 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeak, Read and Prompt: High-Fidelity Text-to-Speech with Minimal Supervision
Feb 07, 2023We introduce SPEAR-TTS, a multi-speaker text-to-speech (TTS) system that can be trained with minimal supervision. By combining two types of discrete speech representations, we cast TTS as a composition of two sequence-to-sequence tasks: from text to high-level semantic tokens (akin to "reading") and from semantic tokens to low-level acoustic tokens ("speaking"). Decoupling these two tasks enables training of the "speaking" module using abundant audio-only data, and unlocks the highly efficient combination of pretraining and backtranslation to reduce the need for parallel data when training the "reading" component. To control the speaker identity, we adopt example prompting, which allows SPEAR-TTS to generalize to unseen speakers using only a short sample of 3 seconds, without any explicit speaker representation or speaker-id labels. Our experiments demonstrate that SPEAR-TTS achieves a character error rate that is competitive with state-of-the-art methods using only 15 minutes of parallel data, while matching ground-truth speech in terms of naturalness and acoustic quality, as measured in subjective tests.
SingSong: Generating musical accompaniments from singing
Jan 30, 2023



We present SingSong, a system that generates instrumental music to accompany input vocals, potentially offering musicians and non-musicians alike an intuitive new way to create music featuring their own voice. To accomplish this, we build on recent developments in musical source separation and audio generation. Specifically, we apply a state-of-the-art source separation algorithm to a large corpus of music audio to produce aligned pairs of vocals and instrumental sources. Then, we adapt AudioLM (Borsos et al., 2022) -- a state-of-the-art approach for unconditional audio generation -- to be suitable for conditional "audio-to-audio" generation tasks, and train it on the source-separated (vocal, instrumental) pairs. In a pairwise comparison with the same vocal inputs, listeners expressed a significant preference for instrumentals generated by SingSong compared to those from a strong retrieval baseline. Sound examples at https://g.co/magenta/singsong
C3PO: Learning to Achieve Arbitrary Goals via Massively Entropic Pretraining
Nov 07, 2022



Given a particular embodiment, we propose a novel method (C3PO) that learns policies able to achieve any arbitrary position and pose. Such a policy would allow for easier control, and would be re-useable as a key building block for downstream tasks. The method is two-fold: First, we introduce a novel exploration algorithm that optimizes for uniform coverage, is able to discover a set of achievable states, and investigates its abilities in attaining both high coverage, and hard-to-discover states; Second, we leverage this set of achievable states as training data for a universal goal-achievement policy, a goal-based SAC variant. We demonstrate the trained policy's performance in achieving a large number of novel states. Finally, we showcase the influence of massive unsupervised training of a goal-achievement policy with state-of-the-art pose-based control of the Hopper, Walker, Halfcheetah, Humanoid and Ant embodiments.
Emergent Communication: Generalization and Overfitting in Lewis Games
Sep 30, 2022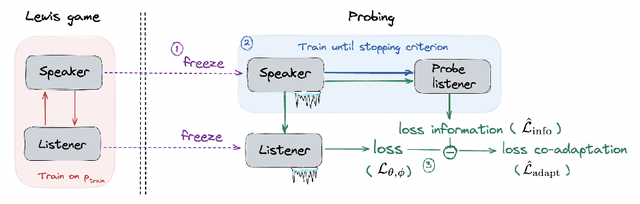

