 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConformal Transformations for Symmetric Power Transformers
Mar 05, 2025Transformers with linear attention offer significant computational advantages over softmax-based transformers but often suffer from degraded performance. The symmetric power (sympow) transformer, a particular type of linear transformer, addresses some of this performance gap by leveraging symmetric tensor embeddings, achieving comparable performance to softmax transformers. However, the finite capacity of the recurrent state in sympow transformers limits their ability to retain information, leading to performance degradation when scaling the training or evaluation context length. To address this issue, we propose the conformal-sympow transformer, which dynamically frees up capacity using data-dependent multiplicative gating and adaptively stores information using data-dependent rotary embeddings. Preliminary experiments on the LongCrawl64 dataset demonstrate that conformal-sympow overcomes the limitations of sympow transformers, achieving robust performance across scaled training and evaluation contexts.
The Importance of Pessimism in Fixed-Dataset Policy Optimization
Oct 04, 2020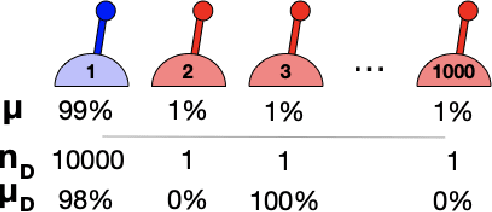
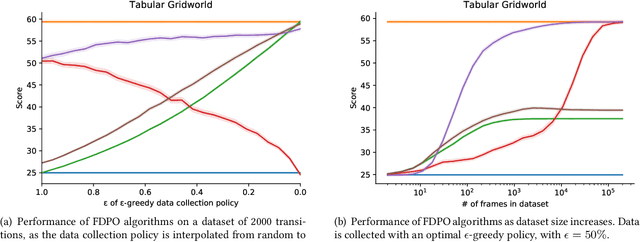
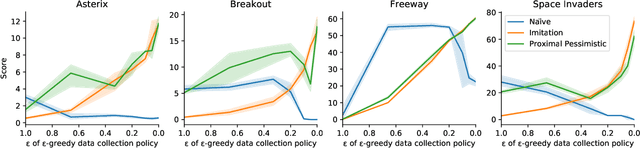
We study worst-case guarantees on the expected return of fixed-dataset policy optimization algorithms. Our core contribution is a unified conceptual and mathematical framework for the study of algorithms in this regime. This analysis reveals that for naive approaches, the possibility of erroneous value overestimation leads to a difficult-to-satisfy requirement: in order to guarantee that we select a policy which is near-optimal, we may need the dataset to be informative of the value of every policy. To avoid this, algorithms can follow the pessimism principle, which states that we should choose the policy which acts optimally in the worst possible world. We show why pessimistic algorithms can achieve good performance even when the dataset is not informative of every policy, and derive families of algorithms which follow this principle. These theoretical findings are validated by experiments on a tabular gridworld, and deep learning experiments on four MinAtar environments.
DeepMDP: Learning Continuous Latent Space Models for Representation Learning
Jun 06, 2019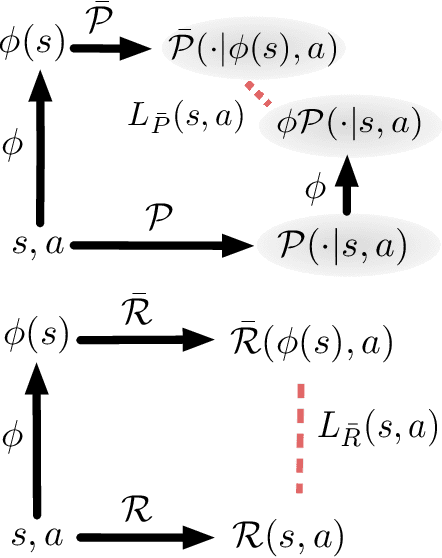


Many reinforcement learning (RL) tasks provide the agent with high-dimensional observations that can be simplified into low-dimensional continuous states. To formalize this process, we introduce the concept of a DeepMDP, a parameterized latent space model that is trained via the minimization of two tractable losses: prediction of rewards and prediction of the distribution over next latent states. We show that the optimization of these objectives guarantees (1) the quality of the latent space as a representation of the state space and (2) the quality of the DeepMDP as a model of the environment. We connect these results to prior work in the bisimulation literature, and explore the use of a variety of metrics. Our theoretical findings are substantiated by the experimental result that a trained DeepMDP recovers the latent structure underlying high-dimensional observations on a synthetic environment. Finally, we show that learning a DeepMDP as an auxiliary task in the Atari 2600 domain leads to large performance improvements over model-free RL.
