 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Benchmark and Multi-Agent System for Instruction-driven Cinematic Video Compilation
Apr 12, 2026The surging demand for adapting long-form cinematic content into short videos has motivated the need for versatile automatic video compilation systems. However, existing compilation methods are limited to predefined tasks, and the community lacks a comprehensive benchmark to evaluate the cinematic compilation. To address this, we introduce CineBench, the first benchmark for instruction-driven cinematic video compilation, featuring diverse user instructions and high-quality ground-truth compilations annotated by professional editors. To overcome contextual collapse and temporal fragmentation, we present CineAgents, a multi-agent system that reformulates cinematic video compilation into ``design-and-compose'' paradigm. CineAgents performs script reverse-engineering to construct a hierarchical narrative memory to provide multi-level context and employs an iterative narrative planning process that refines a creative blueprint into a final compiled script. Extensive experiments demonstrate that CineAgents significantly outperforms existing methods, generating compilations with superior narrative coherence and logical coherence.
Comparing Exploration-Exploitation Strategies of LLMs and Humans: Insights from Standard Multi-armed Bandit Tasks
May 15, 2025



Large language models (LLMs) are increasingly used to simulate or automate human behavior in complex sequential decision-making tasks. A natural question is then whether LLMs exhibit similar decision-making behavior to humans, and can achieve comparable (or superior) performance. In this work, we focus on the exploration-exploitation (E&E) tradeoff, a fundamental aspect of dynamic decision-making under uncertainty. We employ canonical multi-armed bandit (MAB) tasks introduced in the cognitive science and psychiatry literature to conduct a comparative study of the E&E strategies of LLMs, humans, and MAB algorithms. We use interpretable choice models to capture the E&E strategies of the agents and investigate how explicit reasoning, through both prompting strategies and reasoning-enhanced models, shapes LLM decision-making. We find that reasoning shifts LLMs toward more human-like behavior, characterized by a mix of random and directed exploration. In simple stationary tasks, reasoning-enabled LLMs exhibit similar levels of random and directed exploration compared to humans. However, in more complex, non-stationary environments, LLMs struggle to match human adaptability, particularly in effective directed exploration, despite achieving similar regret in certain scenarios. Our findings highlight both the promise and limits of LLMs as simulators of human behavior and tools for automated decision-making and point to potential areas of improvements.
An Engorgio Prompt Makes Large Language Model Babble on
Dec 27, 2024



Auto-regressive large language models (LLMs) have yielded impressive performance in many real-world tasks. However, the new paradigm of these LLMs also exposes novel threats. In this paper, we explore their vulnerability to inference cost attacks, where a malicious user crafts Engorgio prompts to intentionally increase the computation cost and latency of the inference process. We design Engorgio, a novel methodology, to efficiently generate adversarial Engorgio prompts to affect the target LLM's service availability. Engorgio has the following two technical contributions. (1) We employ a parameterized distribution to track LLMs' prediction trajectory. (2) Targeting the auto-regressive nature of LLMs' inference process, we propose novel loss functions to stably suppress the appearance of the <EOS> token, whose occurrence will interrupt the LLM's generation process. We conduct extensive experiments on 13 open-sourced LLMs with parameters ranging from 125M to 30B. The results show that Engorgio prompts can successfully induce LLMs to generate abnormally long outputs (i.e., roughly 2-13$\times$ longer to reach 90%+ of the output length limit) in a white-box scenario and our real-world experiment demonstrates Engergio's threat to LLM service with limited computing resources. The code is accessible at https://github.com/jianshuod/Engorgio-prompt.
COSMIC: Compress Satellite Images Efficiently via Diffusion Compensation
Oct 02, 2024



With the rapidly increasing number of satellites in space and their enhanced capabilities, the amount of earth observation images collected by satellites is exceeding the transmission limits of satellite-to-ground links. Although existing learned image compression solutions achieve remarkable performance by using a sophisticated encoder to extract fruitful features as compression and using a decoder to reconstruct, it is still hard to directly deploy those complex encoders on current satellites' embedded GPUs with limited computing capability and power supply to compress images in orbit. In this paper, we propose COSMIC, a simple yet effective learned compression solution to transmit satellite images. We first design a lightweight encoder (i.e. reducing FLOPs by $2.6\sim 5\times $) on satellite to achieve a high image compression ratio to save satellite-to-ground links. Then, for reconstructions on the ground, to deal with the feature extraction ability degradation due to simplifying encoders, we propose a diffusion-based model to compensate image details when decoding. Our insight is that satellite's earth observation photos are not just images but indeed multi-modal data with a nature of Text-to-Image pairing since they are collected with rich sensor data (e.g. coordinates, timestamp, etc.) that can be used as the condition for diffusion generation. Extensive experiments show that COSMIC outperforms state-of-the-art baselines on both perceptual and distortion metrics.
Mind Your Heart: Stealthy Backdoor Attack on Dynamic Deep Neural Network in Edge Computing
Dec 22, 2022Transforming off-the-shelf deep neural network (DNN) models into dynamic multi-exit architectures can achieve inference and transmission efficiency by fragmenting and distributing a large DNN model in edge computing scenarios (e.g., edge devices and cloud servers). In this paper, we propose a novel backdoor attack specifically on the dynamic multi-exit DNN models. Particularly, we inject a backdoor by poisoning one DNN model's shallow hidden layers targeting not this vanilla DNN model but only its dynamically deployed multi-exit architectures. Our backdoored vanilla model behaves normally on performance and cannot be activated even with the correct trigger. However, the backdoor will be activated when the victims acquire this model and transform it into a dynamic multi-exit architecture at their deployment. We conduct extensive experiments to prove the effectiveness of our attack on three structures (ResNet-56, VGG-16, and MobileNet) with four datasets (CIFAR-10, SVHN, GTSRB, and Tiny-ImageNet) and our backdoor is stealthy to evade multiple state-of-the-art backdoor detection or removal methods.
On Learning Disentangled Representations for Gait Recognition
Sep 05, 2019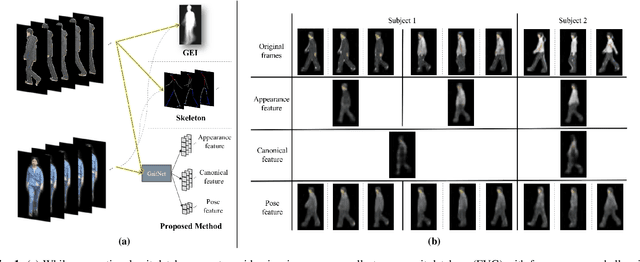


