 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetro-Search: Exploring Untaken Paths for Deeper and Efficient Reasoning
Apr 06, 2025



Large reasoning models exhibit remarkable reasoning capabilities via long, elaborate reasoning trajectories. Supervised fine-tuning on such reasoning traces, also known as distillation, can be a cost-effective way to boost reasoning capabilities of student models. However, empirical observations reveal that these reasoning trajectories are often suboptimal, switching excessively between different lines of thought, resulting in under-thinking, over-thinking, and even degenerate responses. We introduce Retro-Search, an MCTS-inspired search algorithm, for distilling higher quality reasoning paths from large reasoning models. Retro-Search retrospectively revises reasoning paths to discover better, yet shorter traces, which can then lead to student models with enhanced reasoning capabilities with shorter, thus faster inference. Our approach can enable two use cases: self-improvement, where models are fine-tuned on their own Retro-Search-ed thought traces, and weak-to-strong improvement, where a weaker model revises stronger model's thought traces via Retro-Search. For self-improving, R1-distill-7B, fine-tuned on its own Retro-Search-ed traces, reduces the average reasoning length by 31.2% while improving performance by 7.7% across seven math benchmarks. For weak-to-strong improvement, we retrospectively revise R1-671B's traces from the OpenThoughts dataset using R1-distill-32B as the Retro-Search-er, a model 20x smaller. Qwen2.5-32B, fine-tuned on this refined data, achieves performance comparable to R1-distill-32B, yielding an 11.3% reduction in reasoning length and a 2.4% performance improvement compared to fine-tuning on the original OpenThoughts data. Our work counters recently emergent viewpoints that question the relevance of search algorithms in the era of large reasoning models, by demonstrating that there are still opportunities for algorithmic advancements, even for frontier models.
AceMath: Advancing Frontier Math Reasoning with Post-Training and Reward Modeling
Dec 19, 2024



In this paper, we introduce AceMath, a suite of frontier math models that excel in solving complex math problems, along with highly effective reward models capable of evaluating generated solutions and reliably identifying the correct ones. To develop the instruction-tuned math models, we propose a supervised fine-tuning (SFT) process that first achieves competitive performance across general domains, followed by targeted fine-tuning for the math domain using a carefully curated set of prompts and synthetically generated responses. The resulting model, AceMath-72B-Instruct greatly outperforms Qwen2.5-Math-72B-Instruct, GPT-4o and Claude-3.5 Sonnet. To develop math-specialized reward model, we first construct AceMath-RewardBench, a comprehensive and robust benchmark for evaluating math reward models across diverse problems and difficulty levels. After that, we present a systematic approach to build our math reward models. The resulting model, AceMath-72B-RM, consistently outperforms state-of-the-art reward models. Furthermore, when combining AceMath-72B-Instruct with AceMath-72B-RM, we achieve the highest average rm@8 score across the math reasoning benchmarks. We will release model weights, training data, and evaluation benchmarks at: https://research.nvidia.com/labs/adlr/acemath
Maximize Your Data's Potential: Enhancing LLM Accuracy with Two-Phase Pretraining
Dec 18, 2024



