 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-Scale Visual Speech Recognition
Oct 01, 2018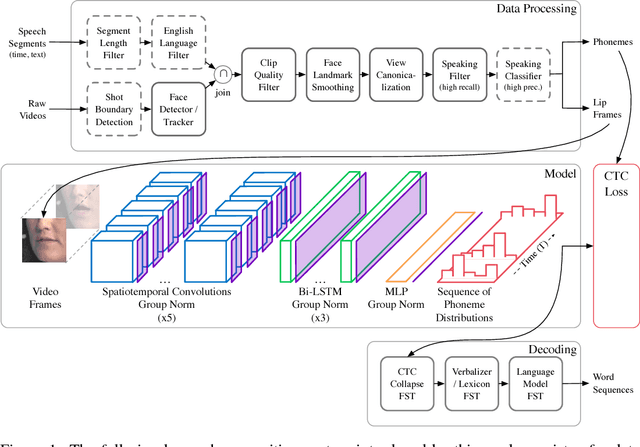
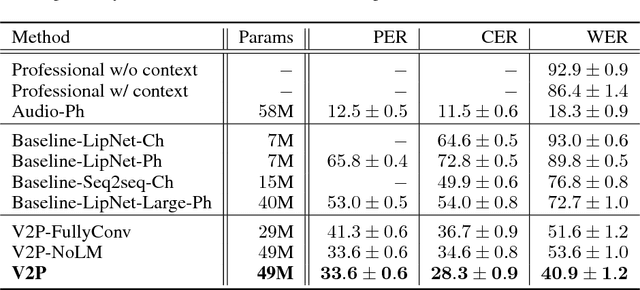


This work presents a scalable solution to open-vocabulary visual speech recognition. To achieve this, we constructed the largest existing visual speech recognition dataset, consisting of pairs of text and video clips of faces speaking (3,886 hours of video). In tandem, we designed and trained an integrated lipreading system, consisting of a video processing pipeline that maps raw video to stable videos of lips and sequences of phonemes, a scalable deep neural network that maps the lip videos to sequences of phoneme distributions, and a production-level speech decoder that outputs sequences of words. The proposed system achieves a word error rate (WER) of 40.9% as measured on a held-out set. In comparison, professional lipreaders achieve either 86.4% or 92.9% WER on the same dataset when having access to additional types of contextual information. Our approach significantly improves on other lipreading approaches, including variants of LipNet and of Watch, Attend, and Spell (WAS), which are only capable of 89.8% and 76.8% WER respectively.
Sample Efficient Adaptive Text-to-Speech
Sep 27, 2018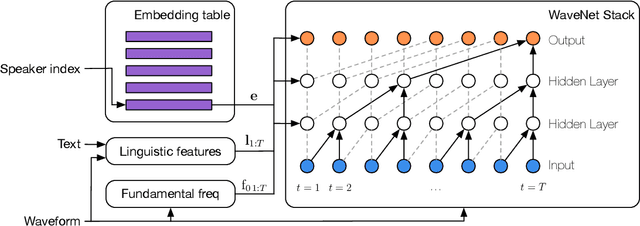
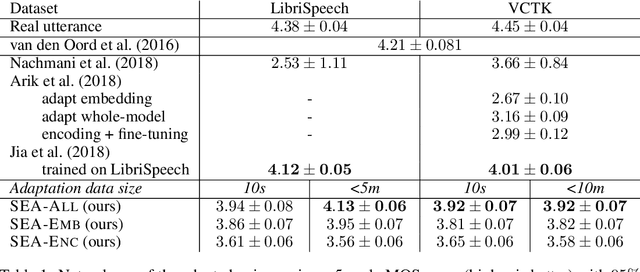
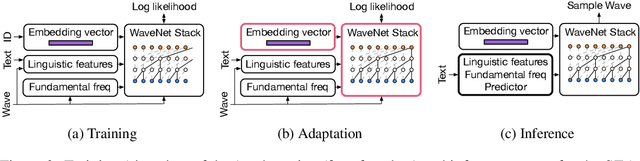
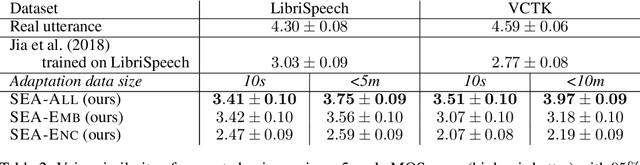
We present a meta-learning approach for adaptive text-to-speech (TTS) with few data. During training, we learn a multi-speaker model using a shared conditional WaveNet core and independent learned embeddings for each speaker. The aim of training is not to produce a neural network with fixed weights, which is then deployed as a TTS system. Instead, the aim is to produce a network that requires few data at deployment time to rapidly adapt to new speakers. We introduce and benchmark three strategies: (i) learning the speaker embedding while keeping the WaveNet core fixed, (ii) fine-tuning the entire architecture with stochastic gradient descent, and (iii) predicting the speaker embedding with a trained neural network encoder. The experiments show that these approaches are successful at adapting the multi-speaker neural network to new speakers, obtaining state-of-the-art results in both sample naturalness and voice similarity with merely a few minutes of audio data from new speakers.