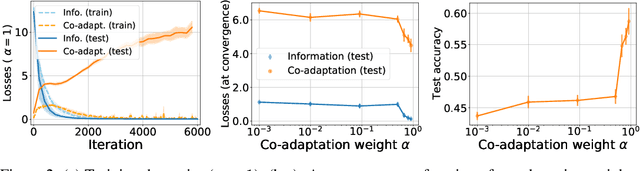

Lewis signaling games are a class of simple communication games for simulating the emergence of language. In these games, two agents must agree on a communication protocol in order to solve a cooperative task. Previous work has shown that agents trained to play this game with reinforcement learning tend to develop languages that display undesirable properties from a linguistic point of view (lack of generalization, lack of compositionality, etc). In this paper, we aim to provide better understanding of this phenomenon by analytically studying the learning problem in Lewis games. As a core contribution, we demonstrate that the standard objective in Lewis games can be decomposed in two components: a co-adaptation loss and an information loss. This decomposition enables us to surface two potential sources of overfitting, which we show may undermine the emergence of a structured communication protocol. In particular, when we control for overfitting on the co-adaptation loss, we recover desired properties in the emergent languages: they are more compositional and generalize better.
vec2text with Round-Trip Translations
Sep 14, 2022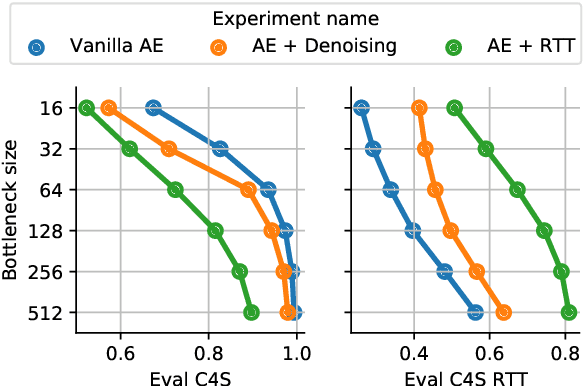

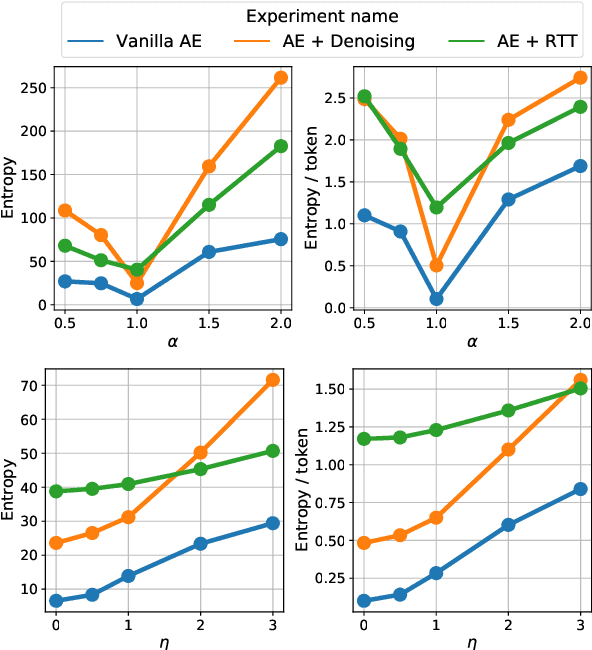

We investigate models that can generate arbitrary natural language text (e.g. all English sentences) from a bounded, convex and well-behaved control space. We call them universal vec2text models. Such models would allow making semantic decisions in the vector space (e.g. via reinforcement learning) while the natural language generation is handled by the vec2text model. We propose four desired properties: universality, diversity, fluency, and semantic structure, that such vec2text models should possess and we provide quantitative and qualitative methods to assess them. We implement a vec2text model by adding a bottleneck to a 250M parameters Transformer model and training it with an auto-encoding objective on 400M sentences (10B tokens) extracted from a massive web corpus. We propose a simple data augmentation technique based on round-trip translations and show in extensive experiments that the resulting vec2text model surprisingly leads to vector spaces that fulfill our four desired properties and that this model strongly outperforms both standard and denoising auto-encoders.
AudioLM: a Language Modeling Approach to Audio Generation
Sep 07, 2022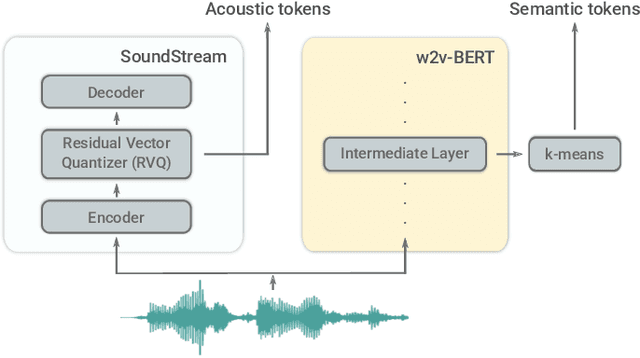