Pretraining large language models effectively requires strategic data selection, blending and ordering. However, key details about data mixtures especially their scalability to longer token horizons and larger model sizes remain underexplored due to limited disclosure by model developers. To address this, we formalize the concept of two-phase pretraining and conduct an extensive systematic study on how to select and mix data to maximize model accuracies for the two phases. Our findings illustrate that a two-phase approach for pretraining outperforms random data ordering and natural distribution of tokens by 3.4% and 17% on average accuracies. We provide in-depth guidance on crafting optimal blends based on quality of the data source and the number of epochs to be seen. We propose to design blends using downsampled data at a smaller scale of 1T tokens and then demonstrate effective scaling of our approach to larger token horizon of 15T tokens and larger model size of 25B model size. These insights provide a series of steps practitioners can follow to design and scale their data blends.
Nemotron-CC: Transforming Common Crawl into a Refined Long-Horizon Pretraining Dataset
Dec 03, 2024Recent English Common Crawl datasets like FineWeb-Edu and DCLM achieved significant benchmark gains via aggressive model-based filtering, but at the cost of removing 90% of data. This limits their suitability for long token horizon training, such as 15T tokens for Llama 3.1. In this paper, we show how to achieve better trade-offs between accuracy and data quantity by a combination of classifier ensembling, synthetic data rephrasing, and reduced reliance on heuristic filters. When training 8B parameter models for 1T tokens, using a high-quality subset of our data improves MMLU by 5.6 over DCLM, demonstrating the efficacy of our methods for boosting accuracies over a relatively short token horizon. Furthermore, our full 6.3T token dataset matches DCLM on MMLU, but contains four times more unique real tokens than DCLM. This unlocks state-of-the-art training over a long token horizon: an 8B parameter model trained for 15T tokens, of which 7.2T came from our dataset, is better than the Llama 3.1 8B model: +5 on MMLU, +3.1 on ARC-Challenge, and +0.5 on average across ten diverse tasks. The dataset is available at https://data.commoncrawl.org/contrib/Nemotron/Nemotron-CC/index.html
MM-Embed: Universal Multimodal Retrieval with Multimodal LLMs
Nov 04, 2024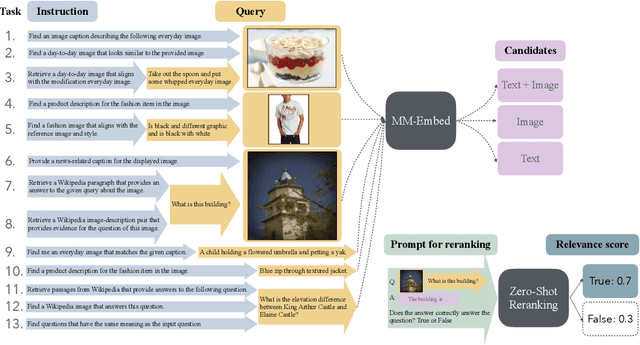
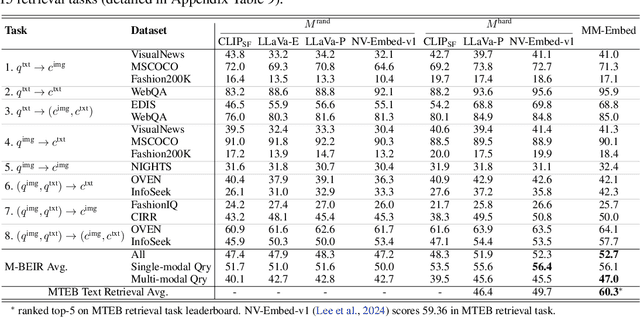
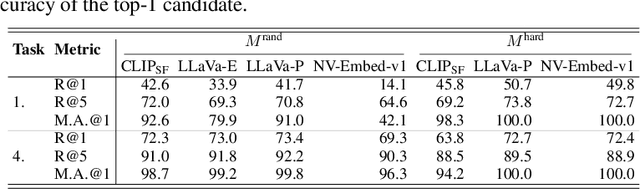

State-of-the-art retrieval models typically address a straightforward search scenario, where retrieval tasks are fixed (e.g., finding a passage to answer a specific question) and only a single modality is supported for both queries and retrieved results. This paper introduces techniques for advancing information retrieval with multimodal large language models (MLLMs), enabling a broader search scenario, termed universal multimodal retrieval, where multiple modalities and diverse retrieval tasks are accommodated. To this end, we first study fine-tuning an MLLM as a bi-encoder retriever on 10 datasets with 16 retrieval tasks. Our empirical results show that the fine-tuned MLLM retriever is capable of understanding challenging queries, composed of both text and image, but underperforms a smaller CLIP retriever in cross-modal retrieval tasks due to modality bias from MLLMs. To address the issue, we propose modality-aware hard negative mining to mitigate the modality bias exhibited by MLLM retrievers. Second, we propose to continually fine-tune the universal multimodal retriever to enhance its text retrieval capability while maintaining multimodal retrieval capability. As a result, our model, MM-Embed, achieves state-of-the-art performance on the multimodal retrieval benchmark M-BEIR, which spans multiple domains and tasks, while also surpassing the state-of-the-art text retrieval model, NV-Embed-v1, on MTEB retrieval benchmark. Finally, we explore to prompt the off-the-shelf MLLMs as the zero-shot rerankers to refine the ranking of the candidates from the multimodal retriever. We find that through prompt-and-reranking, MLLMs can further improve multimodal retrieval when the user queries (e.g., text-image composed queries) are more complex and challenging to understand. These findings also pave the way to advance universal multimodal retrieval in the future.
MIND: Math Informed syNthetic Dialogues for Pretraining LLMs
Oct 15, 2024



The utility of synthetic data to enhance pretraining data quality and hence to improve downstream task accuracy has been widely explored in recent large language models (LLMs). Yet, these approaches fall inadequate in complex, multi-hop and mathematical reasoning tasks as the synthetic data typically fails to add complementary knowledge to the existing raw corpus. In this work, we propose a novel large-scale and diverse Math Informed syNthetic Dialogue (MIND) generation method that improves the mathematical reasoning ability of LLMs. Specifically, using MIND, we generate synthetic conversations based on OpenWebMath (OWM), resulting in a new math corpus, MIND-OWM. Our experiments with different conversational settings reveal that incorporating knowledge gaps between dialog participants is essential for generating high-quality math data. We further identify an effective way to format and integrate synthetic and raw data during pretraining to maximize the gain in mathematical reasoning, emphasizing the need to restructure raw data rather than use it as-is. Compared to pretraining just on raw data, a model pretrained on MIND-OWM shows significant boost in mathematical reasoning (GSM8K: +13.42%, MATH: +2.30%), including superior performance in specialized knowledge (MMLU: +4.55%, MMLU-STEM: +4.28%) and general purpose reasoning tasks (GENERAL REASONING: +2.51%).
Upcycling Large Language Models into Mixture of Experts
Oct 10, 2024



