 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Time Series Foundation Models through Data Mixtures
Mar 03, 2026Time series foundation models (TSFMs) have become increasingly popular for zero-shot forecasting. However, for a new time series domain not fully covered by the pretraining set, performance can suffer. Therefore, when a practitioner cares about a new domain and has access to a set of related datasets, the question arises: how best to fine-tune a TSFM to improve zero-shot forecasting? A typical approach to this type of problem is to fine-tune a LoRA module on all datasets or separately on each dataset. Tuning a separate module on each dataset allows for the specialisation of the TSFM to different types of data distribution, by selecting differing combinations of per-dataset modules for different time series contexts. However, we find that, using per-dataset modules might not be optimal, since a time series dataset can contain data from several types of distributions, i.e. sub-domains. This can be due to the distribution shifting or having differing distributions for different dimensions of the time series. Hence, we propose MixFT which re-divides the data using Bayesian mixtures into sets that best represent the sub-domains present in the data, and fine-tunes separately on each of these sets. This re-division of the data ensures that each set is more homogeneous, leading to fine-tuned modules focused on specific sub-domains. Our experiments show that MixFT performs better than per-dataset methods and when fine-tuning a single module on all the data. This suggests that by re-partitioning the data to represent sub-domains we can better specialise TSFMs to improve zero-shot forecasting.
Self-Improving World Modelling with Latent Actions
Feb 05, 2026Internal modelling of the world -- predicting transitions between previous states $X$ and next states $Y$ under actions $Z$ -- is essential to reasoning and planning for LLMs and VLMs. Learning such models typically requires costly action-labelled trajectories. We propose SWIRL, a self-improvement framework that learns from state-only sequences by treating actions as a latent variable and alternating between Forward World Modelling (FWM) $P_θ(Y|X,Z)$ and an Inverse Dynamics Modelling (IDM) $Q_φ(Z|X,Y)$. SWIRL iterates two phases: (1) Variational Information Maximisation, which updates the FWM to generate next states that maximise conditional mutual information with latent actions given prior states, encouraging