 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfinityDrive: Breaking Time Limits in Driving World Models
Dec 02, 2024



Autonomous driving systems struggle with complex scenarios due to limited access to diverse, extensive, and out-of-distribution driving data which are critical for safe navigation. World models offer a promising solution to this challenge; however, current driving world models are constrained by short time windows and limited scenario diversity. To bridge this gap, we introduce InfinityDrive, the first driving world model with exceptional generalization capabilities, delivering state-of-the-art performance in high fidelity, consistency, and diversity with minute-scale video generation. InfinityDrive introduces an efficient spatio-temporal co-modeling module paired with an extended temporal training strategy, enabling high-resolution (576$\times$1024) video generation with consistent spatial and temporal coherence. By incorporating memory injection and retention mechanisms alongside an adaptive memory curve loss to minimize cumulative errors, achieving consistent video generation lasting over 1500 frames (approximately 2 minutes). Comprehensive experiments in multiple datasets validate InfinityDrive's ability to generate complex and varied scenarios, highlighting its potential as a next-generation driving world model built for the evolving demands of autonomous driving. Our project homepage: https://metadrivescape.github.io/papers_project/InfinityDrive/page.html
Secure Video Quality Assessment Resisting Adversarial Attacks
Oct 09, 2024The exponential surge in video traffic has intensified the imperative for Video Quality Assessment (VQA). Leveraging cutting-edge architectures, current VQA models have achieved human-comparable accuracy. However, recent studies have revealed the vulnerability of existing VQA models against adversarial attacks. To establish a reliable and practical assessment system, a secure VQA model capable of resisting such malicious attacks is urgently demanded. Unfortunately, no attempt has been made to explore this issue. This paper first attempts to investigate general adversarial defense principles, aiming at endowing existing VQA models with security. Specifically, we first introduce random spatial grid sampling on the video frame for intra-frame defense. Then, we design pixel-wise randomization through a guardian map, globally neutralizing adversarial perturbations. Meanwhile, we extract temporal information from the video sequence as compensation for inter-frame defense. Building upon these principles, we present a novel VQA framework from the security-oriented perspective, termed SecureVQA. Extensive experiments indicate that SecureVQA sets a new benchmark in security while achieving competitive VQA performance compared with state-of-the-art models. Ablation studies delve deeper into analyzing the principles of SecureVQA, demonstrating their generalization and contributions to the security of leading VQA models.
DriveScape: Towards High-Resolution Controllable Multi-View Driving Video Generation
Sep 11, 2024



Recent advancements in generative models have provided promising solutions for synthesizing realistic driving videos, which are crucial for training autonomous driving perception models. However, existing approaches often struggle with multi-view video generation due to the challenges of integrating 3D information while maintaining spatial-temporal consistency and effectively learning from a unified model. In this paper, we propose an end-to-end framework named DriveScape for multi-view, 3D condition-guided video generation. DriveScape not only streamlines the process by integrating camera data to ensure comprehensive spatial-temporal coverage, but also introduces a Bi-Directional Modulated Transformer module to effectively align 3D road structural information. As a result, our approach enables precise control over video generation, significantly enhancing realism and providing a robust solution for generating multi-view driving videos. Our framework achieves state-of-the-art results on the nuScenes dataset, demonstrating impressive generative quality metrics with an FID score of 8.34 and an FVD score of 76.39, as well as superior performance across various perception tasks. This paves the way for more accurate environmental simulations in autonomous driving. Our project homepage: https://metadrivescape.github.io/papers_project/drivescapev1/index.html
SGC-VQGAN: Towards Complex Scene Representation via Semantic Guided Clustering Codebook
Sep 09, 2024Vector quantization (VQ) is a method for deterministically learning features through discrete codebook representations. Recent works have utilized visual tokenizers to discretize visual regions for self-supervised representation learning. However, a notable limitation of these tokenizers is lack of semantics, as they are derived solely from the pretext task of reconstructing raw image pixels in an auto-encoder paradigm. Additionally, issues like imbalanced codebook distribution and codebook collapse can adversely impact performance due to inefficient codebook utilization. To address these challenges, We introduce SGC-VQGAN through Semantic Online Clustering method to enhance token semantics through Consistent Semantic Learning. Utilizing inference results from segmentation model , our approach constructs a temporospatially consistent semantic codebook, addressing issues of codebook collapse and imbalanced token semantics. Our proposed Pyramid Feature Learning pipeline integrates multi-level features to capture both image details and semantics simultaneously. As a result, SGC-VQGAN achieves SOTA performance in both reconstruction quality and various downstream tasks. Its simplicity, requiring no additional parameter learning, enables its direct application in downstream tasks, presenting significant potential.
Black-box Adversarial Attacks Against Image Quality Assessment Models
Feb 28, 2024