Upcycling pre-trained dense language models into sparse mixture-of-experts (MoE) models is an efficient approach to increase the model capacity of already trained models. However, optimal techniques for upcycling at scale remain unclear. In this work, we conduct an extensive study of upcycling methods and hyperparameters for billion-parameter scale language models. We propose a novel "virtual group" initialization scheme and weight scaling approach to enable upcycling into fine-grained MoE architectures. Through ablations, we find that upcycling outperforms continued dense model training. In addition, we show that softmax-then-topK expert routing improves over topK-then-softmax approach and higher granularity MoEs can help improve accuracy. Finally, we upcycled Nemotron-4 15B on 1T tokens and compared it to a continuously trained version of the same model on the same 1T tokens: the continuous trained model achieved 65.3% MMLU, whereas the upcycled model achieved 67.6%. Our results offer insights and best practices to effectively leverage upcycling for building MoE language models.
NVLM: Open Frontier-Class Multimodal LLMs
Sep 17, 2024



We introduce NVLM 1.0, a family of frontier-class multimodal large language models (LLMs) that achieve state-of-the-art results on vision-language tasks, rivaling the leading proprietary models (e.g., GPT-4o) and open-access models (e.g., Llama 3-V 405B and InternVL 2). Remarkably, NVLM 1.0 shows improved text-only performance over its LLM backbone after multimodal training. In terms of model design, we perform a comprehensive comparison between decoder-only multimodal LLMs (e.g., LLaVA) and cross-attention-based models (e.g., Flamingo). Based on the strengths and weaknesses of both approaches, we propose a novel architecture that enhances both training efficiency and multimodal reasoning capabilities. Furthermore, we introduce a 1-D tile-tagging design for tile-based dynamic high-resolution images, which significantly boosts performance on multimodal reasoning and OCR-related tasks. Regarding training data, we meticulously curate and provide detailed information on our multimodal pretraining and supervised fine-tuning datasets. Our findings indicate that dataset quality and task diversity are more important than scale, even during the pretraining phase, across all architectures. Notably, we develop production-grade multimodality for the NVLM-1.0 models, enabling them to excel in vision-language tasks while maintaining and even improving text-only performance compared to their LLM backbones. To achieve this, we craft and integrate a high-quality text-only dataset into multimodal training, alongside a substantial amount of multimodal math and reasoning data, leading to enhanced math and coding capabilities across modalities. To advance research in the field, we are releasing the model weights and will open-source the code for the community: https://nvlm-project.github.io/.
LLM Pruning and Distillation in Practice: The Minitron Approach
Aug 21, 2024



We present a comprehensive report on compressing the Llama 3.1 8B and Mistral NeMo 12B models to 4B and 8B parameters, respectively, using pruning and distillation. We explore two distinct pruning strategies: (1) depth pruning and (2) joint hidden/attention/MLP (width) pruning, and evaluate the results on common benchmarks from the LM Evaluation Harness. The models are then aligned with NeMo Aligner and tested in instruct-tuned versions. This approach produces a compelling 4B model from Llama 3.1 8B and a state-of-the-art Mistral-NeMo-Minitron-8B (MN-Minitron-8B for brevity) model from Mistral NeMo 12B. We found that with no access to the original data, it is beneficial to slightly fine-tune teacher models on the distillation dataset. We open-source our base model weights on Hugging Face with a permissive license.
ChatQA 2: Bridging the Gap to Proprietary LLMs in Long Context and RAG Capabilities
Jul 19, 2024



In this work, we introduce ChatQA 2, a Llama3-based model designed to bridge the gap between open-access LLMs and leading proprietary models (e.g., GPT-4-Turbo) in long-context understanding and retrieval-augmented generation (RAG) capabilities. These two capabilities are essential for LLMs to process large volumes of information that cannot fit into a single prompt and are complementary to each other, depending on the downstream tasks and computational budgets. We present a detailed continued training recipe to extend the context window of Llama3-70B-base from 8K to 128K tokens, along with a three-stage instruction tuning process to enhance the model's instruction-following, RAG performance, and long-context understanding capabilities. Our results demonstrate that the Llama3-ChatQA-2-70B model achieves accuracy comparable to GPT-4-Turbo-2024-0409 on many long-context understanding tasks and surpasses it on the RAG benchmark. Interestingly, we find that the state-of-the-art long-context retriever can alleviate the top-k context fragmentation issue in RAG, further improving RAG-based results for long-context understanding tasks. We also provide extensive comparisons between RAG and long-context solutions using state-of-the-art long-context LLMs.