 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocial Learning: Towards Collaborative Learning with Large Language Models
Dec 18, 2023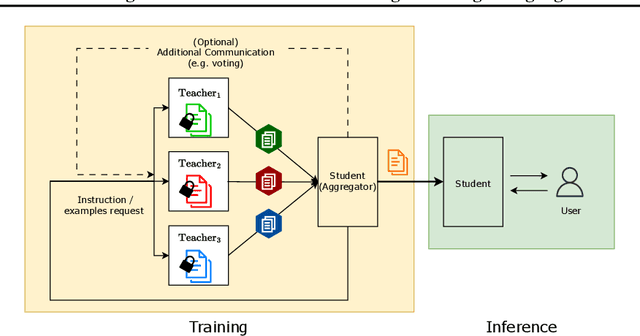
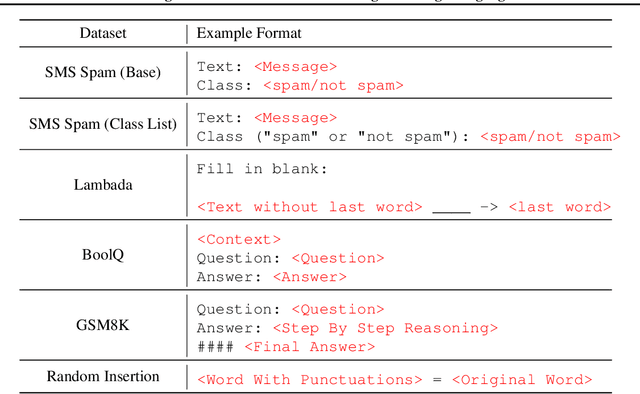

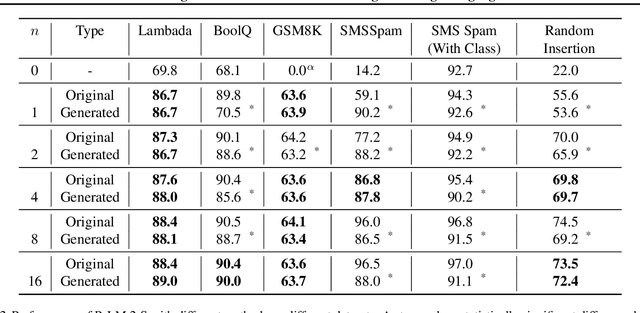
We introduce the framework of "social learning" in the context of large language models (LLMs), whereby models share knowledge with each other in a privacy-aware manner using natural language. We present and evaluate two approaches for knowledge transfer between LLMs. In the first scenario, we allow the model to generate abstract prompts aiming to teach the task. In our second approach, models transfer knowledge by generating synthetic examples. We evaluate these methods across diverse datasets and quantify memorization as a proxy for privacy loss. These techniques inspired by social learning yield promising results with low memorization of the original data. In particular, we show that performance using these methods is comparable to results with the use of original labels and prompts. Our work demonstrates the viability of social learning for LLMs, establishes baseline approaches and highlights several unexplored areas for future work.
AudioPaLM: A Large Language Model That Can Speak and Listen
Jun 22, 2023



We introduce AudioPaLM, a large language model for speech understanding and generation. AudioPaLM fuses text-based and speech-based language models, PaLM-2 [Anil et al., 2023] and AudioLM [Borsos et al., 2022], into a unified multimodal architecture that can process and generate text and speech with applications including speech recognition and speech-to-speech translation. AudioPaLM inherits the capability to preserve paralinguistic information such as speaker identity and intonation from AudioLM and the linguistic knowledge present only in text large language models such as PaLM-2. We demonstrate that initializing AudioPaLM with the weights of a text-only large language model improves speech processing, successfully leveraging the larger quantity of text training data used in pretraining to assist with the speech tasks. The resulting model significantly outperforms existing systems for speech translation tasks and has the ability to perform zero-shot speech-to-text translation for many languages for which input/target language combinations were not seen in training. AudioPaLM also demonstrates features of audio language models, such as transferring a voice across languages based on a short spoken prompt. We release examples of our method at https://google-research.github.io/seanet/audiopalm/examples
SoundStorm: Efficient Parallel Audio Generation
May 16, 2023We present SoundStorm, a model for efficient, non-autoregressive audio generation. SoundStorm receives as input the semantic tokens of AudioLM, and relies on bidirectional attention and confidence-based parallel decoding to generate the tokens of a neural audio codec. Compared to the autoregressive generation approach of AudioLM, our model produces audio of the same quality and with higher consistency in voice and acoustic conditions, while being two orders of magnitude faster. SoundStorm generates 30 seconds of audio in 0.5 seconds on a TPU-v4. We demonstrate the ability of our model to scale audio generation to longer sequences by synthesizing high-quality, natural dialogue segments, given a transcript annotated with speaker turns and a short prompt with the speakers' voices.
Speak, Read and Prompt: High-Fidelity Text-to-Speech with Minimal Supervision
Feb 07, 2023We introduce SPEAR-TTS, a multi-speaker text-to-speech (TTS) system that can be trained with minimal supervision. By combining two types of discrete speech representations, we cast TTS as a composition of two sequence-to-sequence tasks: from text to high-level semantic tokens (akin to "reading") and from semantic tokens to low-level acoustic tokens ("speaking"). Decoupling these two tasks enables training of the "speaking" module using abundant audio-only data, and unlocks the highly efficient combination of pretraining and backtranslation to reduce the need for parallel data when training the "reading" component. To control the speaker identity, we adopt example prompting, which allows SPEAR-TTS to generalize to unseen speakers using only a short sample of 3 seconds, without any explicit speaker representation or speaker-id labels. Our experiments demonstrate that SPEAR-TTS achieves a character error rate that is competitive with state-of-the-art methods using only 15 minutes of parallel data, while matching ground-truth speech in terms of naturalness and acoustic quality, as measured in subjective tests.
MusicLM: Generating Music From Text
Jan 26, 2023



