 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLive Music Models
Aug 06, 2025We introduce a new class of generative models for music called live music models that produce a continuous stream of music in real-time with synchronized user control. We release Magenta RealTime, an open-weights live music model that can be steered using text or audio prompts to control acoustic style. On automatic metrics of music quality, Magenta RealTime outperforms other open-weights music generation models, despite using fewer parameters and offering first-of-its-kind live generation capabilities. We also release Lyria RealTime, an API-based model with extended controls, offering access to our most powerful model with wide prompt coverage. These models demonstrate a new paradigm for AI-assisted music creation that emphasizes human-in-the-loop interaction for live music performance.
Diversity-Rewarded CFG Distillation
Oct 08, 2024Generative models are transforming creative domains such as music generation, with inference-time strategies like Classifier-Free Guidance (CFG) playing a crucial role. However, CFG doubles inference cost while limiting originality and diversity across generated contents. In this paper, we introduce diversity-rewarded CFG distillation, a novel finetuning procedure that distills the strengths of CFG while addressing its limitations. Our approach optimises two training objectives: (1) a distillation objective, encouraging the model alone (without CFG) to imitate the CFG-augmented predictions, and (2) an RL objective with a diversity reward, promoting the generation of diverse outputs for a given prompt. By finetuning, we learn model weights with the ability to generate high-quality and diverse outputs, without any inference overhead. This also unlocks the potential of weight-based model merging strategies: by interpolating between the weights of two models (the first focusing on quality, the second on diversity), we can control the quality-diversity trade-off at deployment time, and even further boost performance. We conduct extensive experiments on the MusicLM (Agostinelli et al., 2023) text-to-music generative model, where our approach surpasses CFG in terms of quality-diversity Pareto optimality. According to human evaluators, our finetuned-then-merged model generates samples with higher quality-diversity than the base model augmented with CFG. Explore our generations at https://google-research.github.io/seanet/musiclm/diverse_music/.
MAD Speech: Measures of Acoustic Diversity of Speech
Apr 16, 2024



Generative spoken language models produce speech in a wide range of voices, prosody, and recording conditions, seemingly approaching the diversity of natural speech. However, the extent to which generated speech is acoustically diverse remains unclear due to a lack of appropriate metrics. We address this gap by developing lightweight metrics of acoustic diversity, which we collectively refer to as MAD Speech. We focus on measuring five facets of acoustic diversity: voice, gender, emotion, accent, and background noise. We construct the metrics as a composition of specialized, per-facet embedding models and an aggregation function that measures diversity within the embedding space. Next, we build a series of datasets with a priori known diversity preferences for each facet. Using these datasets, we demonstrate that our proposed metrics achieve a stronger agreement with the ground-truth diversity than baselines. Finally, we showcase the applicability of our proposed metrics across several real-life evaluation scenarios. MAD Speech will be made publicly accessible.
MusicRL: Aligning Music Generation to Human Preferences
Feb 06, 2024We propose MusicRL, the first music generation system finetuned from human feedback. Appreciation of text-to-music models is particularly subjective since the concept of musicality as well as the specific intention behind a caption are user-dependent (e.g. a caption such as "upbeat work-out music" can map to a retro guitar solo or a techno pop beat). Not only this makes supervised training of such models challenging, but it also calls for integrating continuous human feedback in their post-deployment finetuning. MusicRL is a pretrained autoregressive MusicLM (Agostinelli et al., 2023) model of discrete audio tokens finetuned with reinforcement learning to maximise sequence-level rewards. We design reward functions related specifically to text-adherence and audio quality with the help from selected raters, and use those to finetune MusicLM into MusicRL-R. We deploy MusicLM to users and collect a substantial dataset comprising 300,000 pairwise preferences. Using Reinforcement Learning from Human Feedback (RLHF), we train MusicRL-U, the first text-to-music model that incorporates human feedback at scale. Human evaluations show that both MusicRL-R and MusicRL-U are preferred to the baseline. Ultimately, MusicRL-RU combines the two approaches and results in the best model according to human raters. Ablation studies shed light on the musical attributes influencing human preferences, indicating that text adherence and quality only account for a part of it. This underscores the prevalence of subjectivity in musical appreciation and calls for further involvement of human listeners in the finetuning of music generation models.
