 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePascale Fung
QA4QG: Using Question Answering to Constrain Multi-Hop Question Generation
Feb 14, 2022
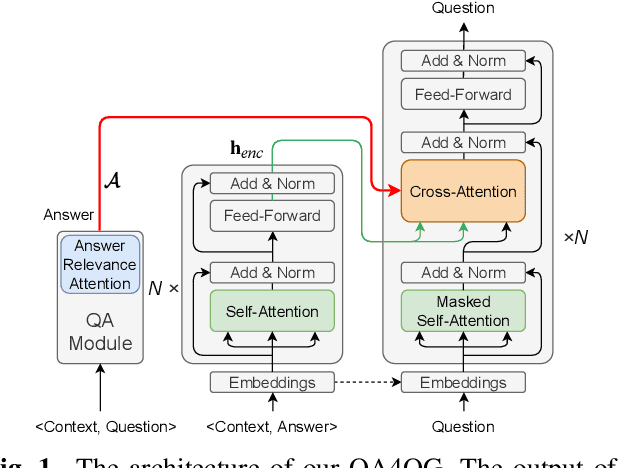
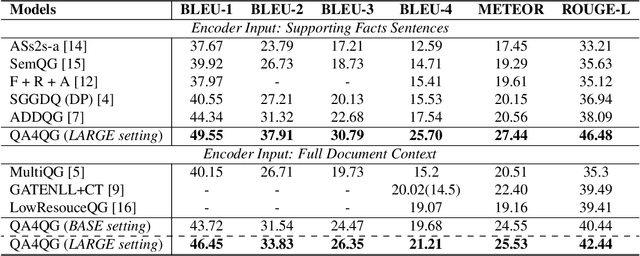
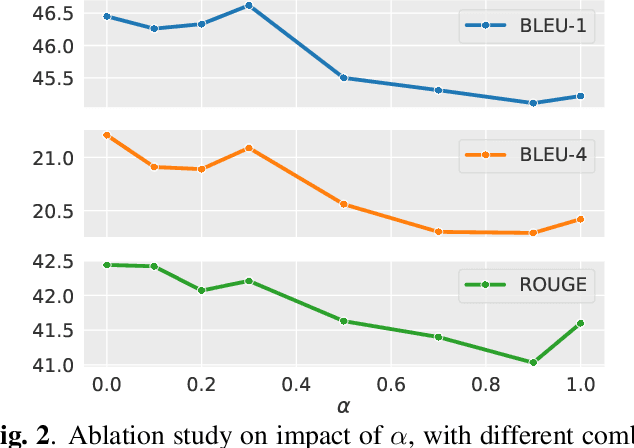
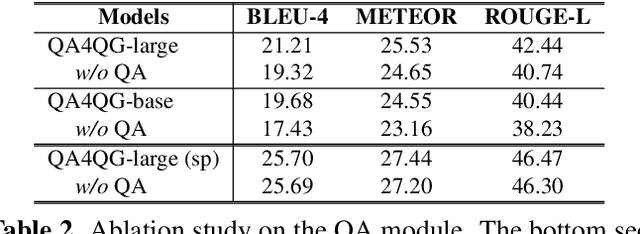
Multi-hop question generation (MQG) aims to generate complex questions which require reasoning over multiple pieces of information of the input passage. Most existing work on MQG has focused on exploring graph-based networks to equip the traditional Sequence-to-sequence framework with reasoning ability. However, these models do not take full advantage of the constraint between questions and answers. Furthermore, studies on multi-hop question answering (QA) suggest that Transformers can replace the graph structure for multi-hop reasoning. Therefore, in this work, we propose a novel framework, QA4QG, a QA-augmented BART-based framework for MQG. It augments the standard BART model with an additional multi-hop QA module to further constrain the generated question. Our results on the HotpotQA dataset show that QA4QG outperforms all state-of-the-art models, with an increase of 8 BLEU-4 and 8 ROUGE points compared to the best results previously reported. Our work suggests the advantage of introducing pre-trained language models and QA module for the MQG task.