We introduce MusicLM, a model generating high-fidelity music from text descriptions such as "a calming violin melody backed by a distorted guitar riff". MusicLM casts the process of conditional music generation as a hierarchical sequence-to-sequence modeling task, and it generates music at 24 kHz that remains consistent over several minutes. Our experiments show that MusicLM outperforms previous systems both in audio quality and adherence to the text description. Moreover, we demonstrate that MusicLM can be conditioned on both text and a melody in that it can transform whistled and hummed melodies according to the style described in a text caption. To support future research, we publicly release MusicCaps, a dataset composed of 5.5k music-text pairs, with rich text descriptions provided by human experts.
AudioLM: a Language Modeling Approach to Audio Generation
Sep 07, 2022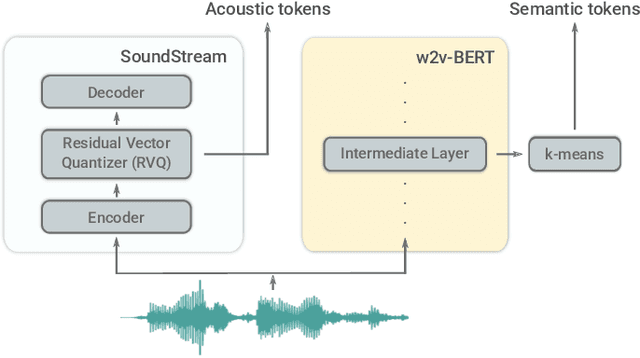

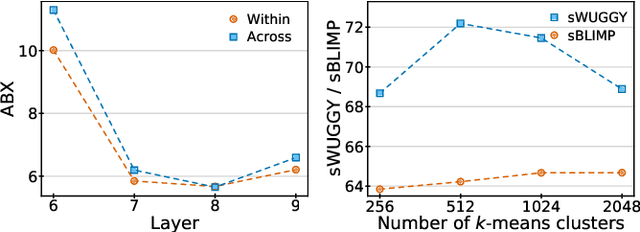

We introduce AudioLM, a framework for high-quality audio generation with long-term consistency. AudioLM maps the input audio to a sequence of discrete tokens and casts audio generation as a language modeling task in this representation space. We show how existing audio tokenizers provide different trade-offs between reconstruction quality and long-term structure, and we propose a hybrid tokenization scheme to achieve both objectives. Namely, we leverage the discretized activations of a masked language model pre-trained on audio to capture long-term structure and the discrete codes produced by a neural audio codec to achieve high-quality synthesis. By training on large corpora of raw audio waveforms, AudioLM learns to generate natural and coherent continuations given short prompts. When trained on speech, and without any transcript or annotation, AudioLM generates syntactically and semantically plausible speech continuations while also maintaining speaker identity and prosody for unseen speakers. Furthermore, we demonstrate how our approach extends beyond speech by generating coherent piano music continuations, despite being trained without any symbolic representation of music.
SpeechPainter: Text-conditioned Speech Inpainting
Feb 15, 2022
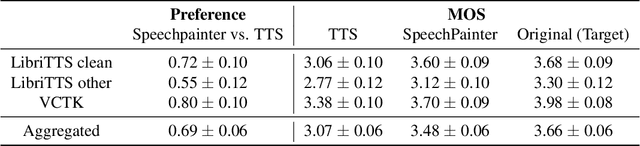
We propose SpeechPainter, a model for filling in gaps of up to one second in speech samples by leveraging an auxiliary textual input. We demonstrate that the model performs speech inpainting with the appropriate content, while maintaining speaker identity, prosody and recording environment conditions, and generalizing to unseen speakers. Our approach significantly outperforms baselines constructed using adaptive TTS, as judged by human raters in side-by-side preference and MOS tests.
Predicting Text Readability from Scrolling Interactions
May 13, 2021
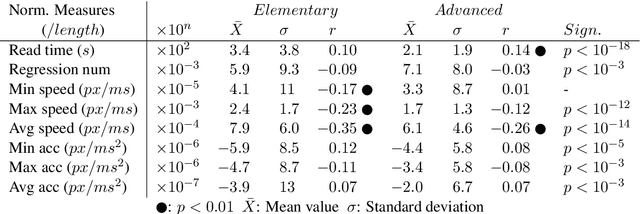


