 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Models, Sparse Safety: Unsafe Routes in Mixture-of-Experts LLMs
Feb 09, 2026By introducing routers to selectively activate experts in Transformer layers, the mixture-of-experts (MoE) architecture significantly reduces computational costs in large language models (LLMs) while maintaining competitive performance, especially for models with massive parameters. However, prior work has largely focused on utility and efficiency, leaving the safety risks associated with this sparse architecture underexplored. In this work, we show that the safety of MoE LLMs is as sparse as their architecture by discovering unsafe routes: routing configurations that, once activated, convert safe outputs into harmful ones. Specifically, we first introduce the Router Safety importance score (RoSais) to quantify the safety criticality of each layer's router. Manipulation of only the high-RoSais router(s) can flip the default route into an unsafe one. For instance, on JailbreakBench, masking 5 routers in DeepSeek-V2-Lite increases attack success rate (ASR) by over 4$\times$ to 0.79, highlighting an inherent risk that router manipulation may naturally occur in MoE LLMs. We further propose a Fine-grained token-layer-wise Stochastic Optimization framework to discover more concrete Unsafe Routes (F-SOUR), which explicitly considers the sequentiality and dynamics of input tokens. Across four representative MoE LLM families, F-SOUR achieves an average ASR of 0.90 and 0.98 on JailbreakBench and AdvBench, respectively. Finally, we outline defensive perspectives, including safety-aware route disabling and router training, as promising directions to safeguard MoE LLMs. We hope our work can inform future red-teaming and safeguarding of MoE LLMs. Our code is provided in https://github.com/TrustAIRLab/UnsafeMoE.
Integrating Anatomical Priors into a Causal Diffusion Model
Sep 10, 2025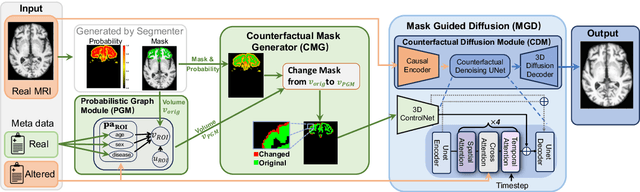
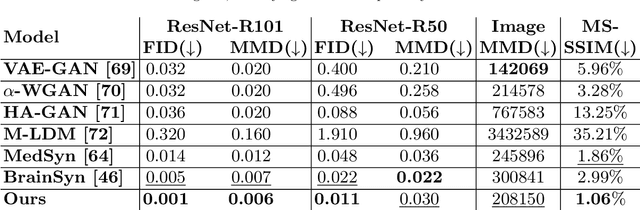
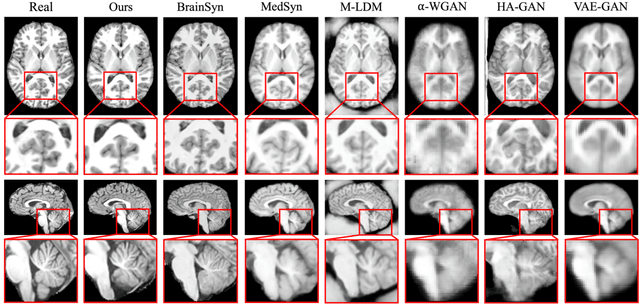
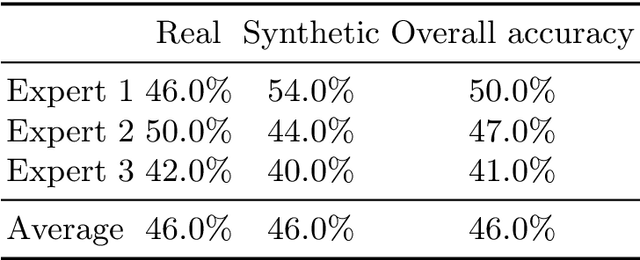
3D brain MRI studies often examine subtle morphometric differences between cohorts that are hard to detect visually. Given the high cost of MRI acquisition, these studies could greatly benefit from image syntheses, particularly counterfactual image generation, as seen in other domains, such as computer vision. However, counterfactual models struggle to produce anatomically plausible MRIs due to the lack of explicit inductive biases to preserve fine-grained anatomical details. This shortcoming arises from the training of the models aiming to optimize for the overall appearance of the images (e.g., via cross-entropy) rather than preserving subtle, yet medically relevant, local variations across subjects. To preserve subtle variations, we propose to explicitly integrate anatomical constraints on a voxel-level as prior into a generative diffusion framework. Called Probabilistic Causal Graph Model (PCGM), the approach captures anatomical constraints via a probabilistic graph module and translates those constraints into spatial binary masks of regions where subtle variations occur. The masks (encoded by a 3D extension of ControlNet) constrain a novel counterfactual denoising UNet, whose encodings are then transferred into high-quality brain MRIs via our 3D diffusion decoder. Extensive experiments on multiple datasets demonstrate that PCGM generates structural brain MRIs of higher quality than several baseline approaches. Furthermore, we show for the first time that brain measurements extracted from counterfactuals (generated by PCGM) replicate the subtle effects of a disease on cortical brain regions previously reported in the neuroscience literature. This achievement is an important milestone in the use of synthetic MRIs in studies investigating subtle morphological differences.