Survey of Hallucination in Natural Language Generation
Feb 08, 2022
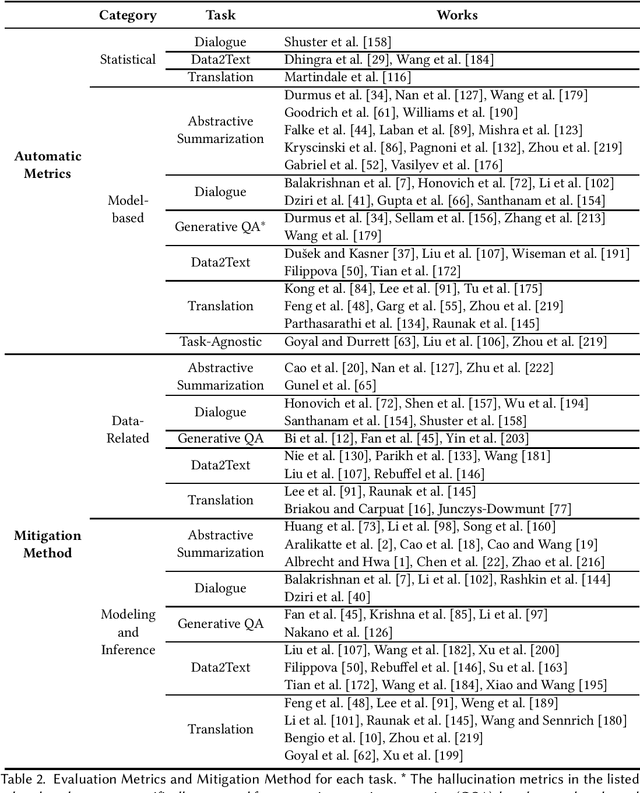
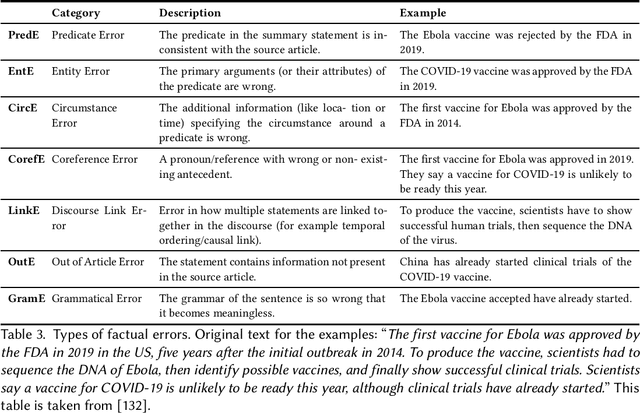
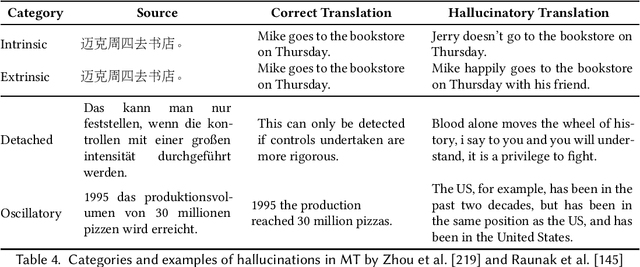
Natural Language Generation (NLG) has improved exponentially in recent years thanks to the development of deep learning technologies such as Transformer-based language models. This advancement has led to more fluent and coherent natural language generation, naturally leading to development in downstream tasks such as abstractive summarization, dialogue generation and data-to-text generation. However, it is also investigated that such generation includes hallucinated texts, which makes the performances of text generation fail to meet users' expectations in many real-world scenarios. In order to address this issue, studies in evaluation and mitigation methods of hallucinations have been presented in various tasks, but have not been reviewed in a combined manner. In this survey, we provide a broad overview of the research progress and challenges in the hallucination problem of NLG. The survey is organized into two big divisions: (i) a general overview of metrics, mitigation methods, and future directions; (ii) task-specific research progress for hallucinations in a large set of downstream tasks: abstractive summarization, dialogue generation, generative question answering, data-to-text generation, and machine translation. This survey could facilitate collaborative efforts among researchers in these tasks.