Playing hard exploration games by watching YouTube
May 29, 2018

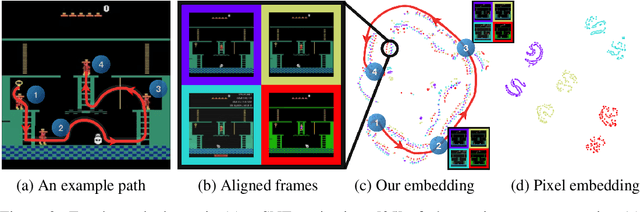
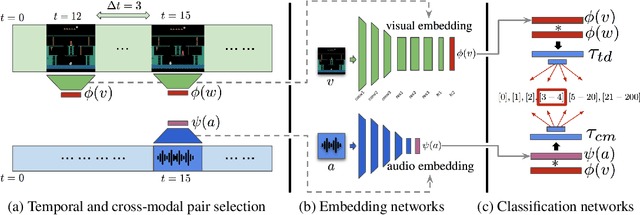
Deep reinforcement learning methods traditionally struggle with tasks where environment rewards are particularly sparse. One successful method of guiding exploration in these domains is to imitate trajectories provided by a human demonstrator. However, these demonstrations are typically collected under artificial conditions, i.e. with access to the agent's exact environment setup and the demonstrator's action and reward trajectories. Here we propose a two-stage method that overcomes these limitations by relying on noisy, unaligned footage without access to such data. First, we learn to map unaligned videos from multiple sources to a common representation using self-supervised objectives constructed over both time and modality (i.e. vision and sound). Second, we embed a single YouTube video in this representation to construct a reward function that encourages an agent to imitate human gameplay. This method of one-shot imitation allows our agent to convincingly exceed human-level performance on the infamously hard exploration games Montezuma's Revenge, Pitfall! and Private Eye for the first time, even if the agent is not presented with any environment rewards.
Reinforcement and Imitation Learning for Diverse Visuomotor Skills
May 27, 2018
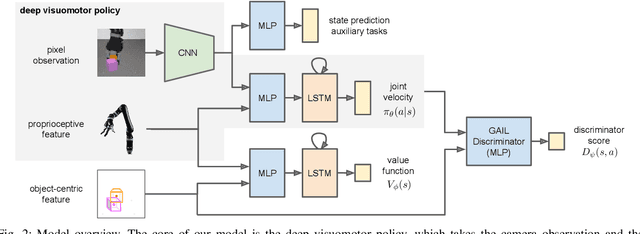
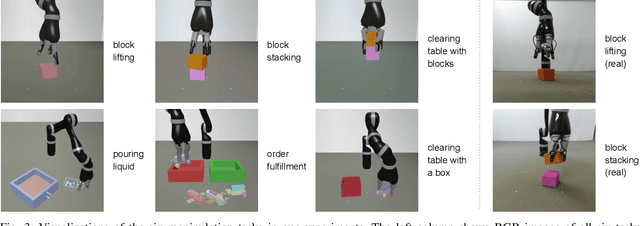
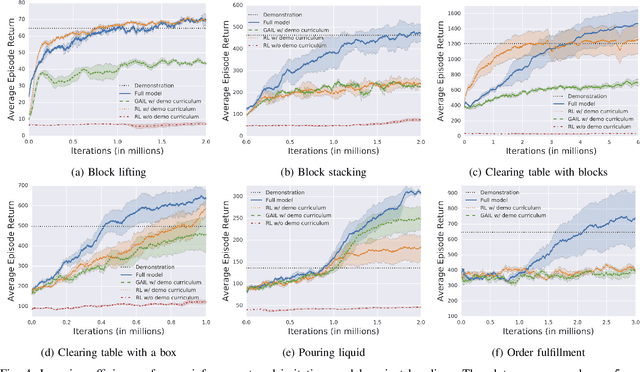