Brain2Music: Reconstructing Music from Human Brain Activity
Jul 20, 2023



The process of reconstructing experiences from human brain activity offers a unique lens into how the brain interprets and represents the world. In this paper, we introduce a method for reconstructing music from brain activity, captured using functional magnetic resonance imaging (fMRI). Our approach uses either music retrieval or the MusicLM music generation model conditioned on embeddings derived from fMRI data. The generated music resembles the musical stimuli that human subjects experienced, with respect to semantic properties like genre, instrumentation, and mood. We investigate the relationship between different components of MusicLM and brain activity through a voxel-wise encoding modeling analysis. Furthermore, we discuss which brain regions represent information derived from purely textual descriptions of music stimuli. We provide supplementary material including examples of the reconstructed music at https://google-research.github.io/seanet/brain2music
SingSong: Generating musical accompaniments from singing
Jan 30, 2023



We present SingSong, a system that generates instrumental music to accompany input vocals, potentially offering musicians and non-musicians alike an intuitive new way to create music featuring their own voice. To accomplish this, we build on recent developments in musical source separation and audio generation. Specifically, we apply a state-of-the-art source separation algorithm to a large corpus of music audio to produce aligned pairs of vocals and instrumental sources. Then, we adapt AudioLM (Borsos et al., 2022) -- a state-of-the-art approach for unconditional audio generation -- to be suitable for conditional "audio-to-audio" generation tasks, and train it on the source-separated (vocal, instrumental) pairs. In a pairwise comparison with the same vocal inputs, listeners expressed a significant preference for instrumentals generated by SingSong compared to those from a strong retrieval baseline. Sound examples at https://g.co/magenta/singsong
MusicLM: Generating Music From Text
Jan 26, 2023



We introduce MusicLM, a model generating high-fidelity music from text descriptions such as "a calming violin melody backed by a distorted guitar riff". MusicLM casts the process of conditional music generation as a hierarchical sequence-to-sequence modeling task, and it generates music at 24 kHz that remains consistent over several minutes. Our experiments show that MusicLM outperforms previous systems both in audio quality and adherence to the text description. Moreover, we demonstrate that MusicLM can be conditioned on both text and a melody in that it can transform whistled and hummed melodies according to the style described in a text caption. To support future research, we publicly release MusicCaps, a dataset composed of 5.5k music-text pairs, with rich text descriptions provided by human experts.
How stable are Transferability Metrics evaluations?
