 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecure Video Quality Assessment Resisting Adversarial Attacks
Oct 09, 2024The exponential surge in video traffic has intensified the imperative for Video Quality Assessment (VQA). Leveraging cutting-edge architectures, current VQA models have achieved human-comparable accuracy. However, recent studies have revealed the vulnerability of existing VQA models against adversarial attacks. To establish a reliable and practical assessment system, a secure VQA model capable of resisting such malicious attacks is urgently demanded. Unfortunately, no attempt has been made to explore this issue. This paper first attempts to investigate general adversarial defense principles, aiming at endowing existing VQA models with security. Specifically, we first introduce random spatial grid sampling on the video frame for intra-frame defense. Then, we design pixel-wise randomization through a guardian map, globally neutralizing adversarial perturbations. Meanwhile, we extract temporal information from the video sequence as compensation for inter-frame defense. Building upon these principles, we present a novel VQA framework from the security-oriented perspective, termed SecureVQA. Extensive experiments indicate that SecureVQA sets a new benchmark in security while achieving competitive VQA performance compared with state-of-the-art models. Ablation studies delve deeper into analyzing the principles of SecureVQA, demonstrating their generalization and contributions to the security of leading VQA models.
AIM 2024 Challenge on Video Super-Resolution Quality Assessment: Methods and Results
Oct 05, 2024



This paper presents the Video Super-Resolution (SR) Quality Assessment (QA) Challenge that was part of the Advances in Image Manipulation (AIM) workshop, held in conjunction with ECCV 2024. The task of this challenge was to develop an objective QA method for videos upscaled 2x and 4x by modern image- and video-SR algorithms. QA methods were evaluated by comparing their output with aggregate subjective scores collected from >150,000 pairwise votes obtained through crowd-sourced comparisons across 52 SR methods and 1124 upscaled videos. The goal was to advance the state-of-the-art in SR QA, which had proven to be a challenging problem with limited applicability of traditional QA methods. The challenge had 29 registered participants, and 5 teams had submitted their final results, all outperforming the current state-of-the-art. All data, including the private test subset, has been made publicly available on the challenge homepage at https://challenges.videoprocessing.ai/challenges/super-resolution-metrics-challenge.html
AIM 2024 Challenge on Compressed Video Quality Assessment: Methods and Results
Aug 21, 2024



Video quality assessment (VQA) is a crucial task in the development of video compression standards, as it directly impacts the viewer experience. This paper presents the results of the Compressed Video Quality Assessment challenge, held in conjunction with the Advances in Image Manipulation (AIM) workshop at ECCV 2024. The challenge aimed to evaluate the performance of VQA methods on a diverse dataset of 459 videos, encoded with 14 codecs of various compression standards (AVC/H.264, HEVC/H.265, AV1, and VVC/H.266) and containing a comprehensive collection of compression artifacts. To measure the methods performance, we employed traditional correlation coefficients between their predictions and subjective scores, which were collected via large-scale crowdsourced pairwise human comparisons. For training purposes, participants were provided with the Compressed Video Quality Assessment Dataset (CVQAD), a previously developed dataset of 1022 videos. Up to 30 participating teams registered for the challenge, while we report the results of 6 teams, which submitted valid final solutions and code for reproducing the results. Moreover, we calculated and present the performance of state-of-the-art VQA methods on the developed dataset, providing a comprehensive benchmark for future research. The dataset, results, and online leaderboard are publicly available at https://challenges.videoprocessing.ai/challenges/compressed-video-quality-assessment.html.
Black-box Adversarial Attacks Against Image Quality Assessment Models
Feb 28, 2024



The goal of No-Reference Image Quality Assessment (NR-IQA) is to predict the perceptual quality of an image in line with its subjective evaluation. To put the NR-IQA models into practice, it is essential to study their potential loopholes for model refinement. This paper makes the first attempt to explore the black-box adversarial attacks on NR-IQA models. Specifically, we first formulate the attack problem as maximizing the deviation between the estimated quality scores of original and perturbed images, while restricting the perturbed image distortions for visual quality preservation. Under such formulation, we then design a Bi-directional loss function to mislead the estimated quality scores of adversarial examples towards an opposite direction with maximum deviation. On this basis, we finally develop an efficient and effective black-box attack method against NR-IQA models. Extensive experiments reveal that all the evaluated NR-IQA models are vulnerable to the proposed attack method. And the generated perturbations are not transferable, enabling them to serve the investigation of specialities of disparate IQA models.
Vulnerabilities in Video Quality Assessment Models: The Challenge of Adversarial Attacks
Sep 24, 2023



