 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Faceted Interactivity Alignment in Full-Duplex Speech Models
Jun 09, 2026Full-duplex spoken dialogue models can listen and speak simultaneously, making them a promising architecture for natural conversation. However, current models are trained solely with supervised learning through token-level likelihood maximization, which does not directly optimize interaction-level behaviors, causing interactivity issues such as excessive silence and ill-timed turn-taking. Recent work has applied reinforcement learning (RL) to improve interactivity, but existing methods address only a limited set of interactive behaviors in their rewards. In this work, we propose a post-training alignment method that comprehensively improves the interactivity of full-duplex spoken dialogue models through RL. We address the four canonical axes of interactivity: pause handling, turn-taking, backchanneling, and user interruption. For each axis, we extract short audio segments from human conversation corpora and optimize the model with axis-specific reward functions. An extra LLM-based reward for response quality prevents semantic degradation. We apply our method to two open-source models, Moshi and PersonaPlex, demonstrating consistent improvements in interactivity on both offline evaluation with pre-recorded audio and real-time multi-turn dialogue evaluation.
MoshiRAG: Asynchronous Knowledge Retrieval for Full-Duplex Speech Language Models
Apr 14, 2026Speech-to-speech language models have recently emerged to enhance the naturalness of conversational AI. In particular, full-duplex models are distinguished by their real-time interactivity, including handling of pauses, interruptions, and backchannels. However, improving their factuality remains an open challenge. While scaling the model size could address this gap, it would make real-time inference prohibitively expensive. In this work, we propose MoshiRAG, a modular approach that combines a compact full-duplex interface with selective retrieval to access more powerful knowledge sources. Our asynchronous framework enables the model to identify knowledge-demanding queries and ground its responses in external information. By leveraging the natural temporal gap between response onset and the delivery of core information, the retrieval process can be completed while maintaining a natural conversation flow. With this approach, MoshiRAG achieves factuality comparable to the best publicly released non-duplex speech language models while preserving the interactivity inherent to full-duplex systems. Moreover, our flexible design supports plug-and-play retrieval methods without retraining and demonstrates strong performance on out-of-domain mathematical reasoning tasks.
Streaming Sequence-to-Sequence Learning with Delayed Streams Modeling
Sep 10, 2025We introduce Delayed Streams Modeling (DSM), a flexible formulation for streaming, multimodal sequence-to-sequence learning. Sequence-to-sequence generation is often cast in an offline manner, where the model consumes the complete input sequence before generating the first output timestep. Alternatively, streaming sequence-to-sequence rely on learning a policy for choosing when to advance on the input stream, or write to the output stream. DSM instead models already time-aligned streams with a decoder-only language model. By moving the alignment to a pre-processing step,and introducing appropriate delays between streams, DSM provides streaming inference of arbitrary output sequences, from any input combination, making it applicable to many sequence-to-sequence problems. In particular, given text and audio streams, automatic speech recognition (ASR) corresponds to the text stream being delayed, while the opposite gives a text-to-speech (TTS) model. We perform extensive experiments for these two major sequence-to-sequence tasks, showing that DSM provides state-of-the-art performance and latency while supporting arbitrary long sequences, being even competitive with offline baselines. Code, samples and demos are available at https://github.com/kyutai-labs/delayed-streams-modeling
Gemma 3 Technical Report
Mar 25, 2025We introduce Gemma 3, a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion parameters. This version introduces vision understanding abilities, a wider coverage of languages and longer context - at least 128K tokens. We also change the architecture of the model to reduce the KV-cache memory that tends to explode with long context. This is achieved by increasing the ratio of local to global attention layers, and keeping the span on local attention short. The Gemma 3 models are trained with distillation and achieve superior performance to Gemma 2 for both pre-trained and instruction finetuned versions. In particular, our novel post-training recipe significantly improves the math, chat, instruction-following and multilingual abilities, making Gemma3-4B-IT competitive with Gemma2-27B-IT and Gemma3-27B-IT comparable to Gemini-1.5-Pro across benchmarks. We release all our models to the community.