Judging the readability of text has many important applications, for instance when performing text simplification or when sourcing reading material for language learners. In this paper, we present a 518 participant study which investigates how scrolling behaviour relates to the readability of a text. We make our dataset publicly available and show that (1) there are statistically significant differences in the way readers interact with text depending on the text level, (2) such measures can be used to predict the readability of text, and (3) the background of a reader impacts their reading interactions and the factors contributing to text difficulty.
SPICE: Self-supervised Pitch Estimation
Oct 25, 2019
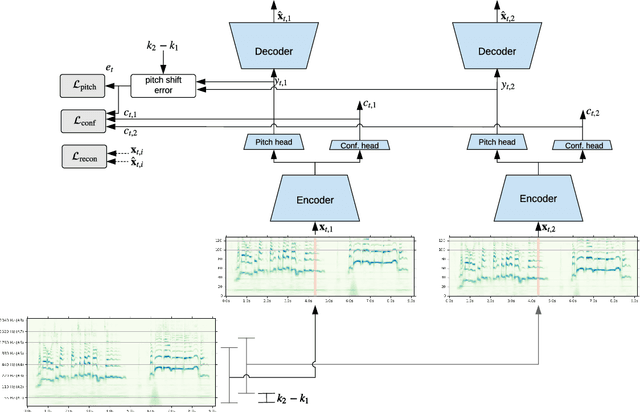
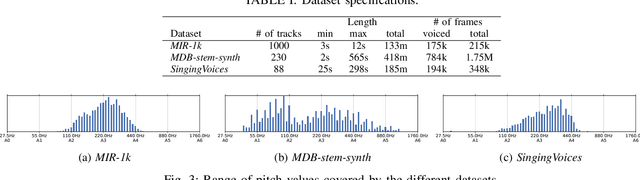
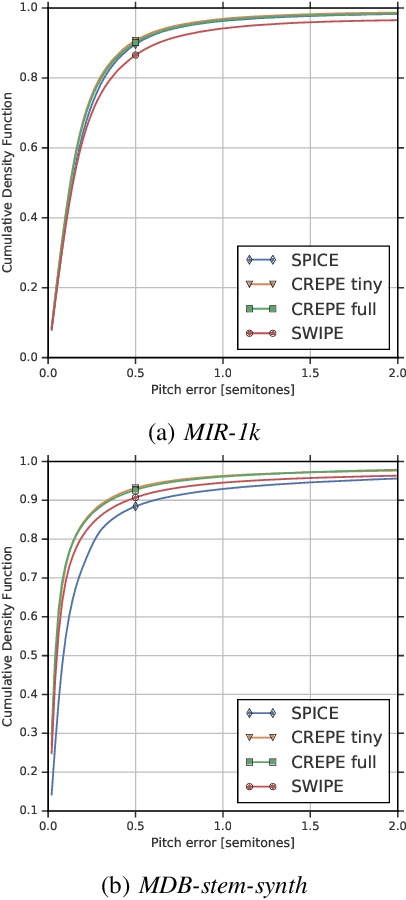
We propose a model to estimate the fundamental frequency in monophonic audio, often referred to as pitch estimation. We acknowledge the fact that obtaining ground truth annotations at the required temporal and frequency resolution is a particularly daunting task. Therefore, we propose to adopt a self-supervised learning technique, which is able to estimate (relative) pitch without any form of supervision. The key observation is that pitch shift maps to a simple translation when the audio signal is analysed through the lens of the constant-Q transform (CQT). We design a self-supervised task by feeding two shifted slices of the CQT to the same convolutional encoder, and require that the difference in the outputs is proportional to the corresponding difference in pitch. In addition, we introduce a small model head on top of the encoder, which is able to determine the confidence of the pitch estimate, so as to distinguish between voiced and unvoiced audio. Our results show that the proposed method is able to estimate pitch at a level of accuracy comparable to fully supervised models, both on clean and noisy audio samples, yet it does not require access to large labeled datasets