We propose a model-free deep reinforcement learning method that leverages a small amount of demonstration data to assist a reinforcement learning agent. We apply this approach to robotic manipulation tasks and train end-to-end visuomotor policies that map directly from RGB camera inputs to joint velocities. We demonstrate that our approach can solve a wide variety of visuomotor tasks, for which engineering a scripted controller would be laborious. In experiments, our reinforcement and imitation agent achieves significantly better performances than agents trained with reinforcement learning or imitation learning alone. We also illustrate that these policies, trained with large visual and dynamics variations, can achieve preliminary successes in zero-shot sim2real transfer. A brief visual description of this work can be viewed in https://youtu.be/EDl8SQUNjj0
Hyperbolic Attention Networks
May 24, 2018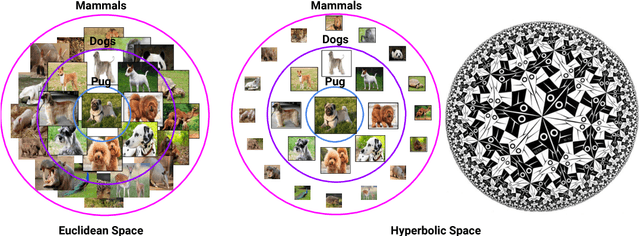
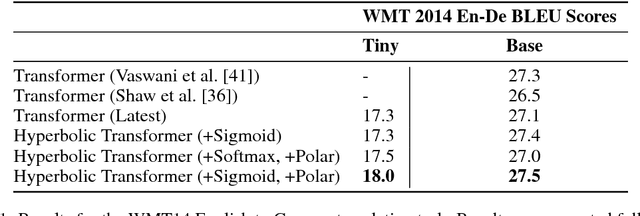
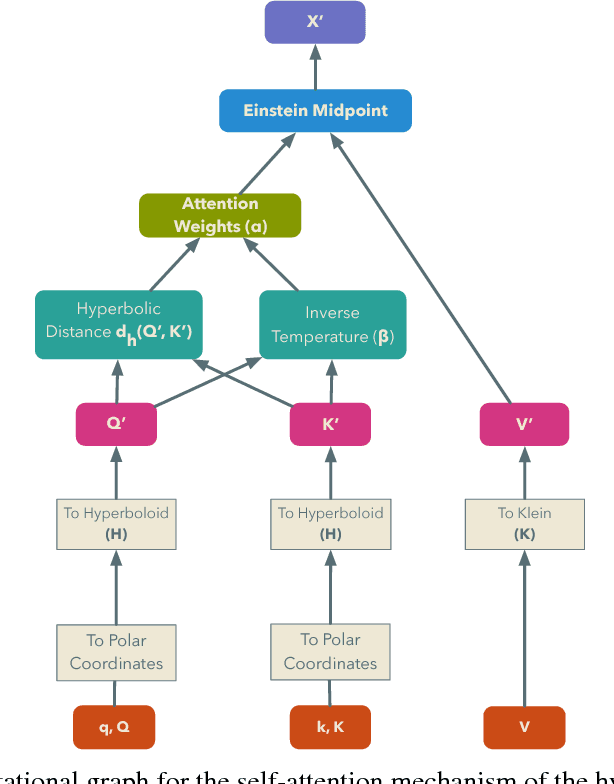
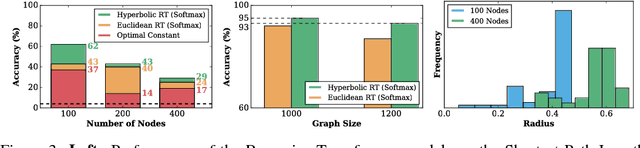
We introduce hyperbolic attention networks to endow neural networks with enough capacity to match the complexity of data with hierarchical and power-law structure. A few recent approaches have successfully demonstrated the benefits of imposing hyperbolic geometry on the parameters of shallow networks. We extend this line of work by imposing hyperbolic geometry on the activations of neural networks. This allows us to exploit hyperbolic geometry to reason about embeddings produced by deep networks. We achieve this by re-expressing the ubiquitous mechanism of soft attention in terms of operations defined for hyperboloid and Klein models. Our method shows improvements in terms of generalization on neural machine translation, learning on graphs and visual question answering tasks while keeping the neural representations compact.