No-Reference Video Quality Assessment (NR-VQA) plays an essential role in improving the viewing experience of end-users. Driven by deep learning, recent NR-VQA models based on Convolutional Neural Networks (CNNs) and Transformers have achieved outstanding performance. To build a reliable and practical assessment system, it is of great necessity to evaluate their robustness. However, such issue has received little attention in the academic community. In this paper, we make the first attempt to evaluate the robustness of NR-VQA models against adversarial attacks under black-box setting, and propose a patch-based random search method for black-box attack. Specifically, considering both the attack effect on quality score and the visual quality of adversarial video, the attack problem is formulated as misleading the estimated quality score under the constraint of just-noticeable difference (JND). Built upon such formulation, a novel loss function called Score-Reversed Boundary Loss is designed to push the adversarial video's estimated quality score far away from its ground-truth score towards a specific boundary, and the JND constraint is modeled as a strict $L_2$ and $L_\infty$ norm restriction. By this means, both white-box and black-box attacks can be launched in an effective and imperceptible manner. The source code is available at https://github.com/GZHU-DVL/AttackVQA.
HVS Revisited: A Comprehensive Video Quality Assessment Framework
Oct 09, 2022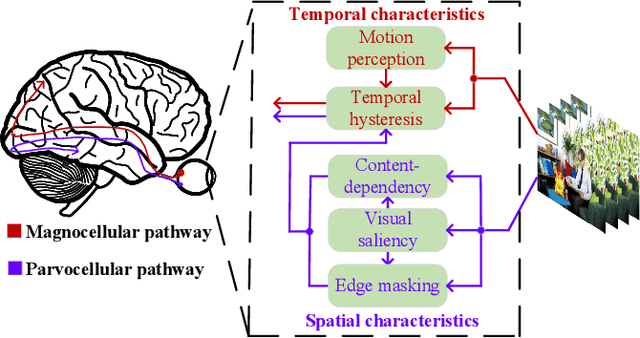
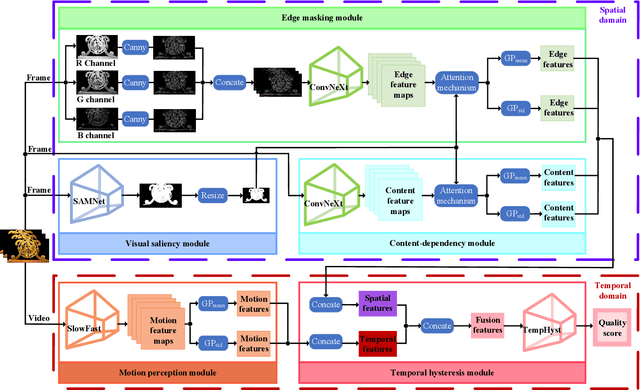

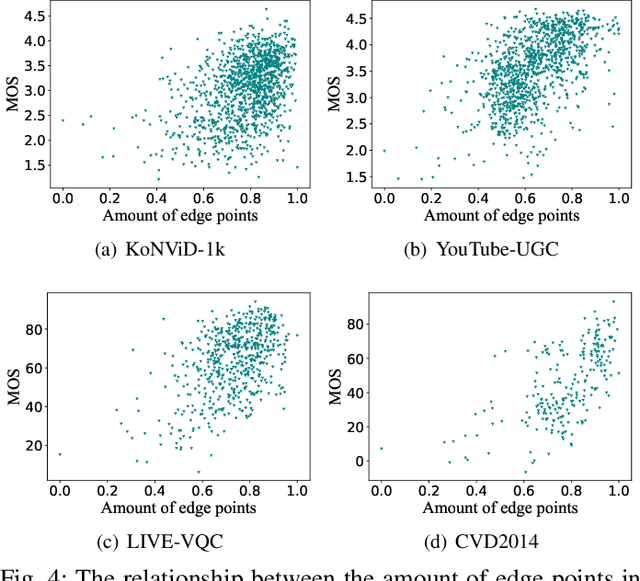
Video quality is a primary concern for video service providers. In recent years, the techniques of video quality assessment (VQA) based on deep convolutional neural networks (CNNs) have been developed rapidly. Although existing works attempt to introduce the knowledge of the human visual system (HVS) into VQA, there still exhibit limitations that prevent the full exploitation of HVS, including an incomplete model by few characteristics and insufficient connections among these characteristics. To overcome these limitations, this paper revisits HVS with five representative characteristics, and further reorganizes their connections. Based on the revisited HVS, a no-reference VQA framework called HVS-5M (NRVQA framework with five modules simulating HVS with five characteristics) is proposed. It works in a domain-fusion design paradigm with advanced network structures. On the side of the spatial domain, the visual saliency module applies SAMNet to obtain a saliency map. And then, the content-dependency and the edge masking modules respectively utilize ConvNeXt to extract the spatial features, which have been attentively weighted by the saliency map for the purpose of highlighting those regions that human beings may be interested in. On the other side of the temporal domain, to supplement the static spatial features, the motion perception module utilizes SlowFast to obtain the dynamic temporal features. Besides, the temporal hysteresis module applies TempHyst to simulate the memory mechanism of human beings, and comprehensively evaluates the quality score according to the fusion features from the spatial and temporal domains. Extensive experiments show that our HVS-5M outperforms the state-of-the-art VQA methods. Ablation studies are further conducted to verify the effectiveness of each module towards the proposed framework.