 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlign$^3$GR: Unified Multi-Level Alignment for LLM-based Generative Recommendation
Nov 14, 2025Large Language Models (LLMs) demonstrate significant advantages in leveraging structured world knowledge and multi-step reasoning capabilities. However, fundamental challenges arise when transforming LLMs into real-world recommender systems due to semantic and behavioral misalignment. To bridge this gap, we propose Align$^3$GR, a novel framework that unifies token-level, behavior modeling-level, and preference-level alignment. Our approach introduces: Dual tokenization fusing user-item semantic and collaborative signals. Enhanced behavior modeling with bidirectional semantic alignment. Progressive DPO strategy combining self-play (SP-DPO) and real-world feedback (RF-DPO) for dynamic preference adaptation. Experiments show Align$^3$GR outperforms the SOTA baseline by +17.8% in Recall@10 and +20.2% in NDCG@10 on the public dataset, with significant gains in online A/B tests and full-scale deployment on an industrial large-scale recommendation platform.
Lumos3D: A Single-Forward Framework for Low-Light 3D Scene Restoration
Nov 12, 2025



Restoring 3D scenes captured under low-light con- ditions remains a fundamental yet challenging problem. Most existing approaches depend on precomputed camera poses and scene-specific optimization, which greatly restricts their scala- bility to dynamic real-world environments. To overcome these limitations, we introduce Lumos3D, a generalizable pose-free framework for 3D low-light scene restoration. Trained once on a single dataset, Lumos3D performs inference in a purely feed- forward manner, directly restoring illumination and structure from unposed, low-light multi-view images without any per- scene training or optimization. Built upon a geometry-grounded backbone, Lumos3D reconstructs a normal-light 3D Gaussian representation that restores illumination while faithfully pre- serving structural details. During training, a cross-illumination distillation scheme is employed, where the teacher network is distilled on normal-light ground truth to transfer accurate geometric information, such as depth, to the student model. A dedicated Lumos loss is further introduced to promote photomet- ric consistency within the reconstructed 3D space. Experiments on real-world datasets demonstrate that Lumos3D achieves high- fidelity low-light 3D scene restoration with accurate geometry and strong generalization to unseen cases. Furthermore, the framework naturally extends to handle over-exposure correction, highlighting its versatility for diverse lighting restoration tasks.
Stylos: Multi-View 3D Stylization with Single-Forward Gaussian Splatting
Sep 30, 2025We present Stylos, a single-forward 3D Gaussian framework for 3D style transfer that operates on unposed content, from a single image to a multi-view collection, conditioned on a separate reference style image. Stylos synthesizes a stylized 3D Gaussian scene without per-scene optimization or precomputed poses, achieving geometry-aware, view-consistent stylization that generalizes to unseen categories, scenes, and styles. At its core, Stylos adopts a Transformer backbone with two pathways: geometry predictions retain self-attention to preserve geometric fidelity, while style is injected via global cross-attention to enforce visual consistency across views. With the addition of a voxel-based 3D style loss that aligns aggregated scene features to style statistics, Stylos enforces view-consistent stylization while preserving geometry. Experiments across multiple datasets demonstrate that Stylos delivers high-quality zero-shot stylization, highlighting the effectiveness of global style-content coupling, the proposed 3D style loss, and the scalability of our framework from single view to large-scale multi-view settings.
Generative Auto-Bidding in Large-Scale Competitive Auctions via Diffusion Completer-Aligner
Sep 03, 2025Auto-bidding is central to computational advertising, achieving notable commercial success by optimizing advertisers' bids within economic constraints. Recently, large generative models show potential to revolutionize auto-bidding by generating bids that could flexibly adapt to complex, competitive environments. Among them, diffusers stand out for their ability to address sparse-reward challenges by focusing on trajectory-level accumulated rewards, as well as their explainable capability, i.e., planning a future trajectory of states and executing bids accordingly. However, diffusers struggle with generation uncertainty, particularly regarding dynamic legitimacy between adjacent states, which can lead to poor bids and further cause significant loss of ad impression opportunities when competing with other advertisers in a highly competitive auction environment. To address it, we propose a Causal auto-Bidding method based on a Diffusion completer-aligner framework, termed CBD. Firstly, we augment the diffusion training process with an extra random variable t, where the model observes t-length historical sequences with the goal of completing the remaining sequence, thereby enhancing the generated sequences' dynamic legitimacy. Then, we employ a trajectory-level return model to refine the generated trajectories, aligning more closely with advertisers' objectives. Experimental results across diverse settings demonstrate that our approach not only achieves superior performance on large-scale auto-bidding benchmarks, such as a 29.9% improvement in conversion value in the challenging sparse-reward auction setting, but also delivers significant improvements on the Kuaishou online advertising platform, including a 2.0% increase in target cost.
