 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKOS-TL (Knowledge Operation System Type Logic)
Jan 03, 2026This paper introduces KOS-TL (Knowledge Operation System Type Logic), a novel constructive framework designed to provide a rigorous logical foundation for autonomous and executable knowledge systems. Traditional knowledge representation models often suffer from a gap between static symbolic logic and dynamic system execution. To bridge this divide, KOS-TL leverages Dependent Type Theory to unify data, logic, and proof into a singular computational substrate.The architecture of KOS-TL is organized into three hierarchical layers: the Core Layer, which defines the static type universe and constructive primitives; the Kernel Layer, which governs state evolution through an event-driven mechanism characterized by the triple $\langle Σ, \textsf{Ev}, Δ\rangle$; and the Runtime Layer, responsible for the bidirectional refinement of physical signals into logical evidence. We formally define the operational semantics of the system and prove key meta-theoretical properties, including Progress and Evolutionary Consistency, ensuring that the system remains logically self-consistent and free from stuck states during continuous state transitions.By integrating Davidsonian event semantics with Martin-Löf type theory, KOS-TL enables the construction of "proof-carrying knowledge," where every state change in the knowledge base is accompanied by a formal witness of its validity. We demonstrate the practical utility of this logic through application examples in industrial traceability and cross-border financial compliance. Our results suggest that KOS-TL provides a robust, formally verifiable basis for the next generation of intelligent, autonomous operating systems.
BIOME-Bench: A Benchmark for Biomolecular Interaction Inference and Multi-Omics Pathway Mechanism Elucidation from Scientific Literature
Dec 31, 2025Multi-omics studies often rely on pathway enrichment to interpret heterogeneous molecular changes, but pathway enrichment (PE)-based workflows inherit structural limitations of pathway resources, including curation lag, functional redundancy, and limited sensitivity to molecular states and interventions. Although recent work has explored using large language models (LLMs) to improve PE-based interpretation, the lack of a standardized benchmark for end-to-end multi-omics pathway mechanism elucidation has largely confined evaluation to small, manually curated datasets or ad hoc case studies, hindering reproducible progress. To address this issue, we introduce BIOME-Bench, constructed via a rigorous four-stage workflow, to evaluate two core capabilities of LLMs in multi-omics analysis: Biomolecular Interaction Inference and end-to-end Multi-Omics Pathway Mechanism Elucidation. We develop evaluation protocols for both tasks and conduct comprehensive experiments across multiple strong contemporary models. Experimental results demonstrate that existing models still exhibit substantial deficiencies in multi-omics analysis, struggling to reliably distinguish fine-grained biomolecular relation types and to generate faithful, robust pathway-level mechanistic explanations.
Variationally correct operator learning: Reduced basis neural operator with a posteriori error estimation
Dec 24, 2025Minimizing PDE-residual losses is a common strategy to promote physical consistency in neural operators. However, standard formulations often lack variational correctness, meaning that small residuals do not guarantee small solution errors due to the use of non-compliant norms or ad hoc penalty terms for boundary conditions. This work develops a variationally correct operator learning framework by constructing first-order system least-squares (FOSLS) objectives whose values are provably equivalent to the solution error in PDE-induced norms. We demonstrate this framework on stationary diffusion and linear elasticity, incorporating mixed Dirichlet-Neumann boundary conditions via variational lifts to preserve norm equivalence without inconsistent penalties. To ensure the function space conformity required by the FOSLS loss, we propose a Reduced Basis Neural Operator (RBNO). The RBNO predicts coefficients for a pre-computed, conforming reduced basis, thereby ensuring variational stability by design while enabling efficient training. We provide a rigorous convergence analysis that bounds the total error by the sum of finite element discretization bias, reduced basis truncation error, neural network approximation error, and statistical estimation errors arising from finite sampling and optimization. Numerical benchmarks validate these theoretical bounds and demonstrate that the proposed approach achieves superior accuracy in PDE-compliant norms compared to standard baselines, while the residual loss serves as a reliable, computable a posteriori error estimator.