Meta-Dataset: A Dataset of Datasets for Learning to Learn from Few Examples
Mar 07, 2019
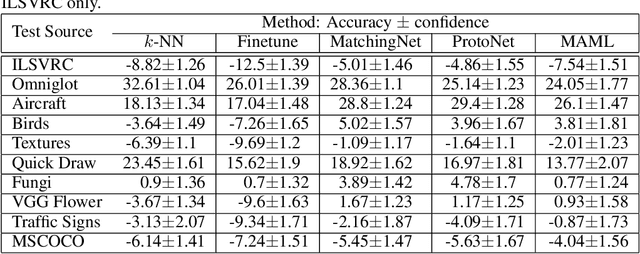

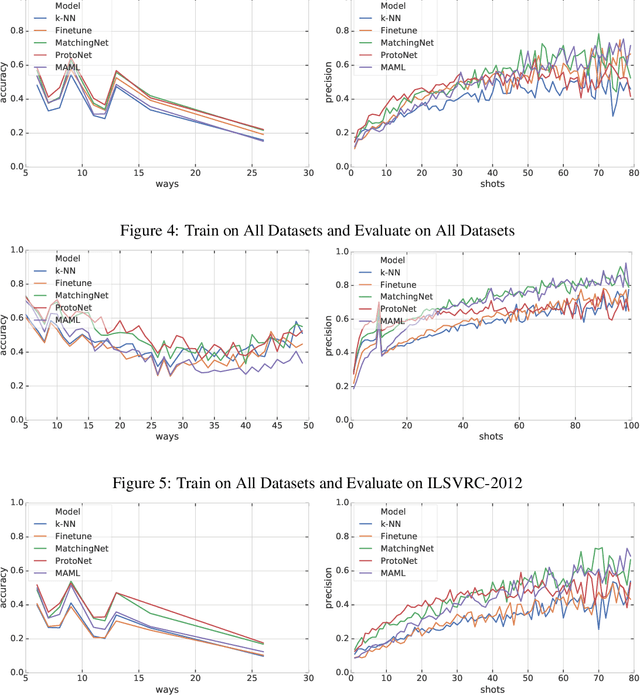
Few-shot classification refers to learning a classifier for new classes given only a few examples. While a plethora of models have emerged to tackle this recently, we find the current procedure and datasets that are used to systematically assess progress in this setting lacking. To address this, we propose Meta-Dataset: a new benchmark for training and evaluating few-shot classifiers that is large-scale, consists of multiple datasets, and presents more natural and realistic tasks. The aim is to measure the ability of state-of-the-art models to leverage diverse sources of data to achieve higher generalization, and to evaluate that generalization ability in a more challenging setting. We additionally measure robustness of current methods to variations in the number of available examples and the number of classes. Finally our extensive empirical evaluation leads us to identify weaknesses in Prototypical Networks and MAML, two popular few-shot classification methods, and to propose a new method, Proto-MAML, which achieves improved performance on our benchmark.