Apr 11, 2022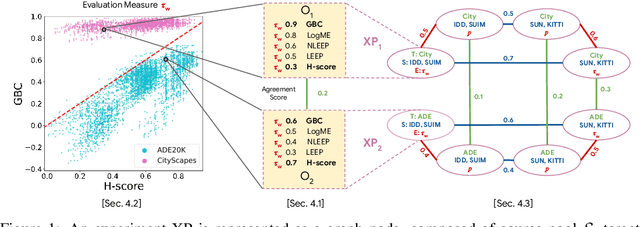
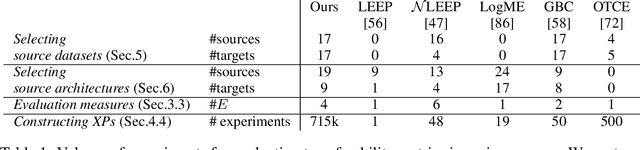
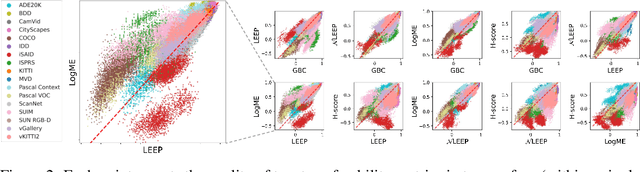
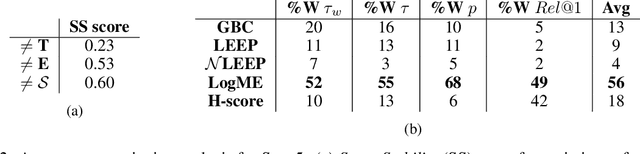
Transferability metrics is a maturing field with increasing interest, which aims at providing heuristics for selecting the most suitable source models to transfer to a given target dataset, without fine-tuning them all. However, existing works rely on custom experimental setups which differ across papers, leading to inconsistent conclusions about which transferability metrics work best. In this paper we conduct a large-scale study by systematically constructing a broad range of 715k experimental setup variations. We discover that even small variations to an experimental setup lead to different conclusions about the superiority of a transferability metric over another. Then we propose better evaluations by aggregating across many experiments, enabling to reach more stable conclusions. As a result, we reveal the superiority of LogME at selecting good source datasets to transfer from in a semantic segmentation scenario, NLEEP at selecting good source architectures in an image classification scenario, and GBC at determining which target task benefits most from a given source model. Yet, no single transferability metric works best in all scenarios.
Transferability Metrics for Selecting Source Model Ensembles
Nov 25, 2021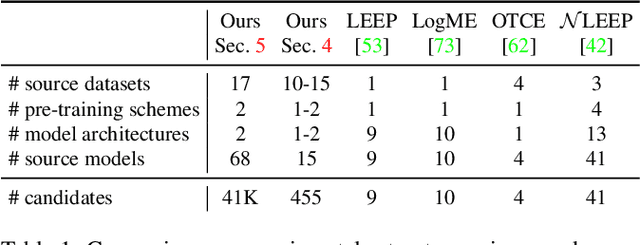