MAD Speech: Measures of Acoustic Diversity of Speech
Apr 16, 2024



Generative spoken language models produce speech in a wide range of voices, prosody, and recording conditions, seemingly approaching the diversity of natural speech. However, the extent to which generated speech is acoustically diverse remains unclear due to a lack of appropriate metrics. We address this gap by developing lightweight metrics of acoustic diversity, which we collectively refer to as MAD Speech. We focus on measuring five facets of acoustic diversity: voice, gender, emotion, accent, and background noise. We construct the metrics as a composition of specialized, per-facet embedding models and an aggregation function that measures diversity within the embedding space. Next, we build a series of datasets with a priori known diversity preferences for each facet. Using these datasets, we demonstrate that our proposed metrics achieve a stronger agreement with the ground-truth diversity than baselines. Finally, we showcase the applicability of our proposed metrics across several real-life evaluation scenarios. MAD Speech will be made publicly accessible.
AudioPaLM: A Large Language Model That Can Speak and Listen
Jun 22, 2023



We introduce AudioPaLM, a large language model for speech understanding and generation. AudioPaLM fuses text-based and speech-based language models, PaLM-2 [Anil et al., 2023] and AudioLM [Borsos et al., 2022], into a unified multimodal architecture that can process and generate text and speech with applications including speech recognition and speech-to-speech translation. AudioPaLM inherits the capability to preserve paralinguistic information such as speaker identity and intonation from AudioLM and the linguistic knowledge present only in text large language models such as PaLM-2. We demonstrate that initializing AudioPaLM with the weights of a text-only large language model improves speech processing, successfully leveraging the larger quantity of text training data used in pretraining to assist with the speech tasks. The resulting model significantly outperforms existing systems for speech translation tasks and has the ability to perform zero-shot speech-to-text translation for many languages for which input/target language combinations were not seen in training. AudioPaLM also demonstrates features of audio language models, such as transferring a voice across languages based on a short spoken prompt. We release examples of our method at https://google-research.github.io/seanet/audiopalm/examples
SoundStorm: Efficient Parallel Audio Generation
May 16, 2023We present SoundStorm, a model for efficient, non-autoregressive audio generation. SoundStorm receives as input the semantic tokens of AudioLM, and relies on bidirectional attention and confidence-based parallel decoding to generate the tokens of a neural audio codec. Compared to the autoregressive generation approach of AudioLM, our model produces audio of the same quality and with higher consistency in voice and acoustic conditions, while being two orders of magnitude faster. SoundStorm generates 30 seconds of audio in 0.5 seconds on a TPU-v4. We demonstrate the ability of our model to scale audio generation to longer sequences by synthesizing high-quality, natural dialogue segments, given a transcript annotated with speaker turns and a short prompt with the speakers' voices.
Speak, Read and Prompt: High-Fidelity Text-to-Speech with Minimal Supervision
Feb 07, 2023We introduce SPEAR-TTS, a multi-speaker text-to-speech (TTS) system that can be trained with minimal supervision. By combining two types of discrete speech representations, we cast TTS as a composition of two sequence-to-sequence tasks: from text to high-level semantic tokens (akin to "reading") and from semantic tokens to low-level acoustic tokens ("speaking"). Decoupling these two tasks enables training of the "speaking" module using abundant audio-only data, and unlocks the highly efficient combination of pretraining and backtranslation to reduce the need for parallel data when training the "reading" component. To control the speaker identity, we adopt example prompting, which allows SPEAR-TTS to generalize to unseen speakers using only a short sample of 3 seconds, without any explicit speaker representation or speaker-id labels. Our experiments demonstrate that SPEAR-TTS achieves a character error rate that is competitive with state-of-the-art methods using only 15 minutes of parallel data, while matching ground-truth speech in terms of naturalness and acoustic quality, as measured in subjective tests.
