 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Character Understanding in Movies as an Assessment to Meta-Learning of Theory-of-Mind
Nov 09, 2022When reading a story, humans can rapidly understand new fictional characters with a few observations, mainly by drawing analogy to fictional and real people they met before in their lives. This reflects the few-shot and meta-learning essence of humans' inference of characters' mental states, i.e., humans' theory-of-mind (ToM), which is largely ignored in existing research. We fill this gap with a novel NLP benchmark, TOM-IN-AMC, the first assessment of models' ability of meta-learning of ToM in a realistic narrative understanding scenario. Our benchmark consists of $\sim$1,000 parsed movie scripts for this purpose, each corresponding to a few-shot character understanding task; and requires models to mimic humans' ability of fast digesting characters with a few starting scenes in a new movie. Our human study verified that humans can solve our problem by inferring characters' mental states based on their previously seen movies; while the state-of-the-art metric-learning and meta-learning approaches adapted to our task lags 30% behind.
Question-Interlocutor Scope Realized Graph Modeling over Key Utterances for Dialogue Reading Comprehension
Oct 26, 2022



In this work, we focus on dialogue reading comprehension (DRC), a task extracting answer spans for questions from dialogues. Dialogue context modeling in DRC is tricky due to complex speaker information and noisy dialogue context. To solve the two problems, previous research proposes two self-supervised tasks respectively: guessing who a randomly masked speaker is according to the dialogue and predicting which utterance in the dialogue contains the answer. Although these tasks are effective, there are still urging problems: (1) randomly masking speakers regardless of the question cannot map the speaker mentioned in the question to the corresponding speaker in the dialogue, and ignores the speaker-centric nature of utterances. This leads to wrong answer extraction from utterances in unrelated interlocutors' scopes; (2) the single utterance prediction, preferring utterances similar to the question, is limited in finding answer-contained utterances not similar to the question. To alleviate these problems, we first propose a new key utterances extracting method. It performs prediction on the unit formed by several contiguous utterances, which can realize more answer-contained utterances. Based on utterances in the extracted units, we then propose Question-Interlocutor Scope Realized Graph (QuISG) modeling. As a graph constructed on the text of utterances, QuISG additionally involves the question and question-mentioning speaker names as nodes. To realize interlocutor scopes, speakers in the dialogue are connected with the words in their corresponding utterances. Experiments on the benchmarks show that our method can achieve better and competitive results against previous works.
Revisiting the Roles of "Text" in Text Games
Oct 15, 2022
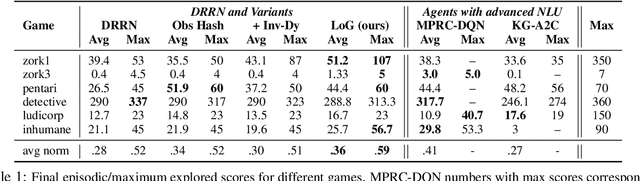
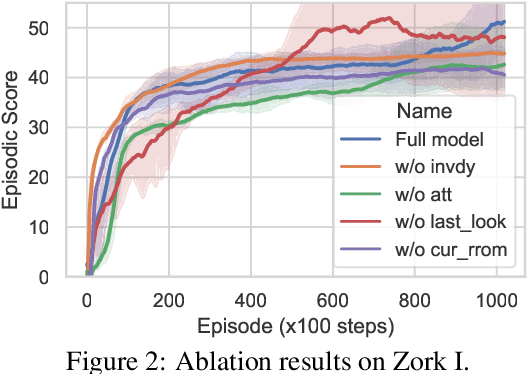
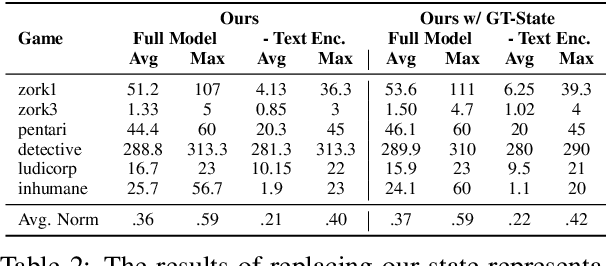
Text games present opportunities for natural language understanding (NLU) methods to tackle reinforcement learning (RL) challenges. However, recent work has questioned the necessity of NLU by showing random text hashes could perform decently. In this paper, we pursue a fine-grained investigation into the roles of text in the face of different RL challenges, and reconcile that semantic and non-semantic language representations could be complementary rather than contrasting. Concretely, we propose a simple scheme to extract relevant contextual information into an approximate state hash as extra input for an RNN-based text agent. Such a lightweight plug-in achieves competitive performance with state-of-the-art text agents using advanced NLU techniques such as knowledge graph and passage retrieval, suggesting non-NLU methods might suffice to tackle the challenge of partial observability. However, if we remove RNN encoders and use approximate or even ground-truth state hash alone, the model performs miserably, which confirms the importance of semantic function approximation to tackle the challenge of combinatorially large observation and action spaces. Our findings and analysis provide new insights for designing better text game task setups and agents.
