 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVQL: An End-to-End Context-Aware Vector Quantization Attention for Ultra-Long User Behavior Modeling
Aug 23, 2025In large-scale recommender systems, ultra-long user behavior sequences encode rich signals of evolving interests. Extending sequence length generally improves accuracy, but directly modeling such sequences in production is infeasible due to latency and memory constraints. Existing solutions fall into two categories: (1) top-k retrieval, which truncates the sequence and may discard most attention mass when L >> k; and (2) encoder-based compression, which preserves coverage but often over-compresses and fails to incorporate key context such as temporal gaps or target-aware signals. Neither class achieves a good balance of low-loss compression, context awareness, and efficiency. We propose VQL, a context-aware Vector Quantization Attention framework for ultra-long behavior modeling, with three innovations. (1) Key-only quantization: only attention keys are quantized, while values remain intact; we prove that softmax normalization yields an error bound independent of sequence length, and a codebook loss directly supervises quantization quality. This also enables L-free inference via offline caches. (2) Multi-scale quantization: attention heads are partitioned into groups, each with its own small codebook, which reduces quantization error while keeping cache size fixed. (3) Efficient context injection: static features (e.g., item category, modality) are directly integrated, and relative position is modeled via a separable temporal kernel. All context is injected without enlarging the codebook, so cached representations remain query-independent. Experiments on three large-scale datasets (KuaiRand-1K, KuaiRec, TMALL) show that VQL consistently outperforms strong baselines, achieving higher accuracy while reducing inference latency, establishing a new state of the art in balancing accuracy and efficiency for ultra-long sequence recommendation.
Expert-Guided Diffusion Planner for Auto-bidding
Aug 12, 2025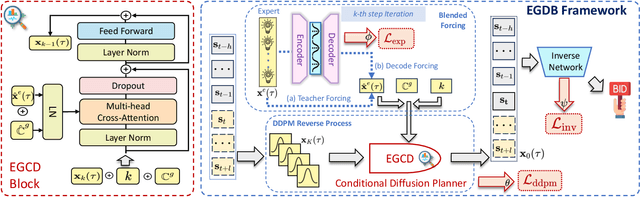
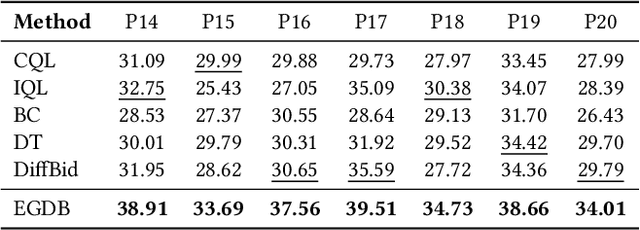
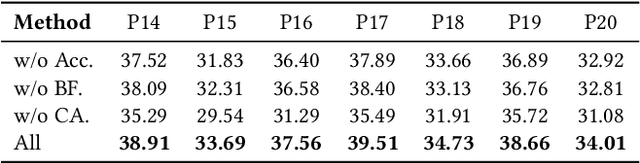
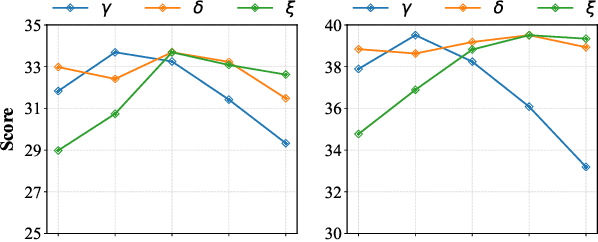
Auto-bidding is extensively applied in advertising systems, serving a multitude of advertisers. Generative bidding is gradually gaining traction due to its robust planning capabilities and generalizability. In contrast to traditional reinforcement learning-based bidding, generative bidding does not rely on the Markov Decision Process (MDP) exhibiting superior planning capabilities in long-horizon scenarios. Conditional diffusion modeling approaches have demonstrated significant potential in the realm of auto-bidding. However, relying solely on return as the optimality condition is weak to guarantee the generation of genuinely optimal decision sequences, lacking personalized structural information. Moreover, diffusion models' t-step autoregressive generation mechanism inherently carries timeliness risks. To address these issues, we propose a novel conditional diffusion modeling method based on expert trajectory guidance combined with a skip-step sampling strategy to enhance generation efficiency. We have validated the effectiveness of this approach through extensive offline experiments and achieved statistically significant results in online A/B testing, achieving an increase of 11.29% in conversion and a 12.35% in revenue compared with the baseline.