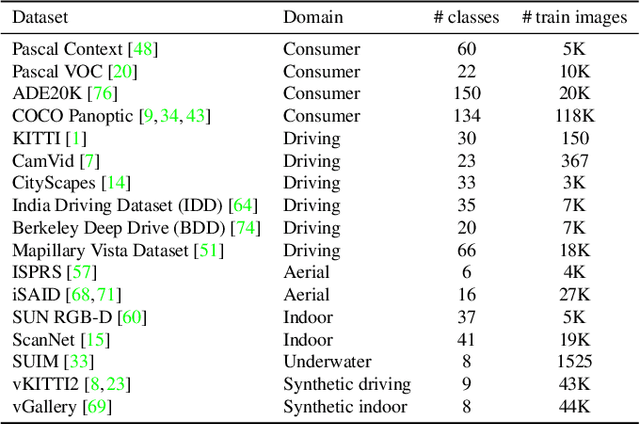
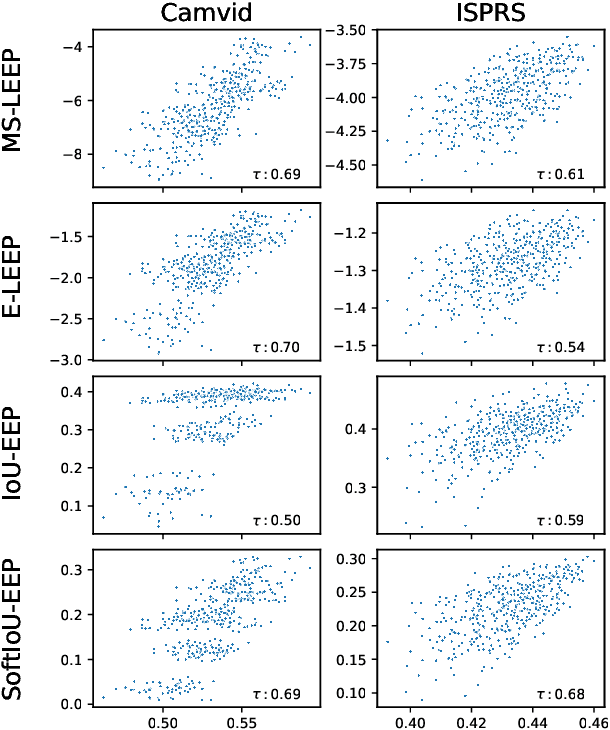
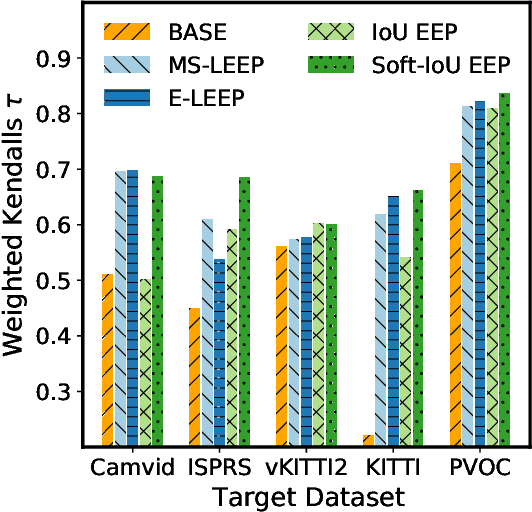
We address the problem of ensemble selection in transfer learning: Given a large pool of source models we want to select an ensemble of models which, after fine-tuning on the target training set, yields the best performance on the target test set. Since fine-tuning all possible ensembles is computationally prohibitive, we aim at predicting performance on the target dataset using a computationally efficient transferability metric. We propose several new transferability metrics designed for this task and evaluate them in a challenging and realistic transfer learning setup for semantic segmentation: we create a large and diverse pool of source models by considering 17 source datasets covering a wide variety of image domain, two different architectures, and two pre-training schemes. Given this pool, we then automatically select a subset to form an ensemble performing well on a given target dataset. We compare the ensemble selected by our method to two baselines which select a single source model, either (1) from the same pool as our method; or (2) from a pool containing large source models, each with similar capacity as an ensemble. Averaged over 17 target datasets, we outperform these baselines by 6.0% and 2.5% relative mean IoU, respectively.
Transferability Estimation using Bhattacharyya Class Separability
Nov 24, 2021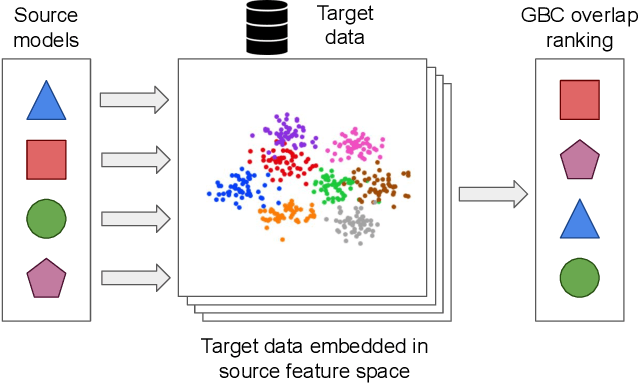