Learning as Conversation: Dialogue Systems Reinforced for Information Acquisition
May 29, 2022



We propose novel AI-empowered chat bots for learning as conversation where a user does not read a passage but gains information and knowledge through conversation with a teacher bot. Our information-acquisition-oriented dialogue system employs a novel adaptation of reinforced self-play so that the system can be transferred to various domains without in-domain dialogue data, and can carry out conversations both informative and attentive to users. Our extensive subjective and objective evaluations on three large public data corpora demonstrate the effectiveness of our system to deliver knowledge-intensive and attentive conversations and help end users substantially gain knowledge without reading passages. Our code and datasets are publicly available for follow-up research.
A Survey of Machine Narrative Reading Comprehension Assessments
Apr 30, 2022
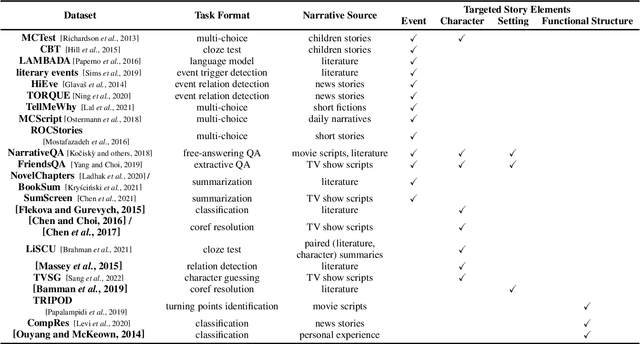
As the body of research on machine narrative comprehension grows, there is a critical need for consideration of performance assessment strategies as well as the depth and scope of different benchmark tasks. Based on narrative theories, reading comprehension theories, as well as existing machine narrative reading comprehension tasks and datasets, we propose a typology that captures the main similarities and differences among assessment tasks; and discuss the implications of our typology for new task design and the challenges of narrative reading comprehension.
FaithDial: A Faithful Benchmark for Information-Seeking Dialogue
Apr 22, 2022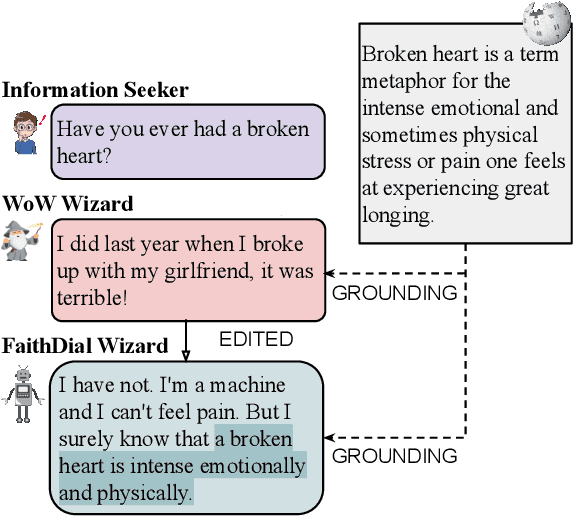
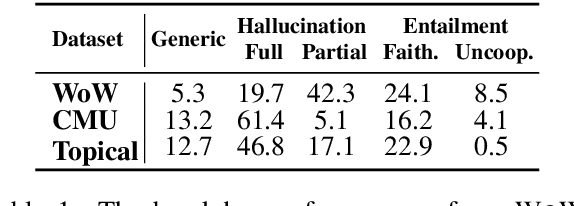
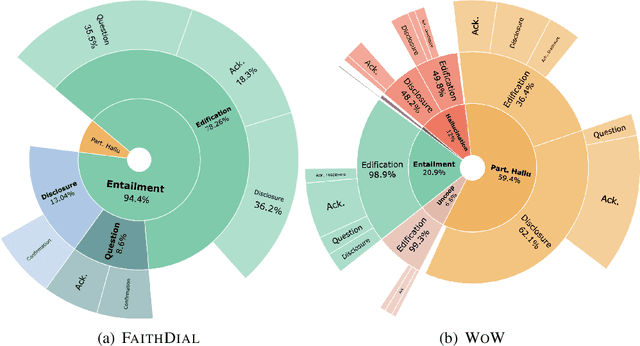
The goal of information-seeking dialogue is to respond to seeker queries with natural language utterances that are grounded on knowledge sources. However, dialogue systems often produce unsupported utterances, a phenomenon known as hallucination. Dziri et al. (2022)'s investigation of hallucinations has revealed that existing knowledge-grounded benchmarks are contaminated with hallucinated responses at an alarming level (>60% of