compare the performance in different use cases in such tasks. This paper explored the efficacy of LLMs in the e-commerce domain, focusing on instruction-tuning an open source LLM model with public e-commerce datasets of varying sizes and comparing the performance with the conventional models prevalent in industrial applications. We conducted a comprehensive comparison between LLMs and traditional pre-trained language models across specific tasks intrinsic to the e-commerce domain, namely classification, generation, summarization, and named entity recognition (NER). Furthermore, we examined the effectiveness of the current niche industrial application of very large LLM, using in-context learning, in e-commerce specific tasks. Our findings indicate that few-shot inference with very large LLMs often does not outperform fine-tuning smaller pre-trained models, underscoring the importance of task-specific model optimization.Additionally, we investigated different training methodologies such as single-task training, mixed-task training, and LoRA merging both within domain/tasks and between different tasks. Through rigorous experimentation and analysis, this paper offers valuable insights into the potential effectiveness of LLMs to advance natural language processing capabilities within the e-commerce industry.
CCPrompt: Counterfactual Contrastive Prompt-Tuning for Many-Class Classification
Nov 11, 2022



With the success of the prompt-tuning paradigm in Natural Language Processing (NLP), various prompt templates have been proposed to further stimulate specific knowledge for serving downstream tasks, e.g., machine translation, text generation, relation extraction, and so on. Existing prompt templates are mainly shared among all training samples with the information of task description. However, training samples are quite diverse. The sharing task description is unable to stimulate the unique task-related information in each training sample, especially for tasks with the finite-label space. To exploit the unique task-related information, we imitate the human decision process which aims to find the contrastive attributes between the objective factual and their potential counterfactuals. Thus, we propose the \textbf{C}ounterfactual \textbf{C}ontrastive \textbf{Prompt}-Tuning (CCPrompt) approach for many-class classification, e.g., relation classification, topic classification, and entity typing. Compared with simple classification tasks, these tasks have more complex finite-label spaces and are more rigorous for prompts. First of all, we prune the finite label space to construct fact-counterfactual pairs. Then, we exploit the contrastive attributes by projecting training instances onto every fact-counterfactual pair. We further set up global prototypes corresponding with all contrastive attributes for selecting valid contrastive attributes as additional tokens in the prompt template. Finally, a simple Siamese representation learning is employed to enhance the robustness of the model. We conduct experiments on relation classification, topic classification, and entity typing tasks in both fully supervised setting and few-shot setting. The results indicate that our model outperforms former baselines.