Towards Non-Stationary Time Series Forecasting with Temporal Stabilization and Frequency Differencing
Nov 17, 2025Time series forecasting is critical for decision-making across dynamic domains such as energy, finance, transportation, and cloud computing. However, real-world time series often exhibit non-stationarity, including temporal distribution shifts and spectral variability, which pose significant challenges for long-term time series forecasting. In this paper, we propose DTAF, a dual-branch framework that addresses non-stationarity in both the temporal and frequency domains. For the temporal domain, the Temporal Stabilizing Fusion (TFS) module employs a non-stationary mix of experts (MOE) filter to disentangle and suppress temporal non-stationary patterns while preserving long-term dependencies. For the frequency domain, the Frequency Wave Modeling (FWM) module applies frequency differencing to dynamically highlight components with significant spectral shifts. By fusing the complementary outputs of TFS and FWM, DTAF generates robust forecasts that adapt to both temporal and frequency domain non-stationarity. Extensive experiments on real-world benchmarks demonstrate that DTAF outperforms state-of-the-art baselines, yielding significant improvements in forecasting accuracy under non-stationary conditions. All codes are available at https://github.com/PandaJunk/DTAF.
Enhancing Multimodal Protein Function Prediction Through Dual-Branch Dynamic Selection with Reconstructive Pre-Training
Nov 06, 2025Multimodal protein features play a crucial role in protein function prediction. However, these features encompass a wide range of information, ranging from structural data and sequence features to protein attributes and interaction networks, making it challenging to decipher their complex interconnections. In this work, we propose a multimodal protein function prediction method (DSRPGO) by utilizing dynamic selection and reconstructive pre-training mechanisms. To acquire complex protein information, we introduce reconstructive pre-training to mine more fine-grained information with low semantic levels. Moreover, we put forward the Bidirectional Interaction Module (BInM) to facilitate interactive learning among multimodal features. Additionally, to address the difficulty of hierarchical multi-label classification in this task, a Dynamic Selection Module (DSM) is designed to select the feature representation that is most conducive to current protein function prediction. Our proposed DSRPGO model improves significantly in BPO, MFO, and CCO on human datasets, thereby outperforming other benchmark models.
Tensor Completion via Monotone Inclusion: Generalized Low-Rank Priors Meet Deep Denoisers
Oct 14, 2025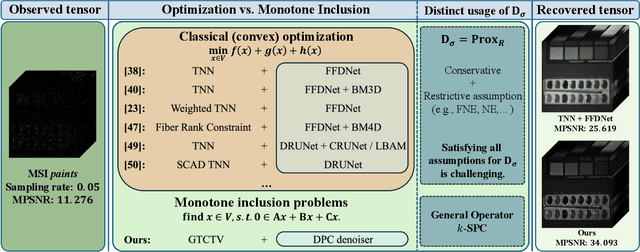
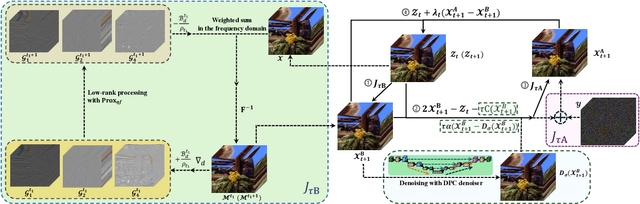

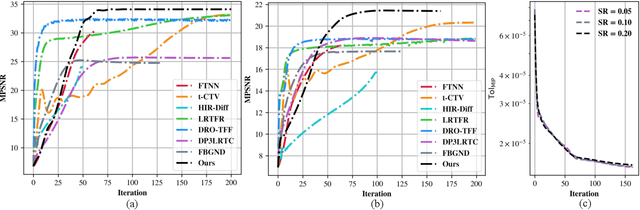
Missing entries in multi dimensional data pose significant challenges for downstream analysis across diverse real world applications. These data are naturally modeled as tensors, and recent completion methods integrating global low rank priors with plug and play denoisers have demonstrated strong empirical performance. However, these approaches often rely on empirical convergence alone or unrealistic assumptions, such as deep denoisers acting as proximal operators of implicit regularizers, which generally does not hold. To address these limitations, we propose a novel tensor completion framework grounded in the monotone inclusion paradigm, which unifies generalized low rank priors with deep pseudo contractive denoisers and extends beyond traditional convex optimization. Building on the Davis Yin splitting scheme, we develop the GTCTV DPC algorithm and rigorously establish its global convergence. Extensive experiments demonstrate that GTCTV DPC consistently outperforms existing methods in both quantitative metrics and visual quality, particularly at low sampling rates.