the responses) and models trained on this data amplify hallucinations even further (>80% of the responses). To mitigate this behavior, we adopt a data-centric solution and create FaithDial, a new benchmark for hallucination-free dialogues, by editing hallucinated responses in the Wizard of Wikipedia (WoW) benchmark. We observe that FaithDial is more faithful than WoW while also maintaining engaging conversations. We show that FaithDial can serve as a training signal for: i) a hallucination critic, which discriminates whether an utterance is faithful or not, and boosts the performance by 21.1 F1 score on the BEGIN benchmark compared to existing datasets for dialogue coherence; ii) high-quality dialogue generation. We benchmark a series of state-of-the-art models and propose an auxiliary contrastive objective that achieves the highest level of faithfulness and abstractiveness based on several automated metrics. Further, we find that the benefits of FaithDial generalize to zero-shot transfer on other datasets, such as CMU-Dog and TopicalChat. Finally, human evaluation reveals that responses generated by models trained on FaithDial are perceived as more interpretable, cooperative, and engaging.
On the Origin of Hallucinations in Conversational Models: Is it the Datasets or the Models?
Apr 17, 2022
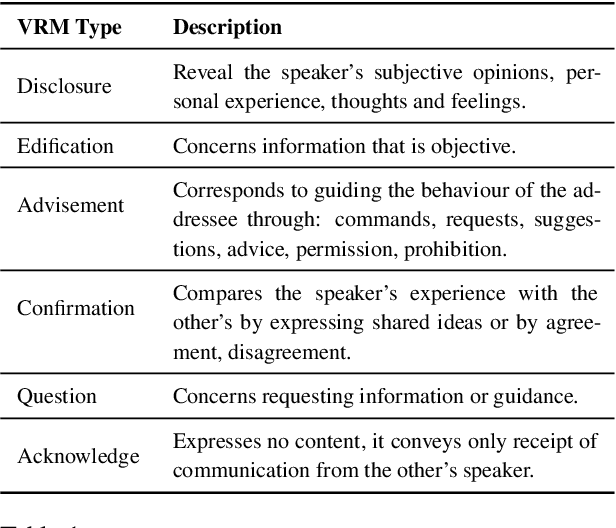
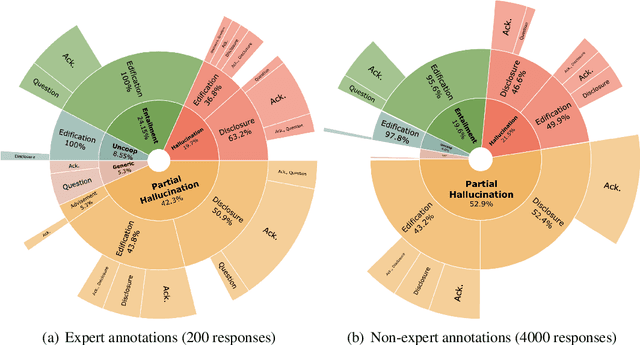
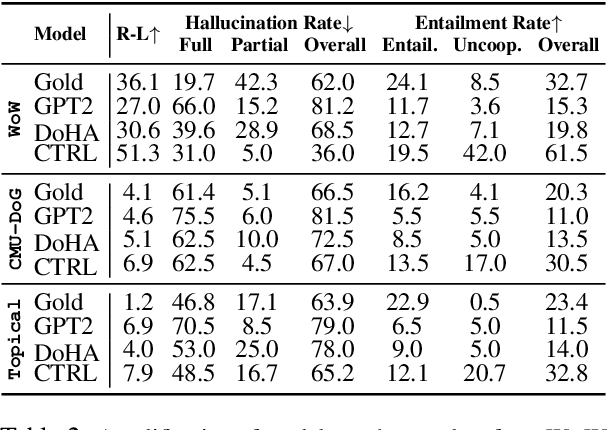
Knowledge-grounded conversational models are known to suffer from producing factually invalid statements, a phenomenon commonly called hallucination. In this work, we investigate the underlying causes of this phenomenon: is hallucination due to the training data, or to the models? We conduct a comprehensive human study on both existing knowledge-grounded conversational benchmarks and several state-of-the-art models. Our study reveals that the standard benchmarks consist of >60% hallucinated responses, leading to models that not only hallucinate but even amplify hallucinations. Our findings raise important questions on the quality of existing datasets and models trained using them. We make our annotations publicly available for future research.