Learning Awareness Models
Apr 17, 2018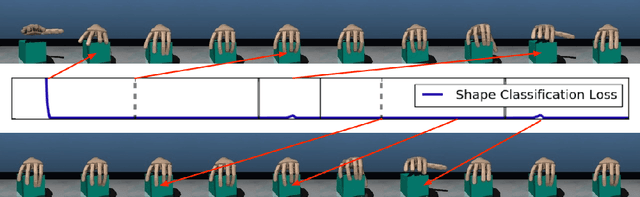

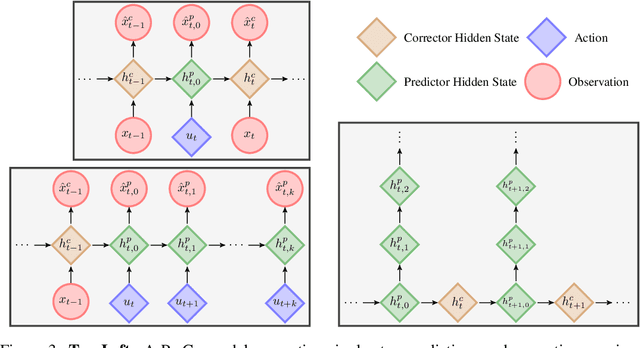
We consider the setting of an agent with a fixed body interacting with an unknown and uncertain external world. We show that models trained to predict proprioceptive information about the agent's body come to represent objects in the external world. In spite of being trained with only internally available signals, these dynamic body models come to represent external objects through the necessity of predicting their effects on the agent's own body. That is, the model learns holistic persistent representations of objects in the world, even though the only training signals are body signals. Our dynamics model is able to successfully predict distributions over 132 sensor readings over 100 steps into the future and we demonstrate that even when the body is no longer in contact with an object, the latent variables of the dynamics model continue to represent its shape. We show that active data collection by maximizing the entropy of predictions about the body---touch sensors, proprioception and vestibular information---leads to learning of dynamic models that show superior performance when used for control. We also collect data from a real robotic hand and show that the same models can be used to answer questions about properties of objects in the real world. Videos with qualitative results of our models are available at https://goo.gl/mZuqAV.
Compositional Obverter Communication Learning From Raw Visual Input
Apr 06, 2018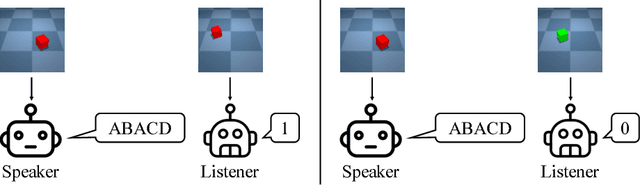
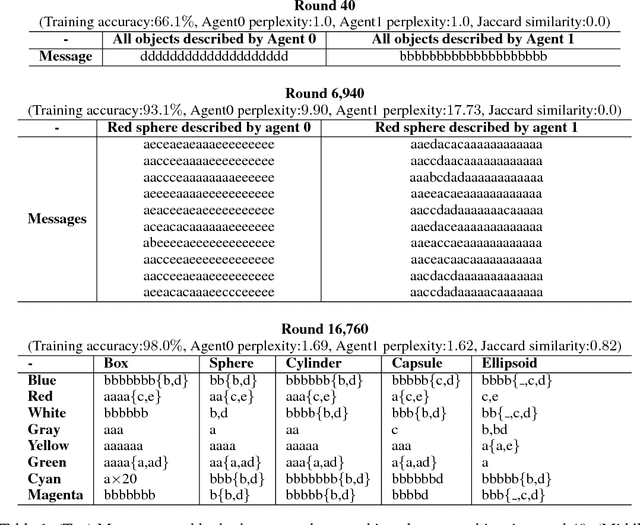

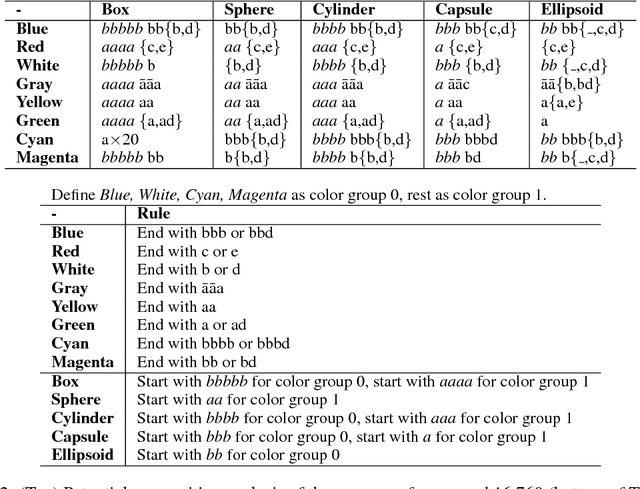
One of the distinguishing aspects of human language is its compositionality, which allows us to describe complex environments with limited vocabulary. Previously, it has been shown that neural network agents can learn to communicate in a highly structured, possibly compositional language based on disentangled input (e.g. hand- engineered features). Humans, however, do not learn to communicate based on well-summarized features. In this work, we train neural agents to simultaneously develop visual perception from raw image pixels, and learn to communicate with a sequence of discrete symbols. The agents play an image description game where the image contains factors such as colors and shapes. We train the agents using the obverter technique where an agent introspects to generate messages that maximize its own understanding. Through qualitative analysis, visualization and a zero-shot test, we show that the agents can develop, out of raw image pixels, a language with compositional properties, given a proper pressure from the environment.
Few-shot Autoregressive Density Estimation: Towards Learning to Learn Distributions
Feb 28, 2018
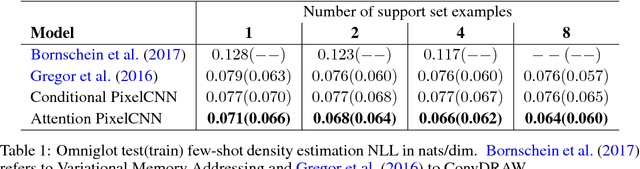
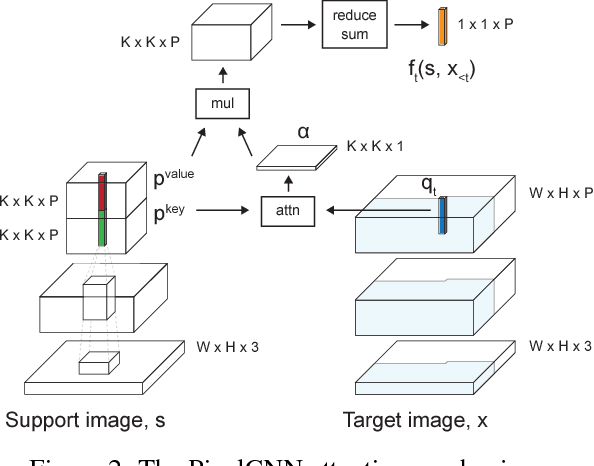
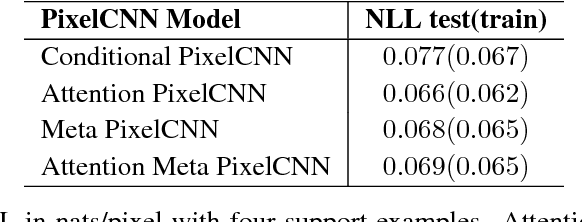
Deep autoregressive models have shown state-of-the-art performance in density estimation for natural images on large-scale datasets such as ImageNet. However, such models require many thousands of gradient-based weight updates and unique image examples for training. Ideally, the models would rapidly learn visual concepts from only a handful of examples, similar to the manner in which humans learns across many vision tasks. In this paper, we show how 1) neural attention and 2) meta learning techniques can be used in combination with autoregressive models to enable effective few-shot density estimation. Our proposed modifications to PixelCNN result in state-of-the art few-shot density estimation on the Omniglot dataset. Furthermore, we visualize the learned attention policy and find that it learns intuitive algorithms for simple tasks such as image mirroring on ImageNet and handwriting on Omniglot without supervision. Finally, we extend the model to natural images and demonstrate few-shot image generation on the Stanford Online Products dataset.