Gait, the walking pattern of individuals, is one of the important biometrics modalities. Most of the existing gait recognition methods take silhouettes or articulated body models as gait features. These methods suffer from degraded recognition performance when handling confounding variables, such as clothing, carrying and viewing angle. To remedy this issue, we propose a novel AutoEncoder framework, GaitNet, to explicitly disentangle appearance, canonical and pose features from RGB imagery. The LSTM integrates pose features over time as a dynamic gait feature while canonical features are averaged as a static gait feature. Both of them are utilized as classification features. In addition, we collect a Frontal-View Gait (FVG) dataset to focus on gait recognition from frontal-view walking, which is a challenging problem since it contains minimal gait cues compared to other views. FVG also includes other important variations, e.g., walking speed, carrying, and clothing. With extensive experiments on CASIA-B, USF, and FVG datasets, our method demonstrates superior performance to the SOTA quantitatively, the ability of feature disentanglement qualitatively, and promising computational efficiency. We further compare our GaitNet with state-of-the-art face recognition to demonstrate the advantages of gait biometrics identification under certain scenarios, e.g., long distance/lower resolutions, cross viewing angles.
Gait Recognition via Disentangled Representation Learning
Apr 09, 2019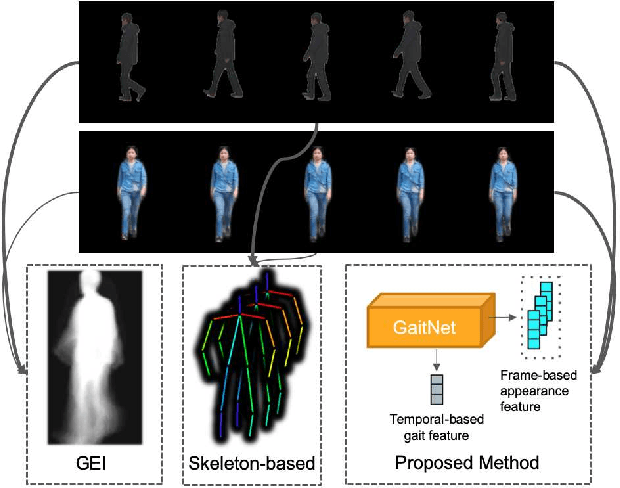

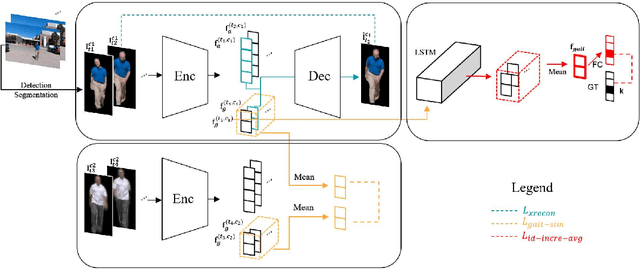

Gait, the walking pattern of individuals, is one of the most important biometrics modalities. Most of the existing gait recognition methods take silhouettes or articulated body models as the gait features. These methods suffer from degraded recognition performance when handling confounding variables, such as clothing, carrying and view angle. To remedy this issue, we propose a novel AutoEncoder framework to explicitly disentangle pose and appearance features from RGB imagery and the LSTM-based integration of pose features over time produces the gait feature. In addition, we collect a Frontal-View Gait (FVG) dataset to focus on gait recognition from frontal-view walking, which is a challenging problem since it contains minimal gait cues compared to other views. FVG also includes other important variations, e.g., walking speed, carrying, and clothing. With extensive experiments on CASIA-B, USF and FVG datasets, our method demonstrates superior performance to the state of the arts quantitatively, the ability of feature disentanglement qualitatively, and promising computational efficiency.