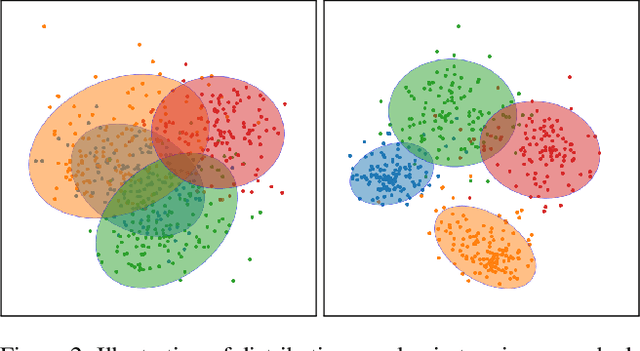
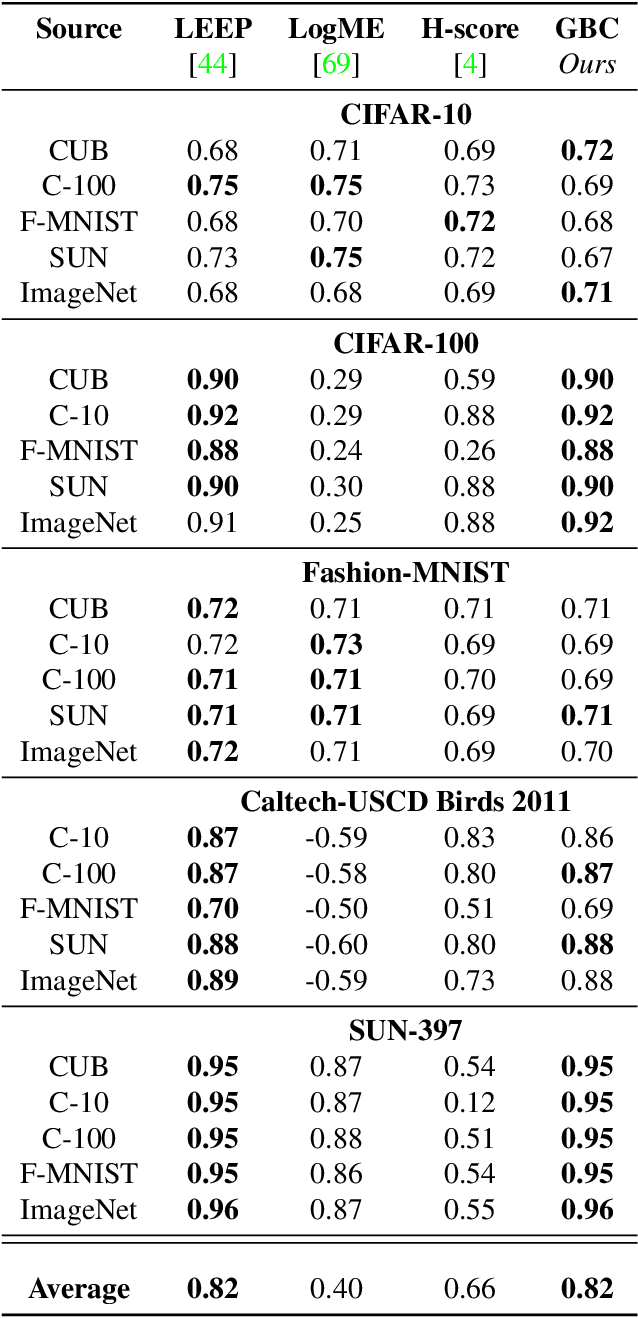
Transfer learning has become a popular method for leveraging pre-trained models in computer vision. However, without performing computationally expensive fine-tuning, it is difficult to quantify which pre-trained source models are suitable for a specific target task, or, conversely, to which tasks a pre-trained source model can be easily adapted to. In this work, we propose Gaussian Bhattacharyya Coefficient (GBC), a novel method for quantifying transferability between a source model and a target dataset. In a first step we embed all target images in the feature space defined by the source model, and represent them with per-class Gaussians. Then, we estimate their pairwise class separability using the Bhattacharyya coefficient, yielding a simple and effective measure of how well the source model transfers to the target task. We evaluate GBC on image classification tasks in the context of dataset and architecture selection. Further, we also perform experiments on the more complex semantic segmentation transferability estimation task. We demonstrate that GBC outperforms state-of-the-art transferability metrics on most evaluation criteria in the semantic segmentation settings, matches the performance of top methods for dataset transferability in image classification, and performs best on architecture selection problems for image classification.