Hierarchical Character Tagger for Short Text Spelling Error Correction
Sep 29, 2021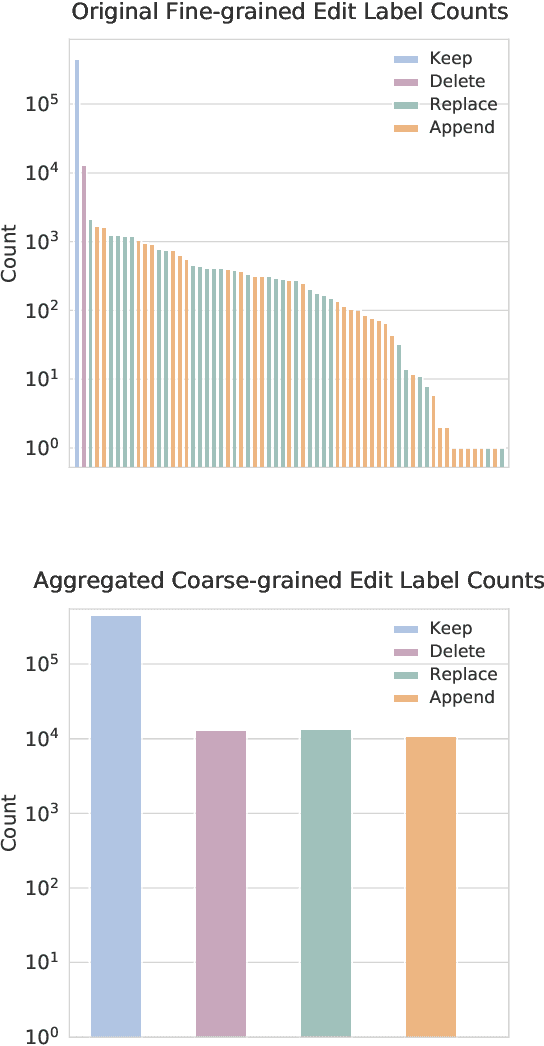

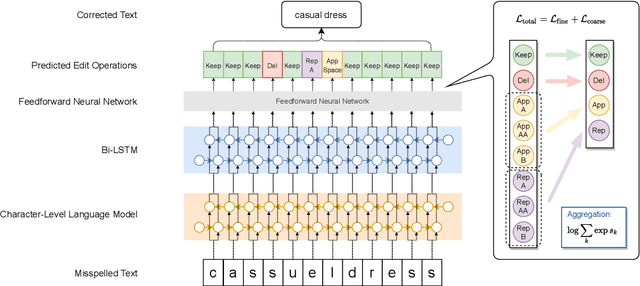
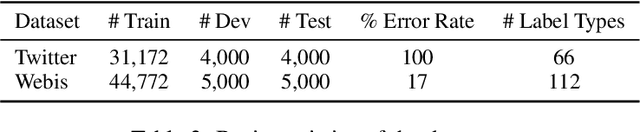
State-of-the-art approaches to spelling error correction problem include Transformer-based Seq2Seq models, which require large training sets and suffer from slow inference time; and sequence labeling models based on Transformer encoders like BERT, which involve token-level label space and therefore a large pre-defined vocabulary dictionary. In this paper we present a Hierarchical Character Tagger model, or HCTagger, for short text spelling error correction. We use a pre-trained language model at the character level as a text encoder, and then predict character-level edits to transform the original text into its error-free form with a much smaller label space. For decoding, we propose a hierarchical multi-task approach to alleviate the issue of long-tail label distribution without introducing extra model parameters. Experiments on two public misspelling correction datasets demonstrate that HCTagger is an accurate and much faster approach than many existing models.
Learning Feature Interactions with Lorentzian Factorization Machine
Nov 22, 2019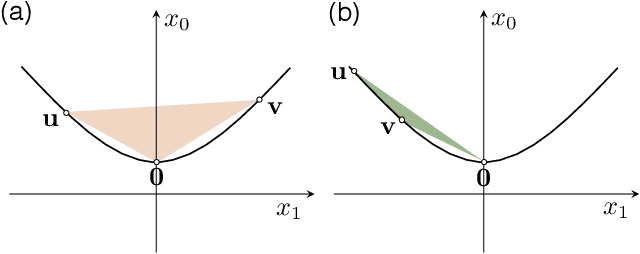
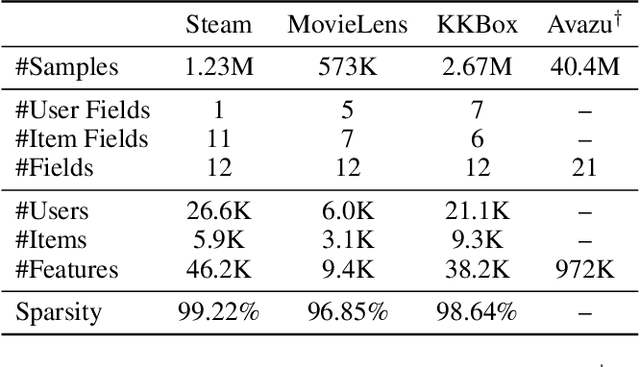
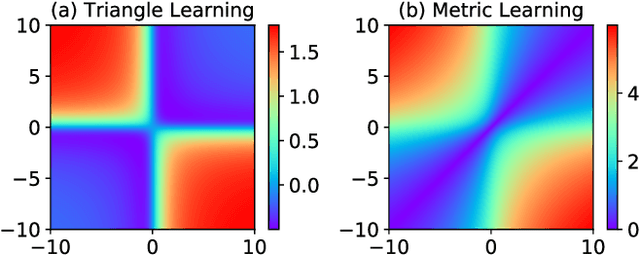
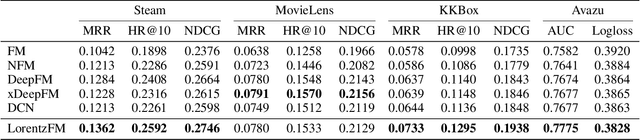
Learning representations for feature interactions to model user behaviors is critical for recommendation system and click-trough rate (CTR) predictions. Recent advances in this area are empowered by deep learning methods which could learn sophisticated feature interactions and achieve the state-of-the-art result in an end-to-end manner. These approaches require large number of training parameters integrated with the low-level representations, and thus are memory and computational inefficient. In this paper, we propose a new model named "LorentzFM" that can learn feature interactions embedded in a hyperbolic space in which the violation of triangle inequality for Lorentz distances is available. To this end, the learned representation is benefited by the peculiar geometric properties of hyperbolic triangles, and result in a significant reduction in the number of parameters (20\% to 80\%) because all the top deep learning layers are not required. With such a lightweight architecture, LorentzFM achieves comparable and even materially better results than the deep learning methods such as DeepFM, xDeepFM and Deep \& Cross in both recommendation and CTR prediction tasks.
