 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Models Reason Early: Exploiting Plan Commitment for Maze Solving
Mar 31, 2026Video diffusion models exhibit emergent reasoning capabilities like solving mazes and puzzles, yet little is understood about how they reason during generation. We take a first step towards understanding this and study the internal planning dynamics of video models using 2D maze solving as a controlled testbed. Our investigations reveal two findings. Our first finding is early plan commitment: video diffusion models commit to a high-level motion plan within the first few denoising steps, after which further denoising alters visual details but not the underlying trajectory. Our second finding is that path length, not obstacle density, is the dominant predictor of maze difficulty, with a sharp failure threshold at 12 steps. This means video models can only reason over long mazes by chaining together multiple sequential generations. To demonstrate the practical benefits of our findings, we introduce Chaining with Early Planning, or ChEaP, which only spends compute on seeds with promising early plans and chains them together to tackle complex mazes. This improves accuracy from 7% to 67% on long-horizon mazes and by 2.5x overall on hard tasks in Frozen Lake and VR-Bench across Wan2.2-14B and HunyuanVideo-1.5. Our analysis reveals that current video models possess deeper reasoning capabilities than previously recognized, which can be elicited more reliably with better inference-time scaling.
Perception Test 2025: Challenge Summary and a Unified VQA Extension
Jan 09, 2026The Third Perception Test challenge was organised as a full-day workshop alongside the IEEE/CVF International Conference on Computer Vision (ICCV) 2025. Its primary goal is to benchmark state-of-the-art video models and measure the progress in multimodal perception. This year, the workshop featured 2 guest tracks as well: KiVA (an image understanding challenge) and Physic-IQ (a video generation challenge). In this report, we summarise the results from the main Perception Test challenge, detailing both the existing tasks as well as novel additions to the benchmark. In this iteration, we placed an emphasis on task unification, as this poses a more challenging test for current SOTA multimodal models. The challenge included five consolidated tracks: unified video QA, unified object and point tracking, unified action and sound localisation, grounded video QA, and hour-long video QA, alongside an analysis and interpretability track that is still open for submissions. Notably, the unified video QA track introduced a novel subset that reformulates traditional perception tasks (such as point tracking and temporal action localisation) as multiple-choice video QA questions that video-language models can natively tackle. The unified object and point tracking merged the original object tracking and point tracking tasks, whereas the unified action and sound localisation merged the original temporal action localisation and temporal sound localisation tracks. Accordingly, we required competitors to use unified approaches rather than engineered pipelines with task-specific models. By proposing such a unified challenge, Perception Test 2025 highlights the significant difficulties existing models face when tackling diverse perception tasks through unified interfaces.
Attention IoU: Examining Biases in CelebA using Attention Maps
Mar 26, 2025



Computer vision models have been shown to exhibit and amplify biases across a wide array of datasets and tasks. Existing methods for quantifying bias in classification models primarily focus on dataset distribution and model performance on subgroups, overlooking the internal workings of a model. We introduce the Attention-IoU (Attention Intersection over Union) metric and related scores, which use attention maps to reveal biases within a model's internal representations and identify image features potentially causing the biases. First, we validate Attention-IoU on the synthetic Waterbirds dataset, showing that the metric accurately measures model bias. We then analyze the CelebA dataset, finding that Attention-IoU uncovers correlations beyond accuracy disparities. Through an investigation of individual attributes through the protected attribute of Male, we examine the distinct ways biases are represented in CelebA. Lastly, by subsampling the training set to change attribute correlations, we demonstrate that Attention-IoU reveals potential confounding variables not present in dataset labels.
Unifying Specialized Visual Encoders for Video Language Models
Jan 02, 2025



The recent advent of Large Language Models (LLMs) has ushered sophisticated reasoning capabilities into the realm of video through Video Large Language Models (VideoLLMs). However, VideoLLMs currently rely on a single vision encoder for all of their visual processing, which limits the amount and type of visual information that can be conveyed to the LLM. Our method, MERV, Multi-Encoder Representation of Videos, instead leverages multiple frozen visual encoders to create a unified representation of a video, providing the VideoLLM with a comprehensive set of specialized visual knowledge. Spatio-temporally aligning the features from each encoder allows us to tackle a wider range of open-ended and multiple-choice video understanding questions and outperform prior state-of-the-art works. MERV is up to 3.7% better in accuracy than Video-LLaVA across the standard suite video understanding benchmarks, while also having a better Video-ChatGPT score. We also improve upon SeViLA, the previous best on zero-shot Perception Test accuracy, by 2.2%. MERV introduces minimal extra parameters and trains faster than equivalent single-encoder methods while parallelizing the visual processing. Finally, we provide qualitative evidence that MERV successfully captures domain knowledge from each of its encoders. Our results offer promising directions in utilizing multiple vision encoders for comprehensive video understanding.
xT: Nested Tokenization for Larger Context in Large Images
Mar 04, 2024