VQL: An End-to-End Context-Aware Vector Quantization Attention for Ultra-Long User Behavior Modeling
Aug 23, 2025In large-scale recommender systems, ultra-long user behavior sequences encode rich signals of evolving interests. Extending sequence length generally improves accuracy, but directly modeling such sequences in production is infeasible due to latency and memory constraints. Existing solutions fall into two categories: (1) top-k retrieval, which truncates the sequence and may discard most attention mass when L >> k; and (2) encoder-based compression, which preserves coverage but often over-compresses and fails to incorporate key context such as temporal gaps or target-aware signals. Neither class achieves a good balance of low-loss compression, context awareness, and efficiency. We propose VQL, a context-aware Vector Quantization Attention framework for ultra-long behavior modeling, with three innovations. (1) Key-only quantization: only attention keys are quantized, while values remain intact; we prove that softmax normalization yields an error bound independent of sequence length, and a codebook loss directly supervises quantization quality. This also enables L-free inference via offline caches. (2) Multi-scale quantization: attention heads are partitioned into groups, each with its own small codebook, which reduces quantization error while keeping cache size fixed. (3) Efficient context injection: static features (e.g., item category, modality) are directly integrated, and relative position is modeled via a separable temporal kernel. All context is injected without enlarging the codebook, so cached representations remain query-independent. Experiments on three large-scale datasets (KuaiRand-1K, KuaiRec, TMALL) show that VQL consistently outperforms strong baselines, achieving higher accuracy while reducing inference latency, establishing a new state of the art in balancing accuracy and efficiency for ultra-long sequence recommendation.
Expert-Guided Diffusion Planner for Auto-bidding
Aug 12, 2025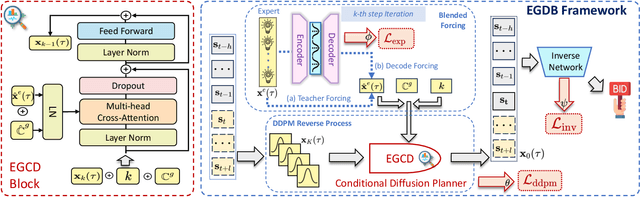
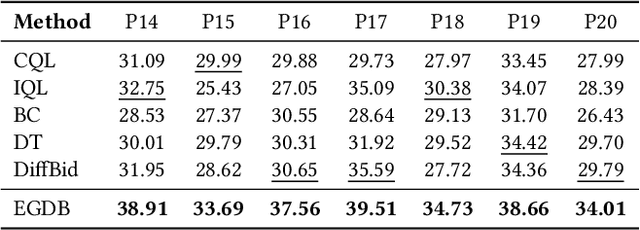
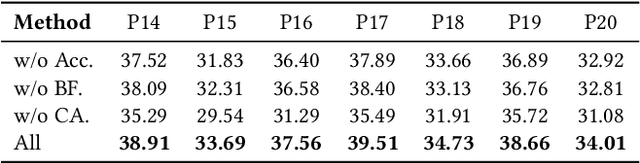
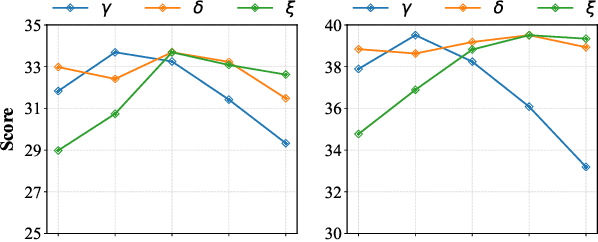
Auto-bidding is extensively applied in advertising systems, serving a multitude of advertisers. Generative bidding is gradually gaining traction due to its robust planning capabilities and generalizability. In contrast to traditional reinforcement learning-based bidding, generative bidding does not rely on the Markov Decision Process (MDP) exhibiting superior planning capabilities in long-horizon scenarios. Conditional diffusion modeling approaches have demonstrated significant potential in the realm of auto-bidding. However, relying solely on return as the optimality condition is weak to guarantee the generation of genuinely optimal decision sequences, lacking personalized structural information. Moreover, diffusion models' t-step autoregressive generation mechanism inherently carries timeliness risks. To address these issues, we propose a novel conditional diffusion modeling method based on expert trajectory guidance combined with a skip-step sampling strategy to enhance generation efficiency. We have validated the effectiveness of this approach through extensive offline experiments and achieved statistically significant results in online A/B testing, achieving an increase of 11.29% in conversion and a 12.35% in revenue compared with the baseline.