Cortical microcircuits as gated-recurrent neural networks
Jan 03, 2018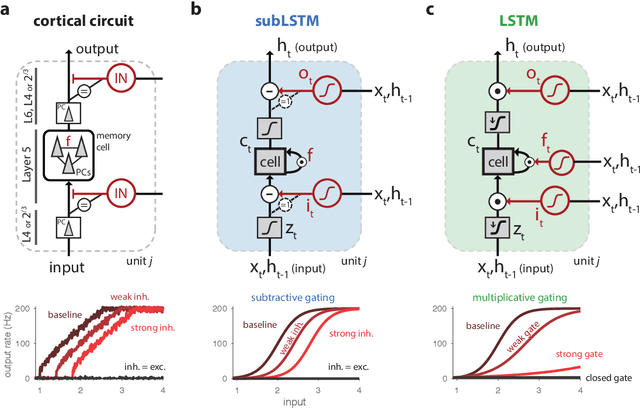
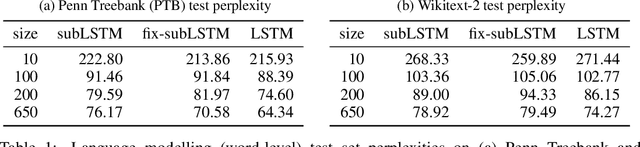
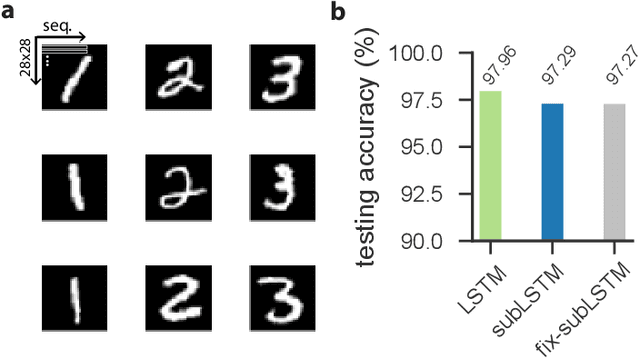
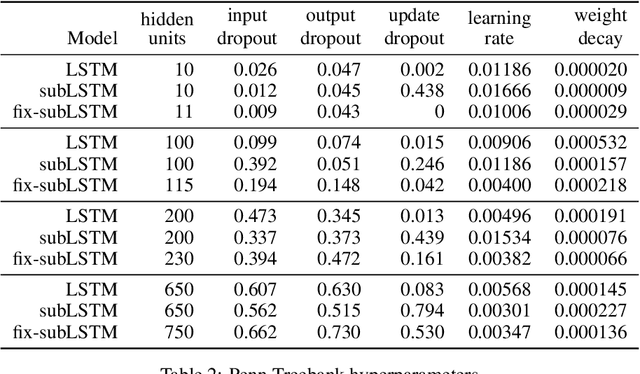
Cortical circuits exhibit intricate recurrent architectures that are remarkably similar across different brain areas. Such stereotyped structure suggests the existence of common computational principles. However, such principles have remained largely elusive. Inspired by gated-memory networks, namely long short-term memory networks (LSTMs), we introduce a recurrent neural network in which information is gated through inhibitory cells that are subtractive (subLSTM). We propose a natural mapping of subLSTMs onto known canonical excitatory-inhibitory cortical microcircuits. Our empirical evaluation across sequential image classification and language modelling tasks shows that subLSTM units can achieve similar performance to LSTM units. These results suggest that cortical circuits can be optimised to solve complex contextual problems and proposes a novel view on their computational function. Overall our work provides a step towards unifying recurrent networks as used in machine learning with their biological counterparts.