identifiable consistency; and (2) ELBO Maximisation, which updates the IDM to explain observed transitions, effectively performing coordinate ascent. Both models are trained with reinforcement learning (specifically, GRPO) with the opposite frozen model's log-probability as a reward signal. We provide theoretical learnability guarantees for both updates, and evaluate SWIRL on LLMs and VLMs across multiple environments: single-turn and multi-turn open-world visual dynamics and synthetic textual environments for physics, web, and tool calling. SWIRL achieves gains of 16% on AURORABench, 28% on ByteMorph, 16% on WorldPredictionBench, and 14% on StableToolBench.
Bolmo: Byteifying the Next Generation of Language Models
Dec 17, 2025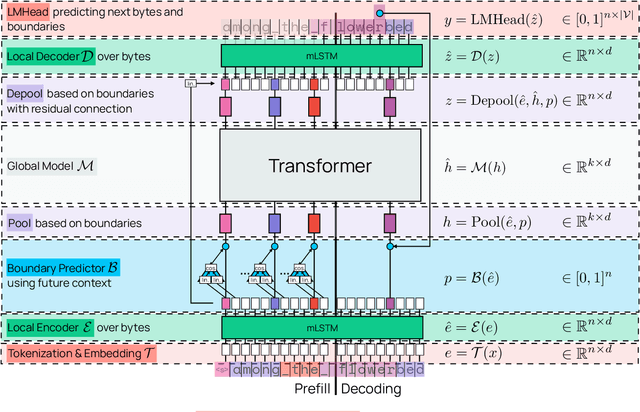
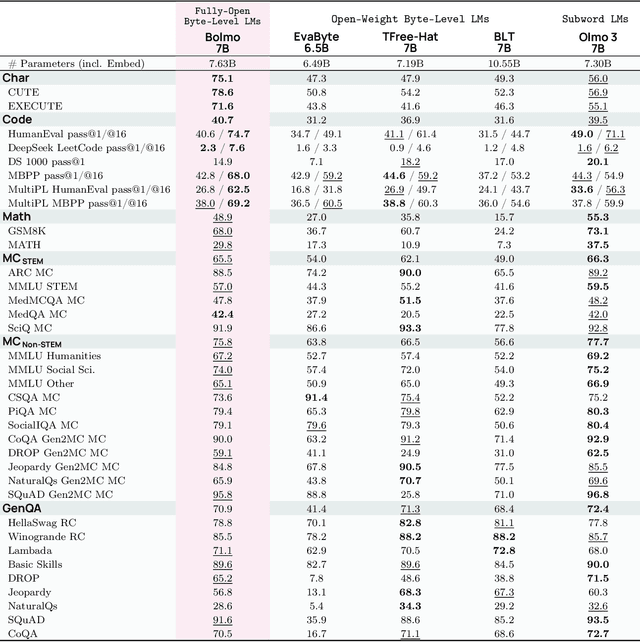
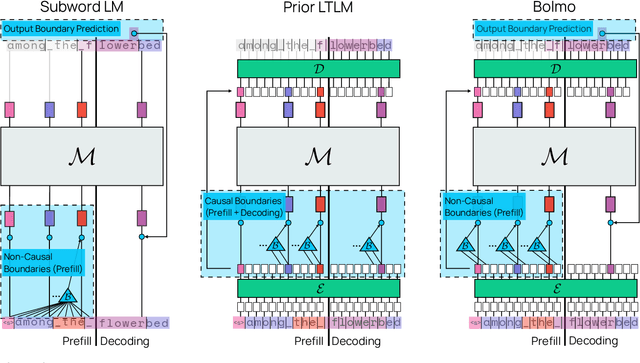
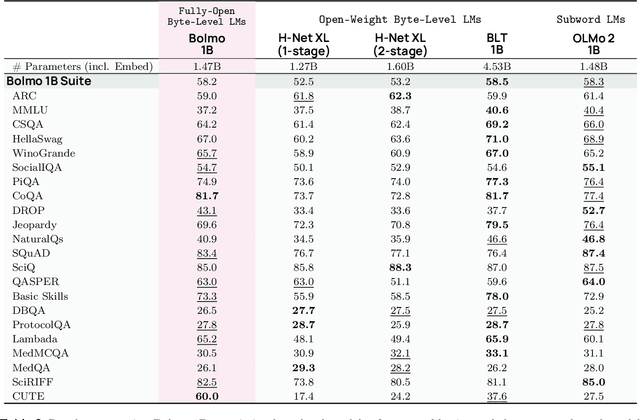
We introduce Bolmo, the first family of competitive fully open byte-level language models (LMs) at the 1B and 7B parameter scales. In contrast to prior research on byte-level LMs, which focuses predominantly on training from scratch, we train Bolmo by byteifying existing subword-level LMs. Byteification enables overcoming the limitations of subword tokenization - such as insufficient character understanding and efficiency constraints due to the fixed subword vocabulary - while performing at the level of leading subword-level LMs. Bolmo is specifically designed for byteification: our architecture resolves a mismatch between the expressivity of prior byte-level architectures and subword-level LMs, which makes it possible to employ an effective exact distillation objective between Bolmo and the source subword model. This allows for converting a subword-level LM to a byte-level LM by investing less than 1\% of a typical pretraining token budget. Bolmo substantially outperforms all prior byte-level LMs of comparable size, and outperforms the source subword-level LMs on character understanding and, in some cases, coding, while coming close to matching the original LMs' performance on other tasks. Furthermore, we show that Bolmo can achieve inference speeds competitive with subword-level LMs by training with higher token compression ratios, and can be cheaply and effectively post-trained by leveraging the existing ecosystem around the source subword-level LM. Our results finally make byte-level LMs a practical choice competitive with subword-level LMs across a wide set of use cases.