Automatic Speech Recognition Datasets in Cantonese: A Survey and New Dataset
Jan 17, 2022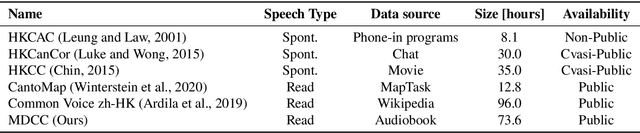
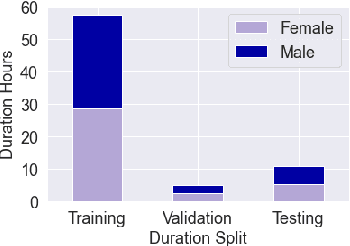
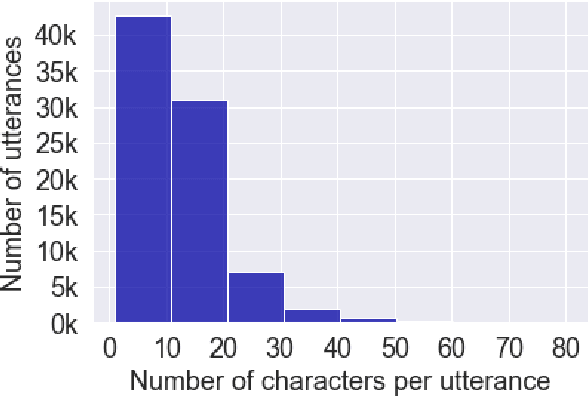
Automatic speech recognition (ASR) on low resource languages improves the access of linguistic minorities to technological advantages provided by artificial intelligence (AI). In this paper, we address the problem of data scarcity for the Hong Kong Cantonese language by creating a new Cantonese dataset. Our dataset, Multi-Domain Cantonese Corpus (MDCC), consists of 73.6 hours of clean read speech paired with transcripts, collected from Cantonese audiobooks from Hong Kong. It comprises philosophy, politics, education, culture, lifestyle and family domains, covering a wide range of topics. We also review all existing Cantonese datasets and analyze them according to their speech type, data source, total size and availability. We further conduct experiments with Fairseq S2T Transformer, a state-of-the-art ASR model, on the biggest existing dataset, Common Voice zh-HK, and our proposed MDCC, and the results show the effectiveness of our dataset. In addition, we create a powerful and robust Cantonese ASR model by applying multi-dataset learning on MDCC and Common Voice zh-HK.
CI-AVSR: A Cantonese Audio-Visual Speech Dataset for In-car Command Recognition
Jan 11, 2022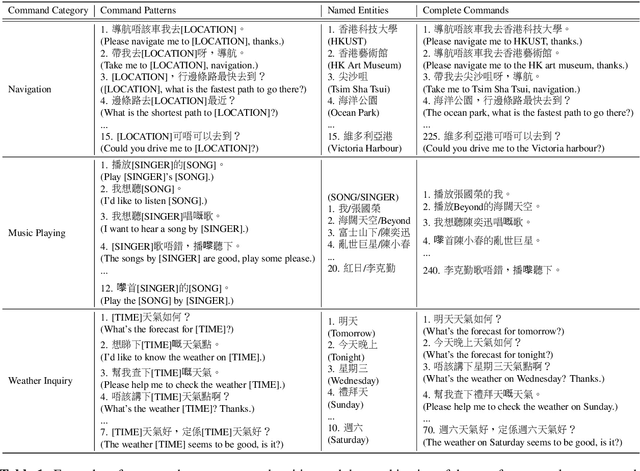
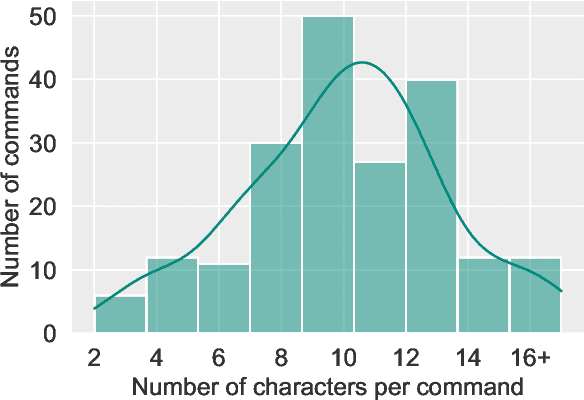
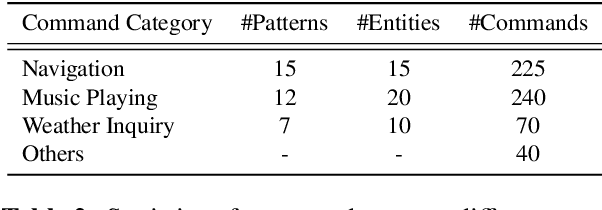
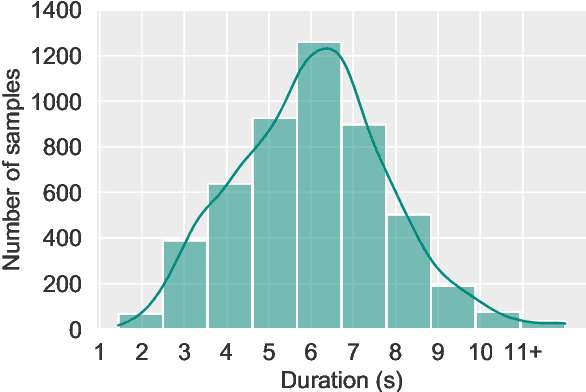
With the rise of deep learning and intelligent vehicle, the smart assistant has become an essential in-car component to facilitate driving and provide extra functionalities. In-car smart assistants should be able to process general as well as car-related commands and perform corresponding actions, which eases driving and improves safety. However, there is a data scarcity issue for low resource languages, hindering the development of research and applications. In this paper, we introduce a new dataset, Cantonese