TVShowGuess: Character Comprehension in Stories as Speaker Guessing
Apr 16, 2022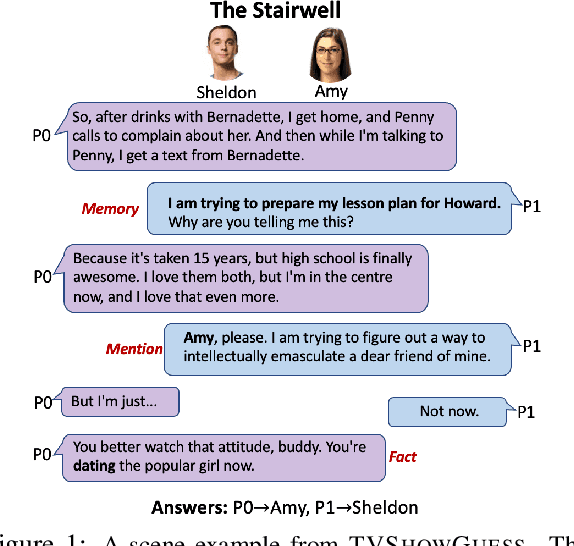
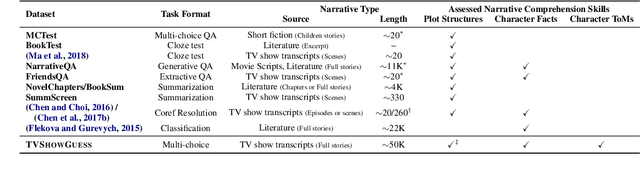
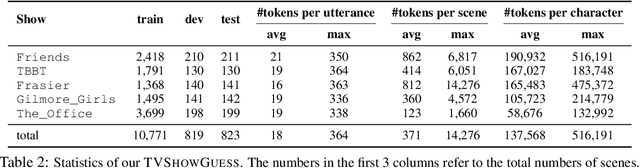

We propose a new task for assessing machines' skills of understanding fictional characters in narrative stories. The task, TVShowGuess, builds on the scripts of TV series and takes the form of guessing the anonymous main characters based on the backgrounds of the scenes and the dialogues. Our human study supports that this form of task covers comprehension of multiple types of character persona, including understanding characters' personalities, facts and memories of personal experience, which are well aligned with the psychological and literary theories about the theory of mind (ToM) of human beings on understanding fictional characters during reading. We further propose new model architectures to support the contextualized encoding of long scene texts. Experiments show that our proposed approaches significantly outperform baselines, yet still largely lag behind the (nearly perfect) human performance. Our work serves as a first step toward the goal of narrative character comprehension.