Modern computer vision pipelines handle large images in one of two sub-optimal ways: down-sampling or cropping. These two methods incur significant losses in the amount of information and context present in an image. There are many downstream applications in which global context matters as much as high frequency details, such as in real-world satellite imagery; in such cases researchers have to make the uncomfortable choice of which information to discard. We introduce xT, a simple framework for vision transformers which effectively aggregates global context with local details and can model large images end-to-end on contemporary GPUs. We select a set of benchmark datasets across classic vision tasks which accurately reflect a vision model's ability to understand truly large images and incorporate fine details over large scales and assess our method's improvement on them. By introducing a nested tokenization scheme for large images in conjunction with long-sequence length models normally used for natural language processing, we are able to increase accuracy by up to 8.6% on challenging classification tasks and $F_1$ score by 11.6 on context-dependent segmentation in large images.
PaReprop: Fast Parallelized Reversible Backpropagation
Jun 15, 2023



The growing size of datasets and deep learning models has made faster and memory-efficient training crucial. Reversible transformers have recently been introduced as an exciting new method for extremely memory-efficient training, but they come with an additional computation overhead of activation re-computation in the backpropagation phase. We present PaReprop, a fast Parallelized Reversible Backpropagation algorithm that parallelizes the additional activation re-computation overhead in reversible training with the gradient computation itself in backpropagation phase. We demonstrate the effectiveness of the proposed PaReprop algorithm through extensive benchmarking across model families (ViT, MViT, Swin and RoBERTa), data modalities (Vision & NLP), model sizes (from small to giant), and training batch sizes. Our empirical results show that PaReprop achieves up to 20% higher training throughput than vanilla reversible training, largely mitigating the theoretical overhead of 25% lower throughput from activation recomputation in reversible training. Project page: https://tylerzhu.com/pareprop.
TryOnDiffusion: A Tale of Two UNets
Jun 14, 2023



Given two images depicting a person and a garment worn by another person, our goal is to generate a visualization of how the garment might look on the input person. A key challenge is to synthesize a photorealistic detail-preserving visualization of the garment, while warping the garment to accommodate a significant body pose and shape change across the subjects. Previous methods either focus on garment detail preservation without effective pose and shape variation, or allow try-on with the desired shape and pose but lack garment details. In this paper, we propose a diffusion-based architecture that unifies two UNets (referred to as Parallel-UNet), which allows us to preserve garment details and warp the garment for significant pose and body change in a single network. The key ideas behind Parallel-UNet include: 1) garment is warped implicitly via a cross attention mechanism, 2) garment warp and person blend happen as part of a unified process as opposed to a sequence of two separate tasks. Experimental results indicate that TryOnDiffusion achieves state-of-the-art performance both qualitatively and quantitatively.
SimPose: Effectively Learning DensePose and Surface Normals of People from Simulated Data
Jul 30, 2020
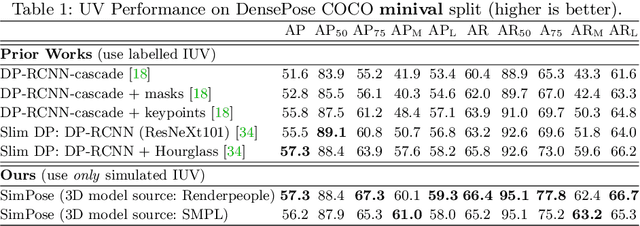
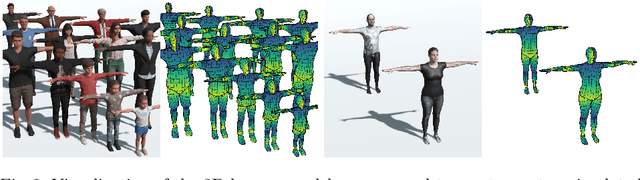
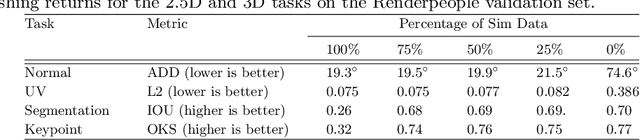
With a proliferation of generic domain-adaptation approaches, we report a simple yet effective technique for learning difficult per-pixel 2.5D and 3D regression representations of articulated people. We obtained strong sim-to-real domain generalization for the 2.5D DensePose estimation task and the 3D human surface normal estimation task. On the multi-person DensePose MSCOCO benchmark, our approach outperforms the state-of-the-art methods which are trained on real images that are densely labelled. This is an important result since obtaining human manifold's intrinsic uv coordinates on real images is time consuming and prone to labeling noise. Additionally, we present our model's 3D surface normal predictions on the MSCOCO dataset that lacks any real 3D surface normal labels. The key to our approach is to mitigate the "Inter-domain Covariate Shift" with a carefully selected training batch from a mixture of domain samples, a deep batch-normalized residual network, and a modified multi-task learning objective. Our approach is complementary to existing domain-adaptation techniques and can be applied to other dense per-pixel pose estimation problems.
The Many Faces of Robustness: A Critical Analysis of Out-of-Distribution Generalization
Jun 29, 2020
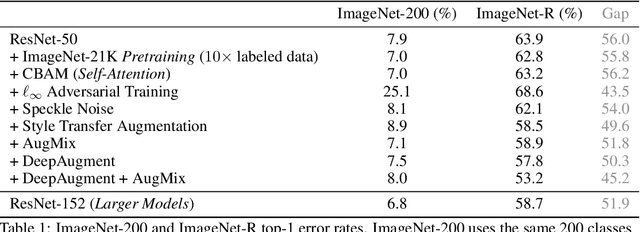