The goal of No-Reference Image Quality Assessment (NR-IQA) is to predict the perceptual quality of an image in line with its subjective evaluation. To put the NR-IQA models into practice, it is essential to study their potential loopholes for model refinement. This paper makes the first attempt to explore the black-box adversarial attacks on NR-IQA models. Specifically, we first formulate the attack problem as maximizing the deviation between the estimated quality scores of original and perturbed images, while restricting the perturbed image distortions for visual quality preservation. Under such formulation, we then design a Bi-directional loss function to mislead the estimated quality scores of adversarial examples towards an opposite direction with maximum deviation. On this basis, we finally develop an efficient and effective black-box attack method against NR-IQA models. Extensive experiments reveal that all the evaluated NR-IQA models are vulnerable to the proposed attack method. And the generated perturbations are not transferable, enabling them to serve the investigation of specialities of disparate IQA models.
Vulnerabilities in Video Quality Assessment Models: The Challenge of Adversarial Attacks
Sep 24, 2023



No-Reference Video Quality Assessment (NR-VQA) plays an essential role in improving the viewing experience of end-users. Driven by deep learning, recent NR-VQA models based on Convolutional Neural Networks (CNNs) and Transformers have achieved outstanding performance. To build a reliable and practical assessment system, it is of great necessity to evaluate their robustness. However, such issue has received little attention in the academic community. In this paper, we make the first attempt to evaluate the robustness of NR-VQA models against adversarial attacks under black-box setting, and propose a patch-based random search method for black-box attack. Specifically, considering both the attack effect on quality score and the visual quality of adversarial video, the attack problem is formulated as misleading the estimated quality score under the constraint of just-noticeable difference (JND). Built upon such formulation, a novel loss function called Score-Reversed Boundary Loss is designed to push the adversarial video's estimated quality score far away from its ground-truth score towards a specific boundary, and the JND constraint is modeled as a strict $L_2$ and $L_\infty$ norm restriction. By this means, both white-box and black-box attacks can be launched in an effective and imperceptible manner. The source code is available at https://github.com/GZHU-DVL/AttackVQA.
StarVQA+: Co-training Space-Time Attention for Video Quality Assessment
Jun 21, 2023Self-attention based Transformer has achieved great success in many computer vision tasks. However, its application to video quality assessment (VQA) has not been satisfactory so far. Evaluating the quality of in-the-wild videos is challenging due to the unknown of pristine reference and shooting distortion. This paper presents a co-trained Space-Time Attention network for the VQA problem, termed StarVQA+. Specifically, we first build StarVQA+ by alternately concatenating the divided space-time attention. Then, to facilitate the training of StarVQA+, we design a vectorized regression loss by encoding the mean opinion score (MOS) to the probability vector and embedding a special token as the learnable variable of MOS, leading to better fitting of human's rating process. Finally, to solve the data hungry problem with Transformer, we propose to co-train the spatial and temporal attention weights using both images and videos. Various experiments are conducted on the de-facto in-the-wild video datasets, including LIVE-Qualcomm, LIVE-VQC, KoNViD-1k, YouTube-UGC, LSVQ, LSVQ-1080p, and DVL2021. Experimental results demonstrate the superiority of the proposed StarVQA+ over the state-of-the-art.
HVS Revisited: A Comprehensive Video Quality Assessment Framework
Oct 09, 2022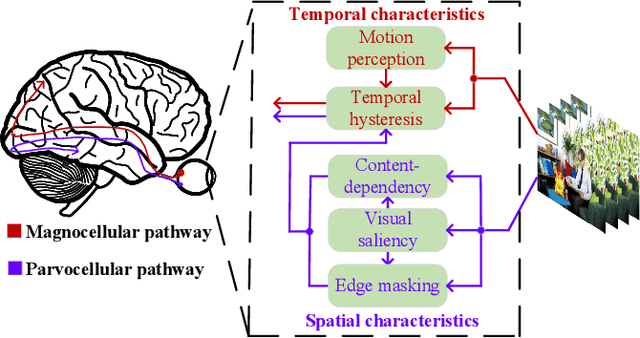
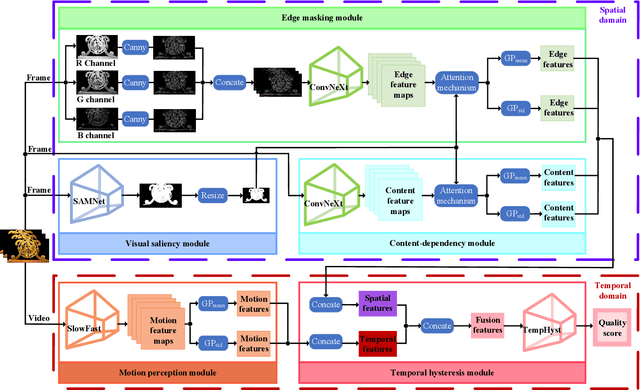