JADES: A Universal Framework for Jailbreak Assessment via Decompositional Scoring
Aug 28, 2025Accurately determining whether a jailbreak attempt has succeeded is a fundamental yet unresolved challenge. Existing evaluation methods rely on misaligned proxy indicators or naive holistic judgments. They frequently misinterpret model responses, leading to inconsistent and subjective assessments that misalign with human perception. To address this gap, we introduce JADES (Jailbreak Assessment via Decompositional Scoring), a universal jailbreak evaluation framework. Its key mechanism is to automatically decompose an input harmful question into a set of weighted sub-questions, score each sub-answer, and weight-aggregate the sub-scores into a final decision. JADES also incorporates an optional fact-checking module to strengthen the detection of hallucinations in jailbreak responses. We validate JADES on JailbreakQR, a newly introduced benchmark proposed in this work, consisting of 400 pairs of jailbreak prompts and responses, each meticulously annotated by humans. In a binary setting (success/failure), JADES achieves 98.5% agreement with human evaluators, outperforming strong baselines by over 9%. Re-evaluating five popular attacks on four LLMs reveals substantial overestimation (e.g., LAA's attack success rate on GPT-3.5-Turbo drops from 93% to 69%). Our results show that JADES could deliver accurate, consistent, and interpretable evaluations, providing a reliable basis for measuring future jailbreak attacks.
Excessive Reasoning Attack on Reasoning LLMs
Jun 17, 2025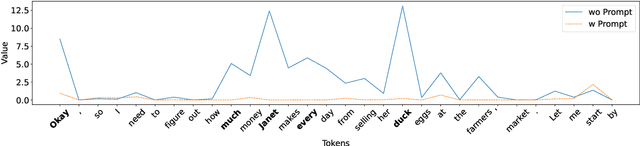
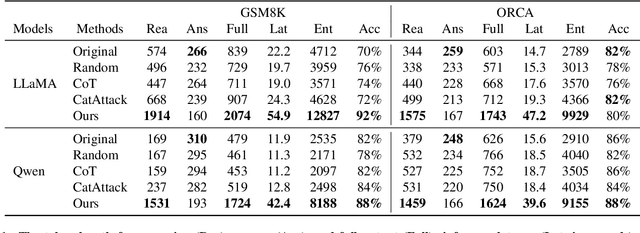
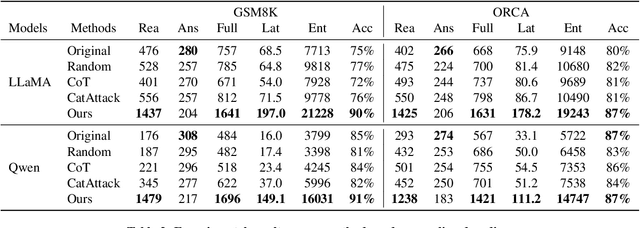
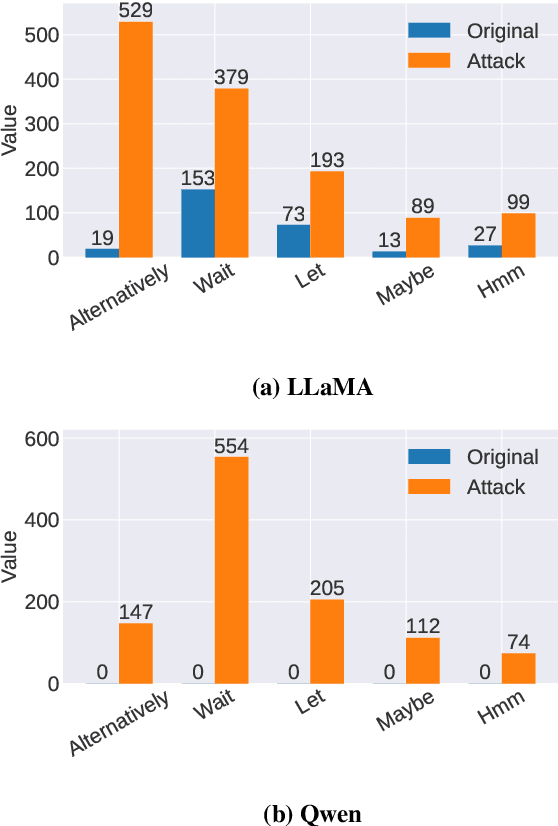
Recent reasoning large language models (LLMs), such as OpenAI o1 and DeepSeek-R1, exhibit strong performance on complex tasks through test-time inference scaling. However, prior studies have shown that these models often incur significant computational costs due to excessive reasoning, such as frequent switching between reasoning trajectories (e.g., underthinking) or redundant reasoning on simple questions (e.g., overthinking). In this work, we expose a novel threat: adversarial inputs can be crafted to exploit excessive reasoning behaviors and substantially increase computational overhead without compromising model utility. Therefore, we propose a novel loss framework consisting of three components: (1) Priority Cross-Entropy Loss, a modification of the standard cross-entropy objective that emphasizes key tokens by leveraging the autoregressive nature of LMs; (2) Excessive Reasoning Loss, which encourages the model to initiate additional reasoning paths during inference; and (3) Delayed Termination Loss, which is designed to extend the reasoning process and defer the generation of final outputs. We optimize and evaluate our attack for the GSM8K and ORCA datasets on DeepSeek-R1-Distill-LLaMA and DeepSeek-R1-Distill-Qwen. Empirical results demonstrate a 3x to 9x increase in reasoning length with comparable utility performance. Furthermore, our crafted adversarial inputs exhibit transferability, inducing computational overhead in o3-mini, o1-mini, DeepSeek-R1, and QWQ models.