Relation Embedding with Dihedral Group in Knowledge Graph
Jun 03, 2019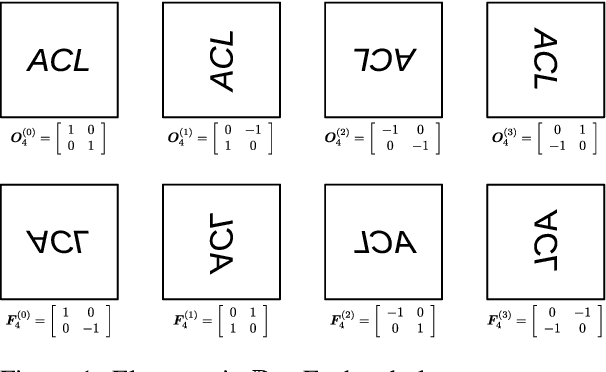

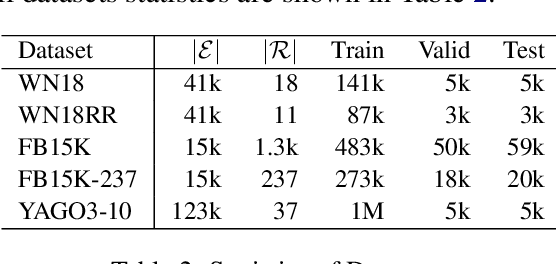
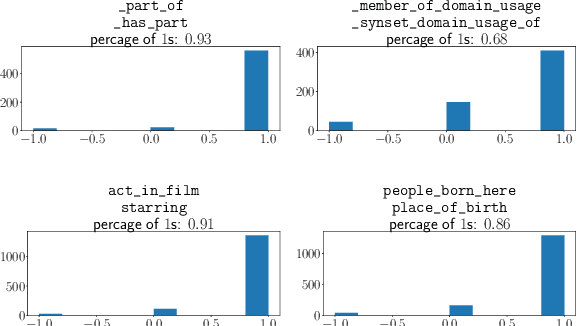
Link prediction is critical for the application of incomplete knowledge graph (KG) in the downstream tasks. As a family of effective approaches for link predictions, embedding methods try to learn low-rank representations for both entities and relations such that the bilinear form defined therein is a well-behaved scoring function. Despite of their successful performances, existing bilinear forms overlook the modeling of relation compositions, resulting in lacks of interpretability for reasoning on KG. To fulfill this gap, we propose a new model called DihEdral, named after dihedral symmetry group. This new model learns knowledge graph embeddings that can capture relation compositions by nature. Furthermore, our approach models the relation embeddings parametrized by discrete values, thereby decrease the solution space drastically. Our experiments show that DihEdral is able to capture all desired properties such as (skew-) symmetry, inversion and (non-) Abelian composition, and outperforms existing bilinear form based approach and is comparable to or better than deep learning models such as ConvE.