Hyperbolic Discounting and Learning over Multiple Horizons
Feb 28, 2019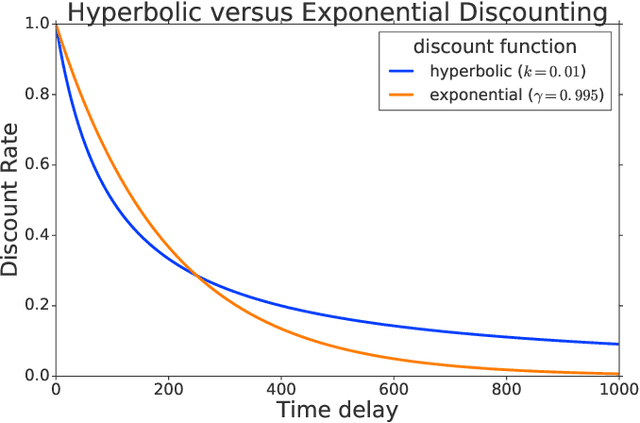

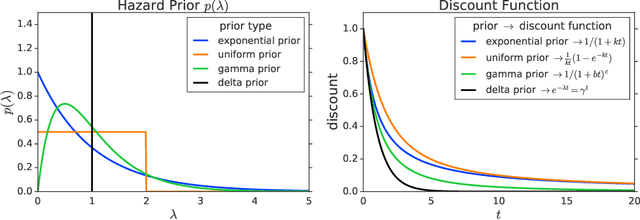
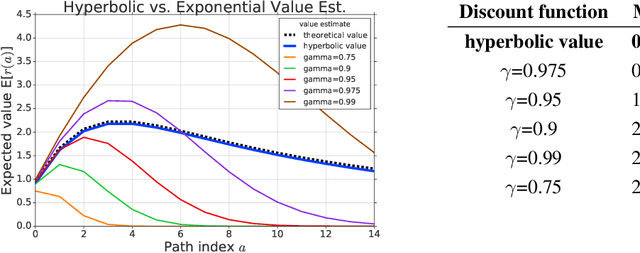
Reinforcement learning (RL) typically defines a discount factor as part of the Markov Decision Process. The discount factor values future rewards by an exponential scheme that leads to theoretical convergence guarantees of the Bellman equation. However, evidence from psychology, economics and neuroscience suggests that humans and animals instead have hyperbolic time-preferences. In this work we revisit the fundamentals of discounting in RL and bridge this disconnect by implementing an RL agent that acts via hyperbolic discounting. We demonstrate that a simple approach approximates hyperbolic discount functions while still using familiar temporal-difference learning techniques in RL. Additionally, and independent of hyperbolic discounting, we make a surprising discovery that simultaneously learning value functions over multiple time-horizons is an effective auxiliary task which often improves over a strong value-based RL agent, Rainbow.
Off-Policy Deep Reinforcement Learning by Bootstrapping the Covariate Shift
Jan 27, 2019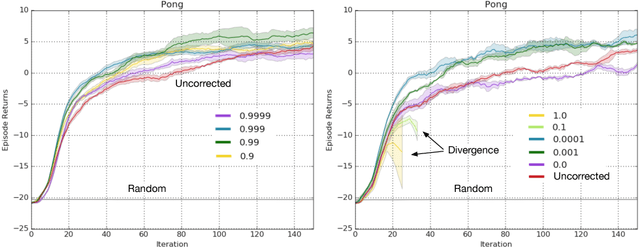


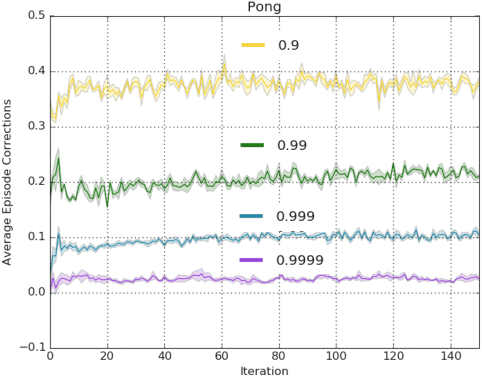
In this paper we revisit the method of off-policy corrections for reinforcement learning (COP-TD) pioneered by Hallak et al. (2017). Under this method, online updates to the value function are reweighted to avoid divergence issues typical of off-policy learning. While Hallak et al.'s solution is appealing, it cannot easily be transferred to nonlinear function approximation. First, it requires a projection step onto the probability simplex; second, even though the operator describing the expected behavior of the off-policy learning algorithm is convergent, it is not known to be a contraction mapping, and hence, may be more unstable in practice. We address these two issues by introducing a discount factor into COP-TD. We analyze the behavior of discounted COP-TD and find it better behaved from a theoretical perspective. We also propose an alternative soft normalization penalty that can be minimized online and obviates the need for an explicit projection step. We complement our analysis with an empirical evaluation of the two techniques in an off-policy setting on the game Pong from the Atari domain where we find discounted COP-TD to be better behaved in practice than the soft normalization penalty. Finally, we perform a more extensive evaluation of discounted COP-TD in 5 games of the Atari domain, where we find performance gains for our approach.