Learned Optimizers that Scale and Generalize
Sep 07, 2017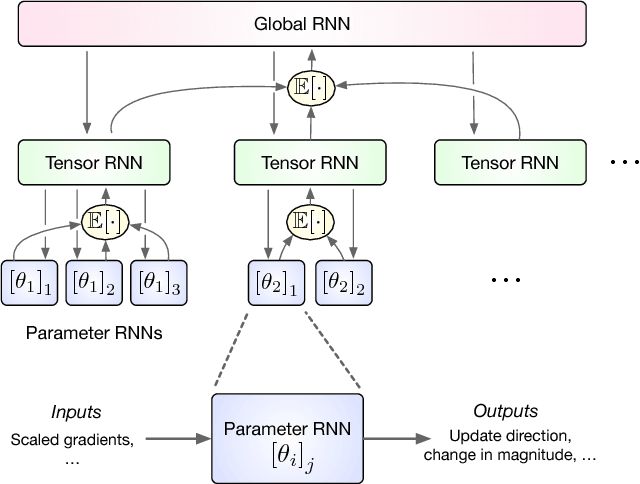
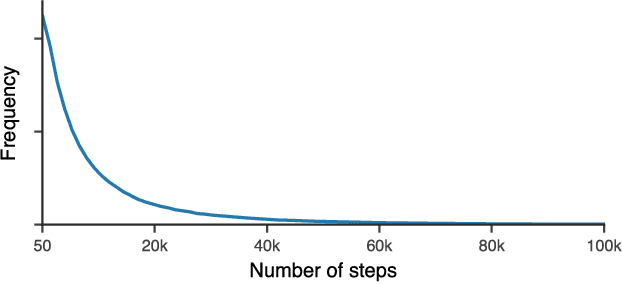
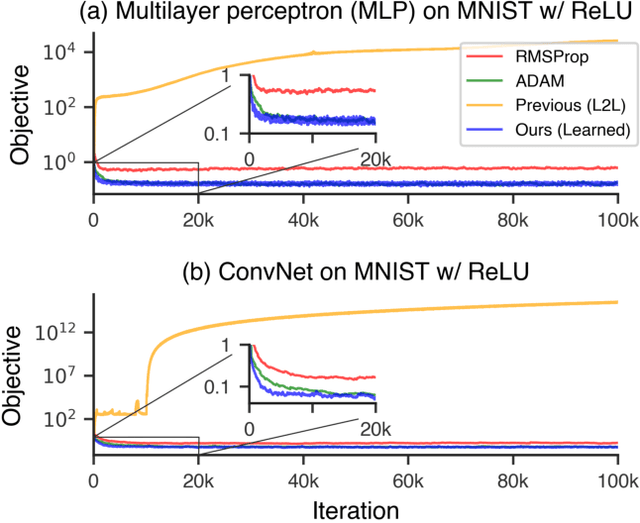
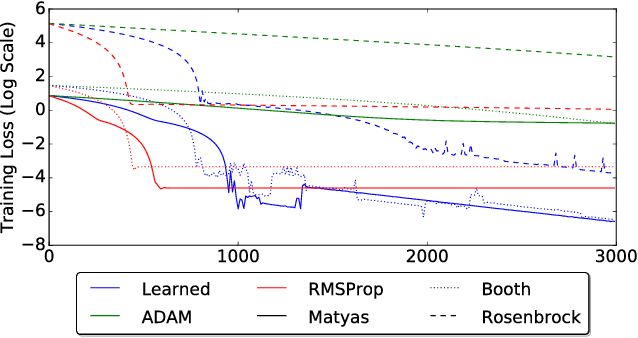
Learning to learn has emerged as an important direction for achieving artificial intelligence. Two of the primary barriers to its adoption are an inability to scale to larger problems and a limited ability to generalize to new tasks. We introduce a learned gradient descent optimizer that generalizes well to new tasks, and which has significantly reduced memory and computation overhead. We achieve this by introducing a novel hierarchical RNN architecture, with minimal per-parameter overhead, augmented with additional architectural features that mirror the known structure of optimization tasks. We also develop a meta-training ensemble of small, diverse optimization tasks capturing common properties of loss landscapes. The optimizer learns to outperform RMSProp/ADAM on problems in this corpus. More importantly, it performs comparably or better when applied to small convolutional neural networks, despite seeing no neural networks in its meta-training set. Finally, it generalizes to train Inception V3 and ResNet V2 architectures on the ImageNet dataset for thousands of steps, optimization problems that are of a vastly different scale than those it was trained on. We release an open source implementation of the meta-training algorithm.