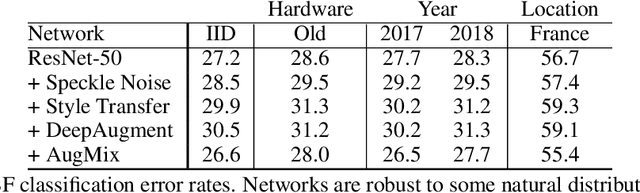
We introduce three new robustness benchmarks consisting of naturally occurring distribution changes in image style, geographic location, camera operation, and more. Using our benchmarks, we take stock of previously proposed hypotheses for out-of-distribution robustness and put them to the test. We find that using larger models and synthetic data augmentation can improve robustness on real-world distribution shifts, contrary to claims in prior work. Motivated by this, we introduce a new data augmentation method which advances the state-of-the-art and outperforms models pretrained with 1000x more labeled data. We find that some methods consistently help with distribution shifts in texture and local image statistics, but these methods do not help with some other distribution shifts like geographic changes. We conclude that future research must study multiple distribution shifts simultaneously.
BlazePose: On-device Real-time Body Pose tracking
Jun 17, 2020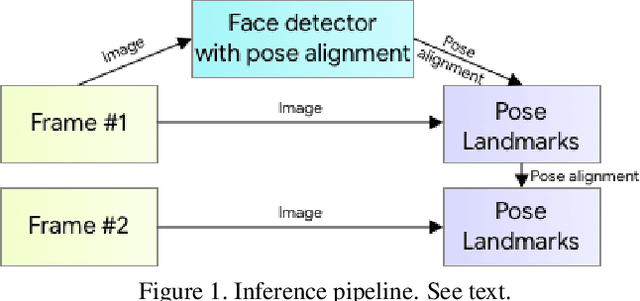
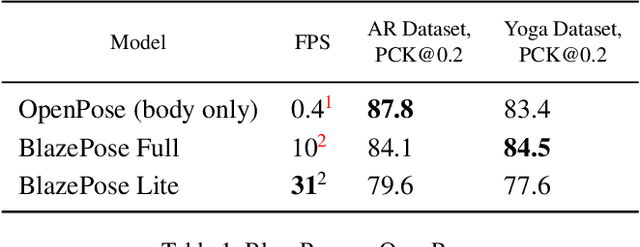
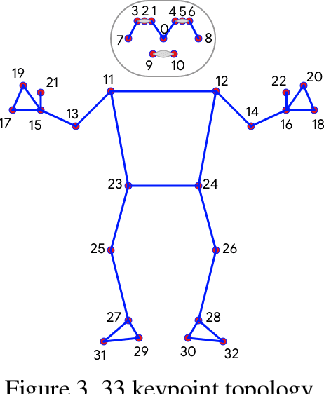
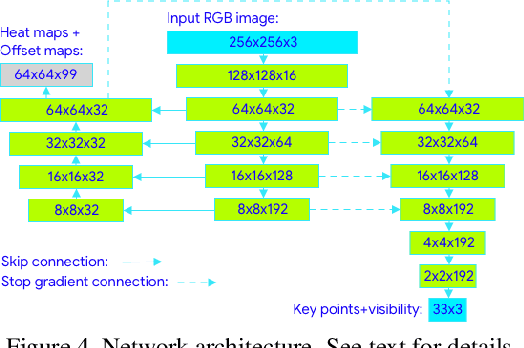
We present BlazePose, a lightweight convolutional neural network architecture for human pose estimation that is tailored for real-time inference on mobile devices. During inference, the network produces 33 body keypoints for a single person and runs at over 30 frames per second on a Pixel 2 phone. This makes it particularly suited to real-time use cases like fitness tracking and sign language recognition. Our main contributions include a novel body pose tracking solution and a lightweight body pose estimation neural network that uses both heatmaps and regression to keypoint coordinates.