In-car Audio-Visual Speech Recognition (CI-AVSR), for in-car command recognition in the Cantonese language with both video and audio data. It consists of 4,984 samples (8.3 hours) of 200 in-car commands recorded by 30 native Cantonese speakers. Furthermore, we augment our dataset using common in-car background noises to simulate real environments, producing a dataset 10 times larger than the collected one. We provide detailed statistics of both the clean and the augmented versions of our dataset. Moreover, we implement two multimodal baselines to demonstrate the validity of CI-AVSR. Experiment results show that leveraging the visual signal improves the overall performance of the model. Although our best model can achieve a considerable quality on the clean test set, the speech recognition quality on the noisy data is still inferior and remains as an extremely challenging task for real in-car speech recognition systems. The dataset and code will be released at https://github.com/HLTCHKUST/CI-AVSR.
ASCEND: A Spontaneous Chinese-English Dataset for Code-switching in Multi-turn Conversation
Jan 07, 2022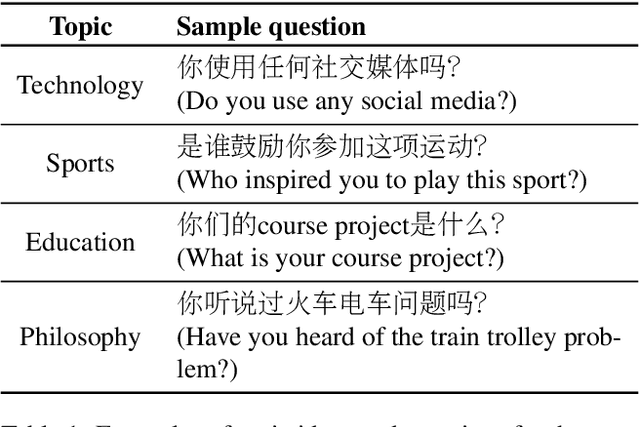

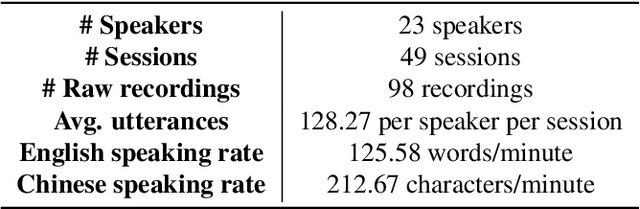
Code-switching is a speech phenomenon when a speaker switches language during a conversation. Despite the spontaneous nature of code-switching in conversational spoken language, most existing works collect code-switching data through read speech instead of spontaneous speech. ASCEND (A Spontaneous Chinese-English Dataset) introduces a high-quality resource of spontaneous multi-turn conversational dialogue Chinese-English code-switching corpus collected in Hong Kong. We report ASCEND's design and procedure of collecting the speech data, including the annotations in this work. ASCEND includes 23 bilinguals that are fluent in both Chinese and English and consists of 10.62 hours clean speech corpus. We also conduct a baseline experiment using pre-trained wav2vec 2.0 models, achieving the best performance of 22.69% character error rate and 27.05% mixed error rate.