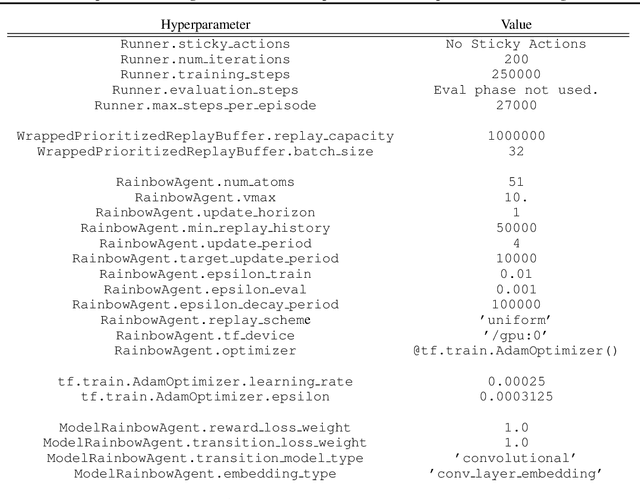
Dopamine: A Research Framework for Deep Reinforcement Learning
Dec 14, 2018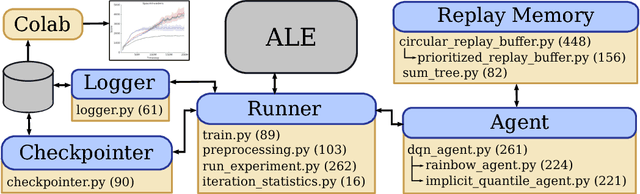
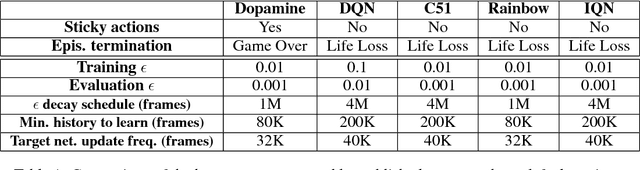

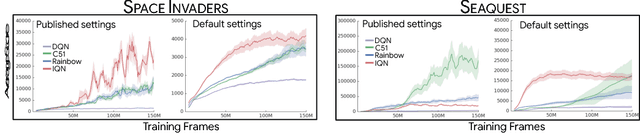
Deep reinforcement learning (deep RL) research has grown significantly in recent years. A number of software offerings now exist that provide stable, comprehensive implementations for benchmarking. At the same time, recent deep RL research has become more diverse in its goals. In this paper we introduce Dopamine, a new research framework for deep RL that aims to support some of that diversity. Dopamine is open-source, TensorFlow-based, and provides compact and reliable implementations of some state-of-the-art deep RL agents. We complement this offering with a taxonomy of the different research objectives in deep RL research. While by no means exhaustive, our analysis highlights the heterogeneity of research in the field, and the value of frameworks such as ours.