Sample-efficient Integration of New Modalities into Large Language Models
Sep 04, 2025Multimodal foundation models can process several modalities. However, since the space of possible modalities is large and evolving over time, training a model from scratch to encompass all modalities is unfeasible. Moreover, integrating a modality into a pre-existing foundation model currently requires a significant amount of paired data, which is often not available for low-resource modalities. In this paper, we introduce a method for sample-efficient modality integration (SEMI) into Large Language Models (LLMs). To this end, we devise a hypernetwork that can adapt a shared projector -- placed between modality-specific encoders and an LLM -- to any modality. The hypernetwork, trained on high-resource modalities (i.e., text, speech, audio, video), is conditioned on a few samples from any arbitrary modality at inference time to generate a suitable adapter. To increase the diversity of training modalities, we artificially multiply the number of encoders through isometric transformations. We find that SEMI achieves a significant boost in sample efficiency during few-shot integration of new modalities (i.e., satellite images, astronomical images, inertial measurements, and molecules) with encoders of arbitrary embedding dimensionality. For instance, to reach the same accuracy as 32-shot SEMI, training the projector from scratch needs 64$\times$ more data. As a result, SEMI holds promise to extend the modality coverage of foundation models.
Blending Supervised and Reinforcement Fine-Tuning with Prefix Sampling
Jul 02, 2025Existing post-training techniques for large language models are broadly categorized into Supervised Fine-Tuning (SFT) and Reinforcement Fine-Tuning (RFT). Each paradigm presents a distinct trade-off: SFT excels at mimicking demonstration data but can lead to problematic generalization as a form of behavior cloning. Conversely, RFT can significantly enhance a model's performance but is prone to learn unexpected behaviors, and its performance is highly sensitive to the initial policy. In this paper, we propose a unified view of these methods and introduce Prefix-RFT, a hybrid approach that synergizes learning from both demonstration and exploration. Using mathematical reasoning problems as a testbed, we empirically demonstrate that Prefix-RFT is both simple and effective. It not only surpasses the performance of standalone SFT and RFT but also outperforms parallel mixed-policy RFT methods. A key advantage is its seamless integration into existing open-source frameworks, requiring only minimal modifications to the standard RFT pipeline. Our analysis highlights the complementary nature of SFT and RFT, and validates that Prefix-RFT effectively harmonizes these two learning paradigms. Furthermore, ablation studies confirm the method's robustness to variations in the quality and quantity of demonstration data. We hope this work offers a new perspective on LLM post-training, suggesting that a unified paradigm that judiciously integrates demonstration and exploration could be a promising direction for future research.
Bootstrapping World Models from Dynamics Models in Multimodal Foundation Models
Jun 06, 2025To what extent do vision-and-language foundation models possess a realistic world model (observation $\times$ action $\rightarrow$ observation) and a dynamics model (observation $\times$ observation $\rightarrow$ action), when actions are expressed through language? While open-source foundation models struggle with both, we find that fine-tuning them to acquire a dynamics model through supervision is significantly easier than acquiring a world model. In turn, dynamics models can be used to bootstrap world models through two main strategies: 1) weakly supervised learning from synthetic data and 2) inference time verification. Firstly, the dynamics model can annotate actions for unlabelled pairs of video frame observations to expand the training data. We further propose a new objective, where image tokens in observation pairs are weighted by their importance, as predicted by a recognition model. Secondly, the dynamics models can assign rewards to multiple samples of the world model to score them, effectively guiding search at inference time. We evaluate the world models resulting from both strategies through the task of action-centric image editing on Aurora-Bench. Our best model achieves a performance competitive with state-of-the-art image editing models, improving on them by a margin of $15\%$ on real-world subsets according to GPT4o-as-judge, and achieving the best average human evaluation across all subsets of Aurora-Bench.
Inference-Time Hyper-Scaling with KV Cache Compression
Jun 05, 2025Inference-time scaling trades efficiency for increased reasoning accuracy by generating longer or more parallel sequences. However, in Transformer LLMs, generation cost is bottlenecked by the size of the key-value (KV) cache, rather than the number of generated tokens. Hence, we explore inference-time hyper-scaling: by compressing the KV cache, we can generate more tokens within the same compute budget and further improve the accuracy of scaled inference. The success of this approach, however, hinges on the ability of compression methods to preserve accuracy even at high compression ratios. To make hyper-scaling practical, we introduce Dynamic Memory Sparsification (DMS), a novel method for sparsifying KV caches that only requires 1K training steps to achieve 8$\times$ compression, while maintaining better accuracy than training-free sparse attention. Instead of prematurely discarding cached tokens, DMS delays token eviction, implicitly merging representations and preserving critical information. We demonstrate the effectiveness of inference-time hyper-scaling with DMS on multiple families of LLMs, showing that it boosts accuracy for comparable inference runtime and memory load. For instance, we enhance Qwen-R1 32B by an average of 9.1 points on AIME 24, 7.6 on GPQA, and 9.6 on LiveCodeBench across compute budgets.