Aurora: Towards Universal Generative Multimodal Time Series Forecasting
Sep 26, 2025Cross-domain generalization is very important in Time Series Forecasting because similar historical information may lead to distinct future trends due to the domain-specific characteristics. Recent works focus on building unimodal time series foundation models and end-to-end multimodal supervised models. Since domain-specific knowledge is often contained in modalities like texts, the former lacks the explicit utilization of them, thus hindering the performance. The latter is tailored for end-to-end scenarios and does not support zero-shot inference for cross-domain scenarios. In this work, we introduce Aurora, a Multimodal Time Series Foundation Model, which supports multimodal inputs and zero-shot inference. Pretrained on Corss-domain Multimodal Time Series Corpus, Aurora can adaptively extract and focus on key domain knowledge contained in corrsponding text or image modalities, thus possessing strong Cross-domain generalization capability. Through tokenization, encoding, and distillation, Aurora can extract multimodal domain knowledge as guidance and then utilizes a Modality-Guided Multi-head Self-Attention to inject them into the modeling of temporal representations. In the decoding phase, the multimodal representations are used to generate the conditions and prototypes of future tokens, contributing to a novel Prototype-Guided Flow Matching for generative probabilistic forecasting. Comprehensive experiments on well-recognized benchmarks, including TimeMMD, TSFM-Bench and ProbTS, demonstrate the consistent state-of-the-art performance of Aurora on both unimodal and multimodal scenarios.
Hunyuan3D Studio: End-to-End AI Pipeline for Game-Ready 3D Asset Generation
Sep 16, 2025



The creation of high-quality 3D assets, a cornerstone of modern game development, has long been characterized by labor-intensive and specialized workflows. This paper presents Hunyuan3D Studio, an end-to-end AI-powered content creation platform designed to revolutionize the game production pipeline by automating and streamlining the generation of game-ready 3D assets. At its core, Hunyuan3D Studio integrates a suite of advanced neural modules (such as Part-level 3D Generation, Polygon Generation, Semantic UV, etc.) into a cohesive and user-friendly system. This unified framework allows for the rapid transformation of a single concept image or textual description into a fully-realized, production-quality 3D model complete with optimized geometry and high-fidelity PBR textures. We demonstrate that assets generated by Hunyuan3D Studio are not only visually compelling but also adhere to the stringent technical requirements of contemporary game engines, significantly reducing iteration time and lowering the barrier to entry for 3D content creation. By providing a seamless bridge from creative intent to technical asset, Hunyuan3D Studio represents a significant leap forward for AI-assisted workflows in game development and interactive media.
Visual-CoG: Stage-Aware Reinforcement Learning with Chain of Guidance for Text-to-Image Generation
Aug 25, 2025



Despite the promising progress of recent autoregressive models in text-to-image (T2I) generation, their ability to handle multi-attribute and ambiguous prompts remains limited. To address these limitations, existing works have applied chain-of-thought (CoT) to enable stage-aware visual synthesis and employed reinforcement learning (RL) to improve reasoning capabilities. However, most models provide reward signals only at the end of the generation stage. This monolithic final-only guidance makes it difficult to identify which stages contribute positively to the final outcome and may lead to suboptimal policies. To tackle this issue, we propose a Visual-Chain of Guidance (Visual-CoG) paradigm consisting of three stages: semantic reasoning, process refining, and outcome evaluation, with stage-aware rewards providing immediate guidance throughout the image generation pipeline. We further construct a visual cognition benchmark, VisCog-Bench, which comprises four subtasks to evaluate the effectiveness of semantic reasoning. Comprehensive evaluations on GenEval, T2I-CompBench, and the proposed VisCog-Bench show improvements of 15%, 5%, and 19%, respectively, demonstrating the superior performance of the proposed Visual-CoG. We will release all the resources soon.
CC-Time: Cross-Model and Cross-Modality Time Series Forecasting
Aug 17, 2025



With the success of pre-trained language models (PLMs) in various application fields beyond natural language processing, language models have raised emerging attention in the field of time series forecasting (TSF) and have shown great prospects. However, current PLM-based TSF methods still fail to achieve satisfactory prediction accuracy matching the strong sequential modeling power of language models. To address this issue, we propose Cross-Model and Cross-Modality Learning with PLMs for time series forecasting (CC-Time). We explore the potential of PLMs for time series forecasting from two aspects: 1) what time series features could be modeled by PLMs, and 2) whether relying solely on PLMs is sufficient for building time series models. In the first aspect, CC-Time incorporates cross-modality learning to model temporal dependency and channel correlations in the language model from both time series sequences and their corresponding text descriptions. In the second aspect, CC-Time further proposes the cross-model fusion block to adaptively integrate knowledge from the PLMs and time series model to form a more comprehensive modeling of time series patterns. Extensive experiments on nine real-world datasets demonstrate that CC-Time achieves state-of-the-art prediction accuracy in both full-data training and few-shot learning situations.