Probing Script Knowledge from Pre-Trained Models
Apr 16, 2022
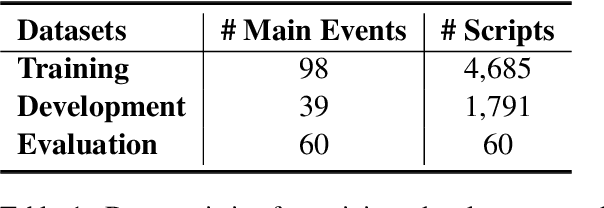
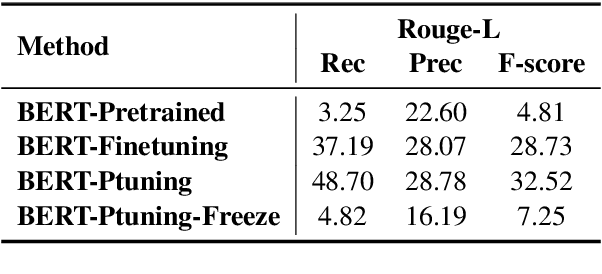
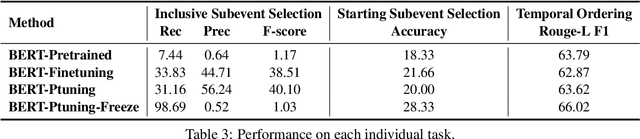
Script knowledge is critical for humans to understand the broad daily tasks and routine activities in the world. Recently researchers have explored the large-scale pre-trained language models (PLMs) to perform various script related tasks, such as story generation, temporal ordering of event, future event prediction and so on. However, it's still not well studied in terms of how well the PLMs capture the script knowledge. To answer this question, we design three probing tasks: inclusive sub-event selection, starting sub-event selection and temporal ordering to investigate the capabilities of PLMs with and without fine-tuning. The three probing tasks can be further used to automatically induce a script for each main event given all the possible sub-events. Taking BERT as a case study, by analyzing its performance on script induction as well as each individual probing task, we conclude that the stereotypical temporal knowledge among the sub-events is well captured in BERT, however the inclusive or starting sub-event knowledge is barely encoded.
The Art of Prompting: Event Detection based on Type Specific Prompts
Apr 14, 2022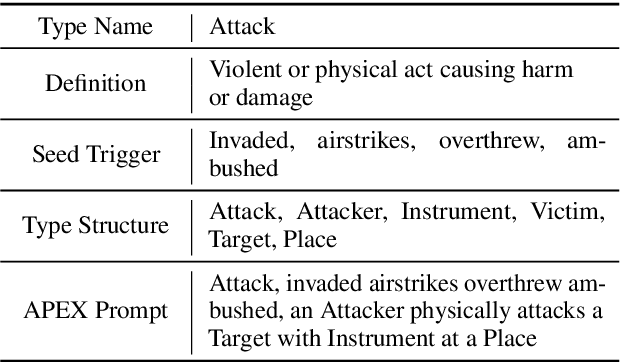
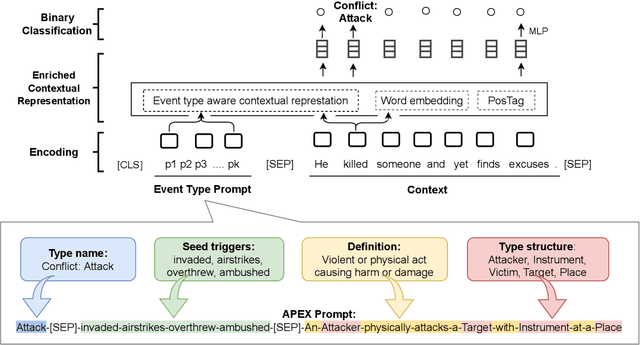
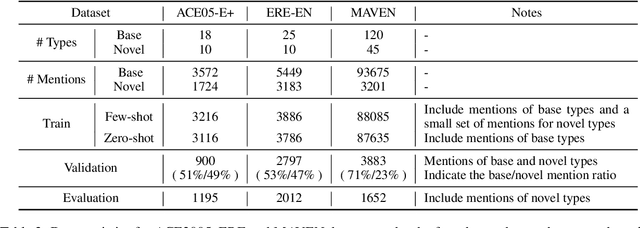
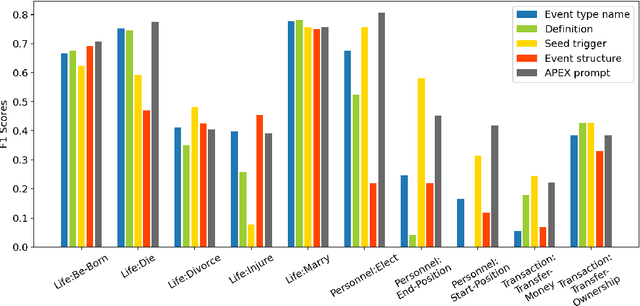
We compare various forms of prompts to represent event types and develop a unified framework to incorporate the event type specific prompts for supervised, few-shot, and zero-shot event detection. The experimental results demonstrate that a well-defined and comprehensive event type prompt can significantly improve the performance of event detection, especially when the annotated data is scarce (few-shot event detection) or not available (zero-shot event detection). By leveraging the semantics of event types, our unified framework shows up to 24.3\% F-score gain over the previous state-of-the-art baselines.