The Sparse Frontier: Sparse Attention Trade-offs in Transformer LLMs
Apr 24, 2025Sparse attention offers a promising strategy to extend long-context capabilities in Transformer LLMs, yet its viability, its efficiency-accuracy trade-offs, and systematic scaling studies remain unexplored. To address this gap, we perform a careful comparison of training-free sparse attention methods at varying model scales, sequence lengths, and sparsity levels on a diverse collection of long-sequence tasks-including novel ones that rely on natural language while remaining controllable and easy to evaluate. Based on our experiments, we report a series of key findings: 1) an isoFLOPS analysis reveals that for very long sequences, larger and highly sparse models are preferable to smaller and dense ones. 2) The level of sparsity attainable while statistically guaranteeing accuracy preservation is higher during decoding than prefilling, and correlates with model size in the former. 3) There is no clear strategy that performs best across tasks and phases, with different units of sparsification or budget adaptivity needed for different scenarios. Even moderate sparsity levels often result in significant performance degradation on at least one task, highlighting that sparse attention is not a universal solution. 4) We introduce and validate novel scaling laws specifically tailored for sparse attention, providing evidence that our findings are likely to hold true beyond our range of experiments. Through these insights, we demonstrate that sparse attention is a key tool to enhance the capabilities of Transformer LLMs for processing longer sequences, but requires careful evaluation of trade-offs for performance-sensitive applications.
Cross-Lingual and Cross-Cultural Variation in Image Descriptions
Sep 25, 2024



Do speakers of different languages talk differently about what they see? Behavioural and cognitive studies report cultural effects on perception; however, these are mostly limited in scope and hard to replicate. In this work, we conduct the first large-scale empirical study of cross-lingual variation in image descriptions. Using a multimodal dataset with 31 languages and images from diverse locations, we develop a method to accurately identify entities mentioned in captions and present in the images, then measure how they vary across languages. Our analysis reveals that pairs of languages that are geographically or genetically closer tend to mention the same entities more frequently. We also identify entity categories whose saliency is universally high (such as animate beings), low (clothing accessories) or displaying high variance across languages (landscape). In a case study, we measure the differences in a specific language pair (e.g., Japanese mentions clothing far more frequently than English). Furthermore, our method corroborates previous small-scale studies, including 1) Rosch et al. (1976)'s theory of basic-level categories, demonstrating a preference for entities that are neither too generic nor too specific, and 2) Miyamoto et al. (2006)'s hypothesis that environments afford patterns of perception, such as entity counts. Overall, our work reveals the presence of both universal and culture-specific patterns in entity mentions.
Post-hoc Reward Calibration: A Case Study on Length Bias
Sep 25, 2024



Reinforcement Learning from Human Feedback aligns the outputs of Large Language Models with human values and preferences. Central to this process is the reward model (RM), which translates human feedback into training signals for optimising LLM behaviour. However, RMs can develop biases by exploiting spurious correlations in their training data, such as favouring outputs based on length or style rather than true quality. These biases can lead to incorrect output rankings, sub-optimal model evaluations, and the amplification of undesirable behaviours in LLMs alignment. This paper addresses the challenge of correcting such biases without additional data and training, introducing the concept of Post-hoc Reward Calibration. We first propose an intuitive approach to estimate the bias term and, thus, remove it to approximate the underlying true reward. We then extend the approach to a more general and robust form with the Locally Weighted Regression. Focusing on the prevalent length bias, we validate our proposed approaches across three experimental settings, demonstrating consistent improvements: (1) a 3.11 average performance gain across 33 reward models on the RewardBench dataset; (2) enhanced alignment of RM rankings with GPT-4 evaluations and human preferences based on the AlpacaEval benchmark; and (3) improved Length-Controlled win rate of the RLHF process in multiple LLM--RM combinations. Our method is computationally efficient and generalisable to other types of bias and RMs, offering a scalable and robust solution for mitigating biases in LLM alignment. Our code and results are available at https://github.com/ZeroYuHuang/Reward-Calibration.