We introduce AudioLM, a framework for high-quality audio generation with long-term consistency. AudioLM maps the input audio to a sequence of discrete tokens and casts audio generation as a language modeling task in this representation space. We show how existing audio tokenizers provide different trade-offs between reconstruction quality and long-term structure, and we propose a hybrid tokenization scheme to achieve both objectives. Namely, we leverage the discretized activations of a masked language model pre-trained on audio to capture long-term structure and the discrete codes produced by a neural audio codec to achieve high-quality synthesis. By training on large corpora of raw audio waveforms, AudioLM learns to generate natural and coherent continuations given short prompts. When trained on speech, and without any transcript or annotation, AudioLM generates syntactically and semantically plausible speech continuations while also maintaining speaker identity and prosody for unseen speakers. Furthermore, we demonstrate how our approach extends beyond speech by generating coherent piano music continuations, despite being trained without any symbolic representation of music.
Learning Correlated Equilibria in Mean-Field Games
Aug 22, 2022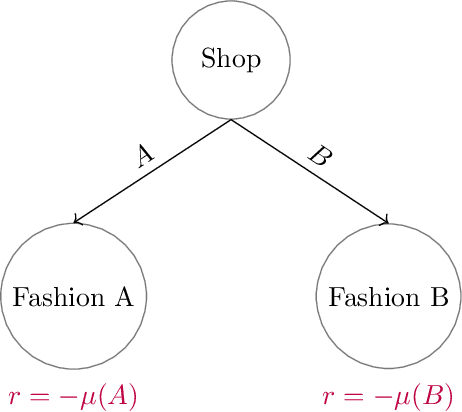
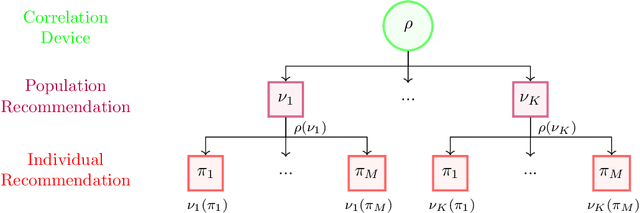
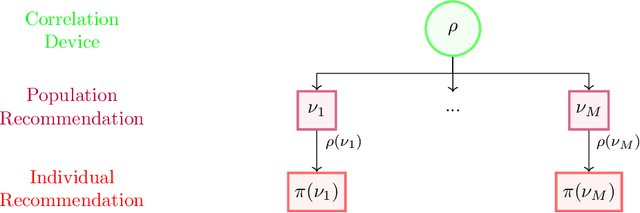
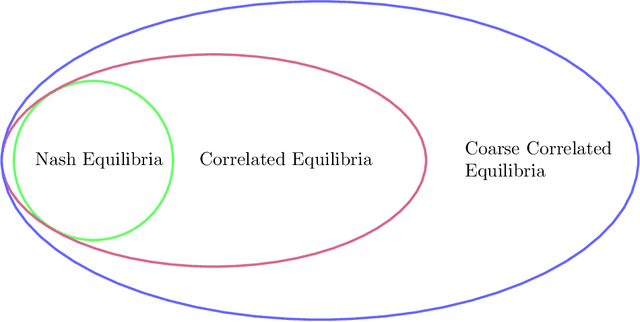
The designs of many large-scale systems today, from traffic routing environments to smart grids, rely on game-theoretic equilibrium concepts. However, as the size of an $N$-player game typically grows exponentially with $N$, standard game theoretic analysis becomes effectively infeasible beyond a low number of players. Recent approaches have gone around this limitation by instead considering Mean-Field games, an approximation of anonymous $N$-player games, where the number of players is infinite and the population's state distribution, instead of every individual player's state, is the object of interest. The practical computability of Mean-Field Nash equilibria, the most studied Mean-Field equilibrium to date, however, typically depends on beneficial non-generic structural properties such as monotonicity or contraction properties, which are required for known algorithms to converge. In this work, we provide an alternative route for studying Mean-Field games, by developing the concepts of Mean-Field correlated and coarse-correlated equilibria. We show that they can be efficiently learnt in \emph{all games}, without requiring any additional assumption on the structure of the game, using three classical algorithms. Furthermore, we establish correspondences between our notions and those already present in the literature, derive optimality bounds for the Mean-Field - $N$-player transition, and empirically demonstrate the convergence of these algorithms on simple games.
KL-Entropy-Regularized RL with a Generative Model is Minimax Optimal
May 27, 2022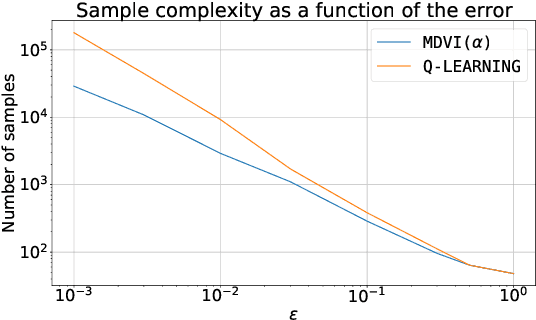