Towards Interpretable Counterfactual Generation via Multimodal Autoregression
Mar 29, 2025Counterfactual medical image generation enables clinicians to explore clinical hypotheses, such as predicting disease progression, facilitating their decision-making. While existing methods can generate visually plausible images from disease progression prompts, they produce silent predictions that lack interpretation to verify how the generation reflects the hypothesized progression -- a critical gap for medical applications that require traceable reasoning. In this paper, we propose Interpretable Counterfactual Generation (ICG), a novel task requiring the joint generation of counterfactual images that reflect the clinical hypothesis and interpretation texts that outline the visual changes induced by the hypothesis. To enable ICG, we present ICG-CXR, the first dataset pairing longitudinal medical images with hypothetical progression prompts and textual interpretations. We further introduce ProgEmu, an autoregressive model that unifies the generation of counterfactual images and textual interpretations. We demonstrate the superiority of ProgEmu in generating progression-aligned counterfactuals and interpretations, showing significant potential in enhancing clinical decision support and medical education. Project page: https://progemu.github.io.
SaLoRA: Safety-Alignment Preserved Low-Rank Adaptation
Jan 03, 2025



As advancements in large language models (LLMs) continue and the demand for personalized models increases, parameter-efficient fine-tuning (PEFT) methods (e.g., LoRA) will become essential due to their efficiency in reducing computation costs. However, recent studies have raised alarming concerns that LoRA fine-tuning could potentially compromise the safety alignment in LLMs, posing significant risks for the model owner. In this paper, we first investigate the underlying mechanism by analyzing the changes in safety alignment related features before and after fine-tuning. Then, we propose a fixed safety module calculated by safety data and a task-specific initialization for trainable parameters in low-rank adaptations, termed Safety-alignment preserved Low-Rank Adaptation (SaLoRA). Unlike previous LoRA methods and their variants, SaLoRA enables targeted modifications to LLMs without disrupting their original alignments. Our experiments show that SaLoRA outperforms various adapters-based approaches across various evaluation metrics in different fine-tuning tasks.
