 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReContraster: Making Your Posters Stand Out with Regional Contrast
Apr 12, 2026Effective poster design requires rapidly capturing attention and clearly conveying messages. Inspired by the ``contrast effects'' principle, we propose ReContraster, the first training-free model to leverage regional contrast to make posters stand out. By emulating the cognitive behaviors of a poster designer, ReContraster introduces the compositional multi-agent system to identify elements, organize layout, and evaluate generated poster candidates. To further ensure harmonious transitions across region boundaries, ReContraster integrates the hybrid denoising strategy during the diffusion process. We additionally contribute a new benchmark dataset for comprehensive evaluation. Seven quantitative metrics and four user studies confirm its superiority over relevant state-of-the-art methods, producing visually striking and aesthetically appealing posters.
A Benchmark and Multi-Agent System for Instruction-driven Cinematic Video Compilation
Apr 12, 2026The surging demand for adapting long-form cinematic content into short videos has motivated the need for versatile automatic video compilation systems. However, existing compilation methods are limited to predefined tasks, and the community lacks a comprehensive benchmark to evaluate the cinematic compilation. To address this, we introduce CineBench, the first benchmark for instruction-driven cinematic video compilation, featuring diverse user instructions and high-quality ground-truth compilations annotated by professional editors. To overcome contextual collapse and temporal fragmentation, we present CineAgents, a multi-agent system that reformulates cinematic video compilation into ``design-and-compose'' paradigm. CineAgents performs script reverse-engineering to construct a hierarchical narrative memory to provide multi-level context and employs an iterative narrative planning process that refines a creative blueprint into a final compiled script. Extensive experiments demonstrate that CineAgents significantly outperforms existing methods, generating compilations with superior narrative coherence and logical coherence.
Towards Deeper Emotional Reflection: Crafting Affective Image Filters with Generative Priors
Dec 19, 2025

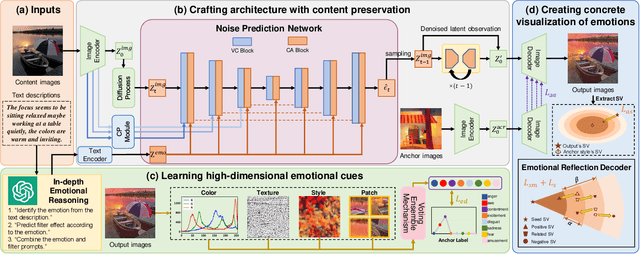
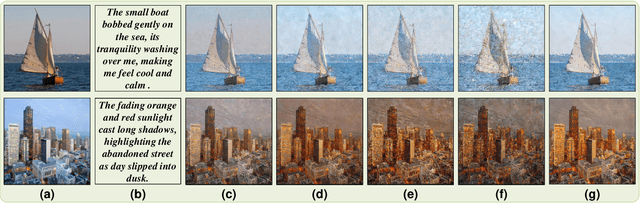
Social media platforms enable users to express emotions by posting text with accompanying images. In this paper, we propose the Affective Image Filter (AIF) task, which aims to reflect visually-abstract emotions from text into visually-concrete images, thereby creating emotionally compelling results. We first introduce the AIF dataset and the formulation of the AIF models. Then, we present AIF-B as an initial attempt based on a multi-modal transformer architecture. After that, we propose AIF-D as an extension of AIF-B towards deeper emotional reflection, effectively leveraging generative priors from pre-trained large-scale diffusion models. Quantitative and qualitative experiments demonstrate that AIF models achieve superior performance for both content consistency and emotional fidelity compared to state-of-the-art methods. Extensive user study experiments demonstrate that AIF models are significantly more effective at evoking specific emotions. Based on the presented results, we comprehensively discuss the value and potential of AIF models.
STAGE: Storyboard-Anchored Generation for Cinematic Multi-shot Narrative
Dec 13, 2025



While recent advancements in generative models have achieved remarkable visual fidelity in video synthesis, creating coherent multi-shot narratives remains a significant challenge. To address this, keyframe-based approaches have emerged as a promising alternative to computationally intensive end-to-end methods, offering the advantages of fine-grained control and greater efficiency. However, these methods often fail to maintain cross-shot consistency and capture cinematic language. In this paper, we introduce STAGE, a SToryboard-Anchored GEneration workflow to reformulate the keyframe-based multi-shot video generation task. Instead of using sparse keyframes, we propose STEP2 to predict a structural storyboard composed of start-end frame pairs for each shot. We introduce the multi-shot memory pack to ensure long-range entity consistency, the dual-encoding strategy for intra-shot coherence, and the two-stage training scheme to learn cinematic inter-shot transition. We also contribute the large-scale ConStoryBoard dataset, including high-quality movie clips with fine-grained annotations for story progression, cinematic attributes, and human preferences. Extensive experiments demonstrate that STAGE achieves superior performance in structured narrative control and cross-shot coherence.
Affective Image Editing: Shaping Emotional Factors via Text Descriptions
May 24, 2025In daily life, images as common affective stimuli have widespread applications. Despite significant progress in text-driven image editing, there is limited work focusing on understanding users' emotional requests. In this paper, we introduce AIEdiT for Affective Image Editing using Text descriptions, which evokes specific emotions by adaptively shaping multiple emotional factors across the entire images. To represent universal emotional priors, we build the continuous emotional spectrum and extract nuanced emotional requests. To manipulate emotional factors, we design the emotional mapper to translate visually-abstract emotional requests to visually-concrete semantic representations. To ensure that editing results evoke specific emotions, we introduce an MLLM to supervise the model training. During inference, we strategically distort visual elements and subsequently shape corresponding emotional factors to edit images according to users' instructions. Additionally, we introduce a large-scale dataset that includes the emotion-aligned text and image pair set for training and evaluation. Extensive experiments demonstrate that AIEdiT achieves superior performance, effectively reflecting users' emotional requests.
CPR-Coach: Recognizing Composite Error Actions based on Single-class Training
Sep 21, 2023