AudioLM: a Language Modeling Approach to Audio Generation
Sep 07, 2022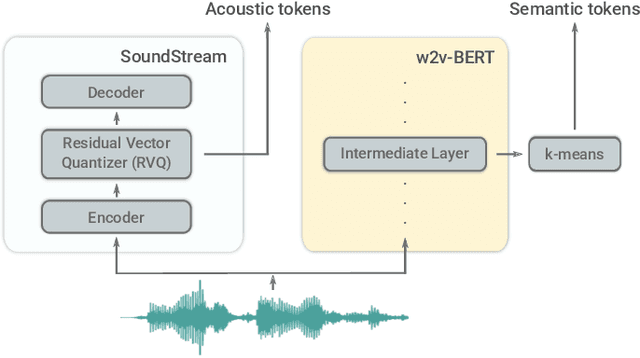

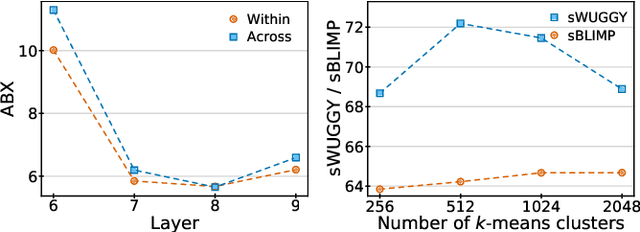

We introduce AudioLM, a framework for high-quality audio generation with long-term consistency. AudioLM maps the input audio to a sequence of discrete tokens and casts audio generation as a language modeling task in this representation space. We show how existing audio tokenizers provide different trade-offs between reconstruction quality and long-term structure, and we propose a hybrid tokenization scheme to achieve both objectives. Namely, we leverage the discretized activations of a masked language model pre-trained on audio to capture long-term structure and the discrete codes produced by a neural audio codec to achieve high-quality synthesis. By training on large corpora of raw audio waveforms, AudioLM learns to generate natural and coherent continuations given short prompts. When trained on speech, and without any transcript or annotation, AudioLM generates syntactically and semantically plausible speech continuations while also maintaining speaker identity and prosody for unseen speakers. Furthermore, we demonstrate how our approach extends beyond speech by generating coherent piano music continuations, despite being trained without any symbolic representation of music.
Generative Spoken Dialogue Language Modeling
Mar 30, 2022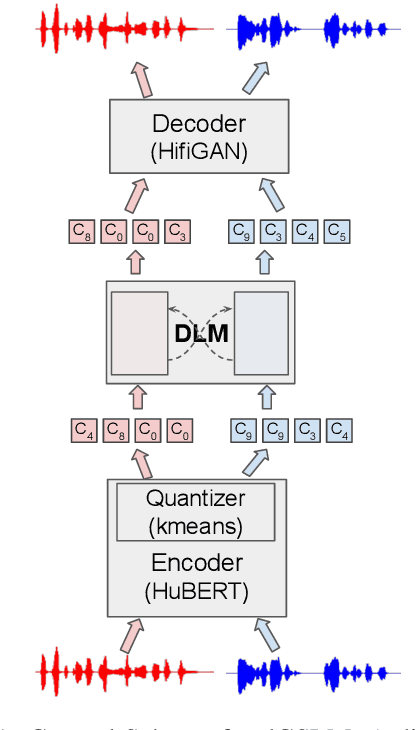
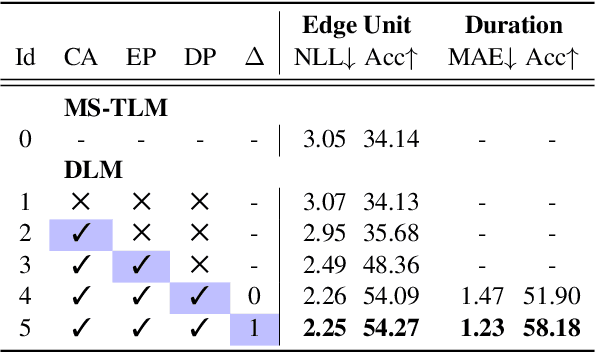
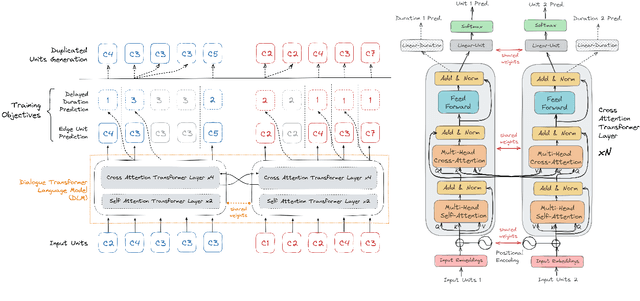
We introduce dGSLM, the first "textless" model able to generate audio samples of naturalistic spoken dialogues. It uses recent work on unsupervised spoken unit discovery coupled with a dual-tower transformer architecture with cross-attention trained on 2000 hours of two-channel raw conversational audio (Fisher dataset) without any text or labels. It is able to generate speech, laughter and other paralinguistic signals in the two channels simultaneously and reproduces naturalistic turn taking. Generation samples can be found at: https://speechbot.github.io/dgslm.