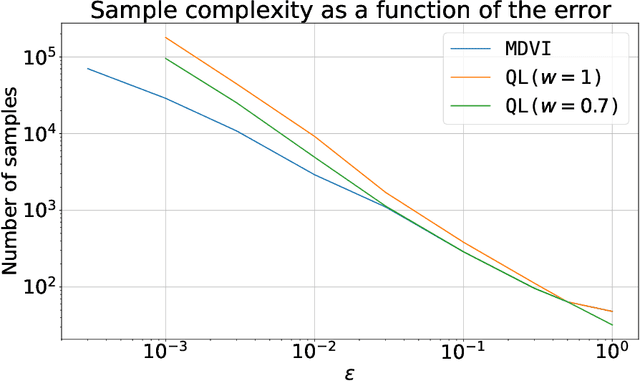
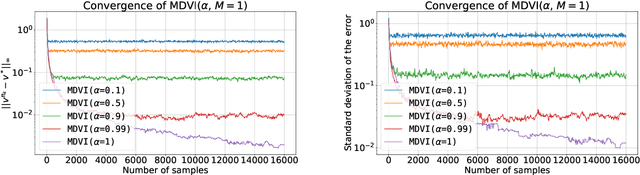
In this work, we consider and analyze the sample complexity of model-free reinforcement learning with a generative model. Particularly, we analyze mirror descent value iteration (MDVI) by Geist et al. (2019) and Vieillard et al. (2020a), which uses the Kullback-Leibler divergence and entropy regularization in its value and policy updates. Our analysis shows that it is nearly minimax-optimal for finding an $\varepsilon$-optimal policy when $\varepsilon$ is sufficiently small. This is the first theoretical result that demonstrates that a simple model-free algorithm without variance-reduction can be nearly minimax-optimal under the considered setting.
Learning Mean Field Games: A Survey
May 25, 2022
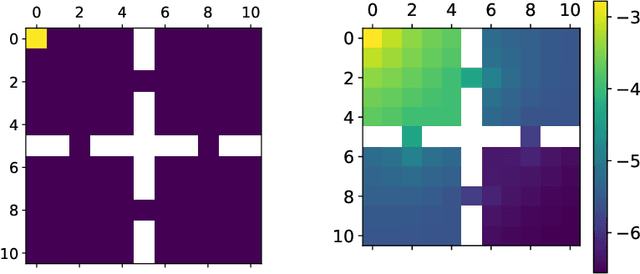
Non-cooperative and cooperative games with a very large number of players have many applications but remain generally intractable when the number of players increases. Introduced by Lasry and Lions, and Huang, Caines and Malham\'e, Mean Field Games (MFGs) rely on a mean-field approximation to allow the number of players to grow to infinity. Traditional methods for solving these games generally rely on solving partial or stochastic differential equations with a full knowledge of the model. Recently, Reinforcement Learning (RL) has appeared promising to solve complex problems. By combining MFGs and RL, we hope to solve games at a very large scale both in terms of population size and environment complexity. In this survey, we review the quickly growing recent literature on RL methods to learn Nash equilibria in MFGs. We first identify the most common settings (static, stationary, and evolutive). We then present a general framework for classical iterative methods (based on best-response computation or policy evaluation) to solve MFGs in an exact way. Building on these algorithms and the connection with Markov Decision Processes, we explain how RL can be used to learn MFG solutions in a model-free way. Last, we present numerical illustrations on a benchmark problem, and conclude with some perspectives.
Scalable Deep Reinforcement Learning Algorithms for Mean Field Games
Mar 22, 2022



Mean Field Games (MFGs) have been introduced to efficiently approximate games with very large populations of strategic agents. Recently, the question of learning equilibria in MFGs has gained momentum, particularly using model-free reinforcement learning (RL) methods. One limiting factor to further scale up using RL is that existing algorithms to solve MFGs require the mixing of approximated quantities such as strategies or $q$-values. This is non-trivial in the case of non-linear function approximation that enjoy good generalization properties, e.g. neural networks. We propose two methods to address this shortcoming. The first one learns a mixed strategy from distillation of historical data into a neural network and is applied to the Fictitious Play algorithm. The second one is an online mixing method based on regularization that does not require memorizing historical data or previous estimates. It is used to extend Online Mirror Descent. We demonstrate numerically that these methods efficiently enable the use of Deep RL algorithms to solve various MFGs. In addition, we show that these methods outperform SotA baselines from the literature.