Automatic Speech Recognition Datasets in Cantonese Language: A Survey and a New Dataset
Jan 07, 2022Automatic speech recognition (ASR) on low resource languages improves access of linguistic minorities to technological advantages provided by Artificial Intelligence (AI). In this paper, we address a problem of data scarcity of Hong Kong Cantonese language by creating a new Cantonese dataset. Our dataset, Multi-Domain Cantonese Corpus (MDCC), consists of 73.6 hours of clean read speech paired with transcripts, collected from Cantonese audiobooks from Hong Kong. It combines philosophy, politics, education, culture, lifestyle and family domains, covering a wide range of topics. We also review all existing Cantonese datasets and perform experiments on the two biggest datasets (MDCC and Common Voice zh-HK). We analyze the existing datasets according to their speech type, data source, total size and availability. The results of experiments conducted with Fairseq S2T Transformer, a state-of-the-art ASR model, show the effectiveness of our dataset. In addition, we create a powerful and robust Cantonese ASR model by applying multi-dataset learning on MDCC and Common Voice zh-HK.
NER-BERT: A Pre-trained Model for Low-Resource Entity Tagging
Dec 01, 2021
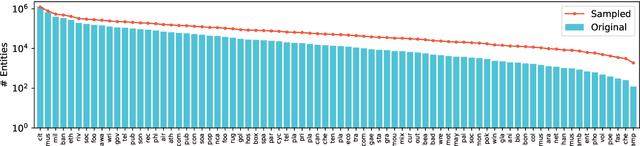

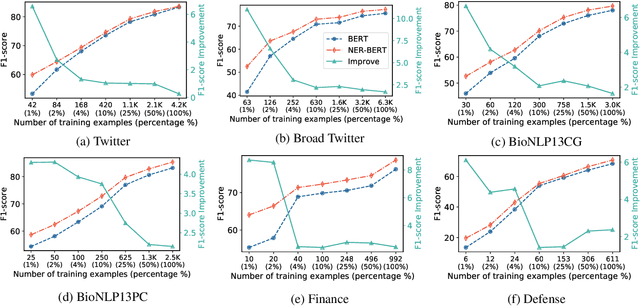
Named entity recognition (NER) models generally perform poorly when large training datasets are unavailable for low-resource domains. Recently, pre-training a large-scale language model has become a promising direction for coping with the data scarcity issue. However, the underlying discrepancies between the language modeling and NER task could limit the models' performance, and pre-training for the NER task has rarely been studied since the collected NER datasets are generally small or large but with low quality. In this paper, we construct a massive NER corpus with a relatively high quality, and we pre-train a NER-BERT model based on the created dataset. Experimental results show that our pre-trained model can significantly outperform BERT as well as other strong baselines in low-resource scenarios across nine diverse domains. Moreover, a visualization of entity representations further indicates the effectiveness of NER-BERT for categorizing a variety of entities.
Confucius, Cyberpunk and Mr. Science: Comparing AI ethics between China and the EU
Nov 15, 2021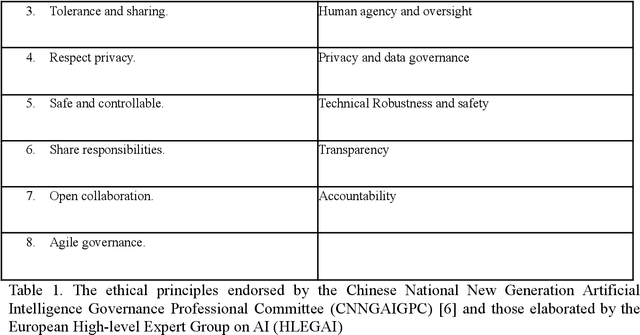
The exponential development and application of artificial intelligence triggered an unprecedented global concern for potential social and ethical issues. Stakeholders from different industries, international foundations, governmental organisations and standards institutions quickly improvised and created various codes of ethics attempting to regulate AI. A major concern is the large homogeneity and presumed consensualism around these principles. While it is true that some ethical doctrines, such as the famous Kantian deontology, aspire to universalism, they are however not universal in practice. In fact, ethical pluralism is more about differences in which relevant questions to ask rather than different answers to a common question. When people abide by different moral doctrines, they tend to disagree on the very approach to an issue. Even when people from different cultures happen to agree on a set of common principles, it does not necessarily mean that they share the same understanding of these concepts and what they entail. In order to better understand the philosophical roots and cultural context underlying ethical principles in AI, we propose to analyse and compare the ethical principles endorsed by the Chinese National New Generation Artificial Intelligence Governance Professional Committee (CNNGAIGPC) and those elaborated by the European High-level Expert Group on AI (HLEGAI). China and the EU have very different political systems and diverge in their cultural heritages. In our analysis, we wish to highlight that principles that seem similar a priori may actually have different meanings, derived from different approaches and reflect distinct goals.