R4ec: A Reasoning, Reflection, and Refinement Framework for Recommendation Systems
Jul 23, 2025Harnessing Large Language Models (LLMs) for recommendation systems has emerged as a prominent avenue, drawing substantial research interest. However, existing approaches primarily involve basic prompt techniques for knowledge acquisition, which resemble System-1 thinking. This makes these methods highly sensitive to errors in the reasoning path, where even a small mistake can lead to an incorrect inference. To this end, in this paper, we propose $R^{4}$ec, a reasoning, reflection and refinement framework that evolves the recommendation system into a weak System-2 model. Specifically, we introduce two models: an actor model that engages in reasoning, and a reflection model that judges these responses and provides valuable feedback. Then the actor model will refine its response based on the feedback, ultimately leading to improved responses. We employ an iterative reflection and refinement process, enabling LLMs to facilitate slow and deliberate System-2-like thinking. Ultimately, the final refined knowledge will be incorporated into a recommendation backbone for prediction. We conduct extensive experiments on Amazon-Book and MovieLens-1M datasets to demonstrate the superiority of $R^{4}$ec. We also deploy $R^{4}$ec on a large scale online advertising platform, showing 2.2\% increase of revenue. Furthermore, we investigate the scaling properties of the actor model and reflection model.
Graph Learning for Cooperative Cell-Free ISAC Systems: From Optimization to Estimation
Jul 09, 2025Cell-free integrated sensing and communication (ISAC) systems have emerged as a promising paradigm for sixth-generation (6G) networks, enabling simultaneous high-rate data transmission and high-precision radar sensing through cooperative distributed access points (APs). Fully exploiting these capabilities requires a unified design that bridges system-level optimization with multi-target parameter estimation. This paper proposes an end-to-end graph learning approach to close this gap, modeling the entire cell-free ISAC network as a heterogeneous graph to jointly design the AP mode selection, user association, precoding, and echo signal processing for multi-target position and velocity estimation. In particular, we propose two novel heterogeneous graph learning frameworks: a dynamic graph learning framework and a lightweight mirror-based graph attention network (mirror-GAT) framework. The dynamic graph learning framework employs structural and temporal attention mechanisms integrated with a three-dimensional convolutional neural network (3D-CNN), enabling superior performance and robustness in cell-free ISAC environments. Conversely, the mirror-GAT framework significantly reduces computational complexity and signaling overhead through a bi-level iterative structure with share adjacency. Simulation results validate that both proposed graph-learning-based frameworks achieve significant improvements in multi-target position and velocity estimation accuracy compared to conventional heuristic and optimization-based designs. Particularly, the mirror-GAT framework demonstrates substantial reductions in computational time and signaling overhead, underscoring its suitability for practical deployments.
Personalized Tree based progressive regression model for watch-time prediction in short video recommendation
May 28, 2025In online video platforms, accurate watch time prediction has become a fundamental and challenging problem in video recommendation. Previous research has revealed that the accuracy of watch time prediction highly depends on both the transformation of watch-time labels and the decomposition of the estimation process. TPM (Tree based Progressive Regression Model) achieves State-of-the-Art performance with a carefully designed and effective decomposition paradigm. TPM discretizes the watch time into several ordinal intervals and organizes them into a binary decision tree, where each node corresponds to a specific interval. At each non-leaf node, a binary classifier is used to determine the specific interval in which the watch time variable most likely falls, based on the prediction outcome at its parent node. The tree structure serves as the core of TPM, as it defines the decomposition of watch time estimation and determines how the ordinal intervals are discretized. However, in TPM, the tree is predefined as a full binary tree, which may be sub-optimal for the following reasons. First, a full binary tree implies an equal partitioning of the watch time space, which may struggle to capture the complexity of real-world watch time distributions. Second, instead of relying on a globally fixed tree structure, we advocate for a personalized, data-driven tree that can be learned in an end-to-end manner. Therefore, we propose PTPM to enable a highly personalized decomposition of watch estimation with better efficacy and efficiency. Moreover, we reveal that TPM is affected by selection bias due to conditional modeling and devise a simple approach to address it. We conduct extensive experiments on both offline datasets and online environments. PTPM has been fully deployed in core traffic scenarios and serves more than 400 million users per day.
Hierarchical Tree Search-based User Lifelong Behavior Modeling on Large Language Model
May 26, 2025Large Language Models (LLMs) have garnered significant attention in Recommendation Systems (RS) due to their extensive world knowledge and robust reasoning capabilities. However, a critical challenge lies in enabling LLMs to effectively comprehend and extract insights from massive user behaviors. Current approaches that directly leverage LLMs for user interest learning face limitations in handling long sequential behaviors, effectively extracting interest, and applying interest in practical scenarios. To address these issues, we propose a Hierarchical Tree Search-based User Lifelong Behavior Modeling framework (HiT-LBM). HiT-LBM integrates Chunked User Behavior Extraction (CUBE) and Hierarchical Tree Search for Interest (HTS) to capture diverse interests and interest evolution of user. CUBE divides user lifelong behaviors into multiple chunks and learns the interest and interest evolution within each chunk in a cascading manner. HTS generates candidate interests through hierarchical expansion and searches for the optimal interest with process rating model to ensure information gain for each behavior chunk. Additionally, we design Temporal-Ware Interest Fusion (TIF) to integrate interests from multiple behavior chunks, constructing a comprehensive representation of user lifelong interests. The representation can be embedded into any recommendation model to enhance performance. Extensive experiments demonstrate the effectiveness of our approach, showing that it surpasses state-of-the-art methods.