HC-LLM: Historical-Constrained Large Language Models for Radiology Report Generation
Dec 15, 2024



Radiology report generation (RRG) models typically focus on individual exams, often overlooking the integration of historical visual or textual data, which is crucial for patient follow-ups. Traditional methods usually struggle with long sequence dependencies when incorporating historical information, but large language models (LLMs) excel at in-context learning, making them well-suited for analyzing longitudinal medical data. In light of this, we propose a novel Historical-Constrained Large Language Models (HC-LLM) framework for RRG, empowering LLMs with longitudinal report generation capabilities by constraining the consistency and differences between longitudinal images and their corresponding reports. Specifically, our approach extracts both time-shared and time-specific features from longitudinal chest X-rays and diagnostic reports to capture disease progression. Then, we ensure consistent representation by applying intra-modality similarity constraints and aligning various features across modalities with multimodal contrastive and structural constraints. These combined constraints effectively guide the LLMs in generating diagnostic reports that accurately reflect the progression of the disease, achieving state-of-the-art results on the Longitudinal-MIMIC dataset. Notably, our approach performs well even without historical data during testing and can be easily adapted to other multimodal large models, enhancing its versatility.
Artificial Intelligence-Enhanced Couinaud Segmentation for Precision Liver Cancer Therapy
Nov 05, 2024



Precision therapy for liver cancer necessitates accurately delineating liver sub-regions to protect healthy tissue while targeting tumors, which is essential for reducing recurrence and improving survival rates. However, the segmentation of hepatic segments, known as Couinaud segmentation, is challenging due to indistinct sub-region boundaries and the need for extensive annotated datasets. This study introduces LiverFormer, a novel Couinaud segmentation model that effectively integrates global context with low-level local features based on a 3D hybrid CNN-Transformer architecture. Additionally, a registration-based data augmentation strategy is equipped to enhance the segmentation performance with limited labeled data. Evaluated on CT images from 123 patients, LiverFormer demonstrated high accuracy and strong concordance with expert annotations across various metrics, allowing for enhanced treatment planning for surgery and radiation therapy. It has great potential to reduces complications and minimizes potential damages to surrounding tissue, leading to improved outcomes for patients undergoing complex liver cancer treatments.
SemiDDM-Weather: A Semi-supervised Learning Framework for All-in-one Adverse Weather Removal
Sep 29, 2024



Adverse weather removal aims to restore clear vision under adverse weather conditions. Existing methods are mostly tailored for specific weather types and rely heavily on extensive labeled data. In dealing with these two limitations, this paper presents a pioneering semi-supervised all-in-one adverse weather removal framework built on the teacher-student network with a Denoising Diffusion Model (DDM) as the backbone, termed SemiDDM-Weather. As for the design of DDM backbone in our SemiDDM-Weather, we adopt the SOTA Wavelet Diffusion Model-Wavediff with customized inputs and loss functions, devoted to facilitating the learning of many-to-one mapping distributions for efficient all-in-one adverse weather removal with limited label data. To mitigate the risk of misleading model training due to potentially inaccurate pseudo-labels generated by the teacher network in semi-supervised learning, we introduce quality assessment and content consistency constraints to screen the "optimal" outputs from the teacher network as the pseudo-labels, thus more effectively guiding the student network training with unlabeled data. Experimental results show that on both synthetic and real-world datasets, our SemiDDM-Weather consistently delivers high visual quality and superior adverse weather removal, even when compared to fully supervised competitors. Our code and pre-trained model are available at this repository.
TERD: A Unified Framework for Safeguarding Diffusion Models Against Backdoors
Sep 09, 2024



Diffusion models have achieved notable success in image generation, but they remain highly vulnerable to backdoor attacks, which compromise their integrity by producing specific undesirable outputs when presented with a pre-defined trigger. In this paper, we investigate how to protect diffusion models from this dangerous threat. Specifically, we propose TERD, a backdoor defense framework that builds unified modeling for current attacks, which enables us to derive an accessible reversed loss. A trigger reversion strategy is further employed: an initial approximation of the trigger through noise sampled from a prior distribution, followed by refinement through differential multi-step samplers. Additionally, with the reversed trigger, we propose backdoor detection from the noise space, introducing the first backdoor input detection approach for diffusion models and a novel model detection algorithm that calculates the KL divergence between reversed and benign distributions. Extensive evaluations demonstrate that TERD secures a 100% True Positive Rate (TPR) and True Negative Rate (TNR) across datasets of varying resolutions. TERD also demonstrates nice adaptability to other Stochastic Differential Equation (SDE)-based models. Our code is available at https://github.com/PKU-ML/TERD.