The fine-grained medical action analysis task has received considerable attention from pattern recognition communities recently, but it faces the problems of data and algorithm shortage. Cardiopulmonary Resuscitation (CPR) is an essential skill in emergency treatment. Currently, the assessment of CPR skills mainly depends on dummies and trainers, leading to high training costs and low efficiency. For the first time, this paper constructs a vision-based system to complete error action recognition and skill assessment in CPR. Specifically, we define 13 types of single-error actions and 74 types of composite error actions during external cardiac compression and then develop a video dataset named CPR-Coach. By taking the CPR-Coach as a benchmark, this paper thoroughly investigates and compares the performance of existing action recognition models based on different data modalities. To solve the unavoidable Single-class Training & Multi-class Testing problem, we propose a humancognition-inspired framework named ImagineNet to improve the model's multierror recognition performance under restricted supervision. Extensive experiments verify the effectiveness of the framework. We hope this work could advance research toward fine-grained medical action analysis and skill assessment. The CPR-Coach dataset and the code of ImagineNet are publicly available on Github.
AIDE: A Vision-Driven Multi-View, Multi-Modal, Multi-Tasking Dataset for Assistive Driving Perception
Aug 01, 2023



Driver distraction has become a significant cause of severe traffic accidents over the past decade. Despite the growing development of vision-driven driver monitoring systems, the lack of comprehensive perception datasets restricts road safety and traffic security. In this paper, we present an AssIstive Driving pErception dataset (AIDE) that considers context information both inside and outside the vehicle in naturalistic scenarios. AIDE facilitates holistic driver monitoring through three distinctive characteristics, including multi-view settings of driver and scene, multi-modal annotations of face, body, posture, and gesture, and four pragmatic task designs for driving understanding. To thoroughly explore AIDE, we provide experimental benchmarks on three kinds of baseline frameworks via extensive methods. Moreover, two fusion strategies are introduced to give new insights into learning effective multi-stream/modal representations. We also systematically investigate the importance and rationality of the key components in AIDE and benchmarks. The project link is https://github.com/ydk122024/AIDE.
L-CAD: Language-based Colorization with Any-level Descriptions
May 26, 2023



Language-based colorization produces plausible and visually pleasing colors under the guidance of user-friendly natural language descriptions. Previous methods implicitly assume that users provide comprehensive color descriptions for most of the objects in the image, which leads to suboptimal performance. In this paper, we propose a unified model to perform language-based colorization with any-level descriptions. We leverage the pretrained cross-modality generative model for its robust language understanding and rich color priors to handle the inherent ambiguity of any-level descriptions. We further design modules to align with input conditions to preserve local spatial structures and prevent the ghosting effect. With the proposed novel sampling strategy, our model achieves instance-aware colorization in diverse and complex scenarios. Extensive experimental results demonstrate our advantages of effectively handling any-level descriptions and outperforming both language-based and automatic colorization methods. The code and pretrained models are available at: https://github.com/changzheng123/L-CAD.
Forecasting User Interests Through Topic Tag Predictions in Online Health Communities
Nov 05, 2022The increasing reliance on online communities for healthcare information by patients and caregivers has led to the increase in the spread of misinformation, or subjective, anecdotal and inaccurate or non-specific recommendations, which, if acted on, could cause serious harm to the patients. Hence, there is an urgent need to connect users with accurate and tailored health information in a timely manner to prevent such harm. This paper proposes an innovative approach to suggesting reliable information to participants in online communities as they move through different stages in their disease or treatment. We hypothesize that patients with similar histories of disease progression or course of treatment would have similar information needs at comparable stages. Specifically, we pose the problem of predicting topic tags or keywords that describe the future information needs of users based on their profiles, traces of their online interactions within the community (past posts, replies) and the profiles and traces of online interactions of other users with similar profiles and similar traces of past interaction with the target users. The result is a variant of the collaborative information filtering or recommendation system tailored to the needs of users of online health communities. We report results of our experiments on an expert curated data set which demonstrate the superiority of the proposed approach over the state of the art baselines with respect to accurate and timely prediction of topic tags (and hence information sources of interest).