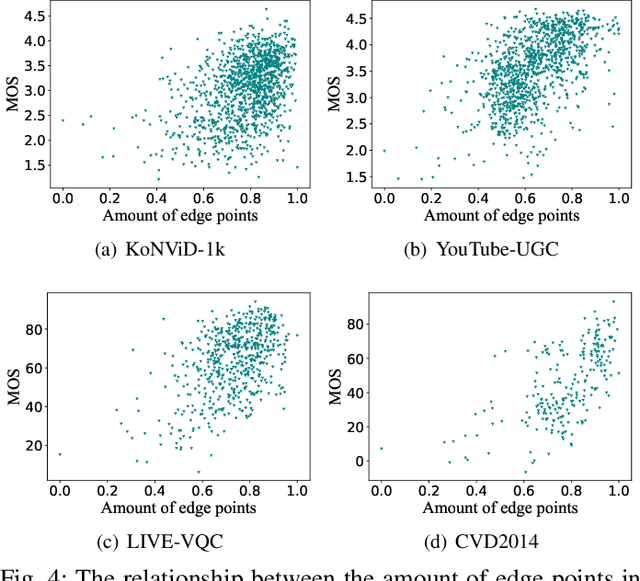
Video quality is a primary concern for video service providers. In recent years, the techniques of video quality assessment (VQA) based on deep convolutional neural networks (CNNs) have been developed rapidly. Although existing works attempt to introduce the knowledge of the human visual system (HVS) into VQA, there still exhibit limitations that prevent the full exploitation of HVS, including an incomplete model by few characteristics and insufficient connections among these characteristics. To overcome these limitations, this paper revisits HVS with five representative characteristics, and further reorganizes their connections. Based on the revisited HVS, a no-reference VQA framework called HVS-5M (NRVQA framework with five modules simulating HVS with five characteristics) is proposed. It works in a domain-fusion design paradigm with advanced network structures. On the side of the spatial domain, the visual saliency module applies SAMNet to obtain a saliency map. And then, the content-dependency and the edge masking modules respectively utilize ConvNeXt to extract the spatial features, which have been attentively weighted by the saliency map for the purpose of highlighting those regions that human beings may be interested in. On the other side of the temporal domain, to supplement the static spatial features, the motion perception module utilizes SlowFast to obtain the dynamic temporal features. Besides, the temporal hysteresis module applies TempHyst to simulate the memory mechanism of human beings, and comprehensively evaluates the quality score according to the fusion features from the spatial and temporal domains. Extensive experiments show that our HVS-5M outperforms the state-of-the-art VQA methods. Ablation studies are further conducted to verify the effectiveness of each module towards the proposed framework.
Multi-instance Point Cloud Registration by Efficient Correspondence Clustering
Nov 29, 2021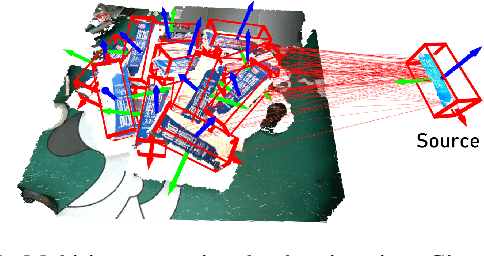
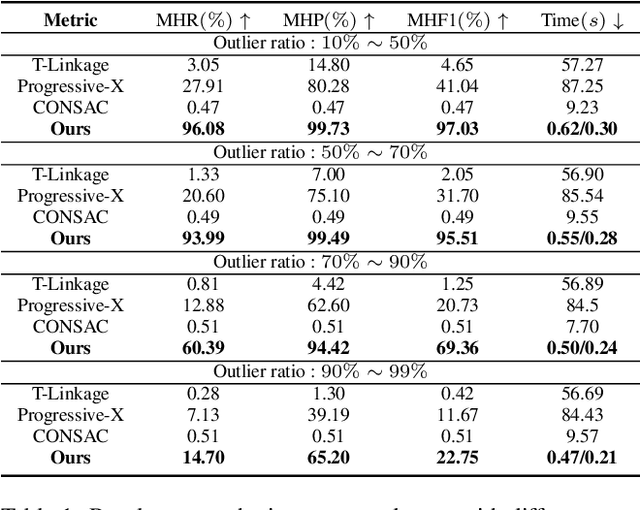

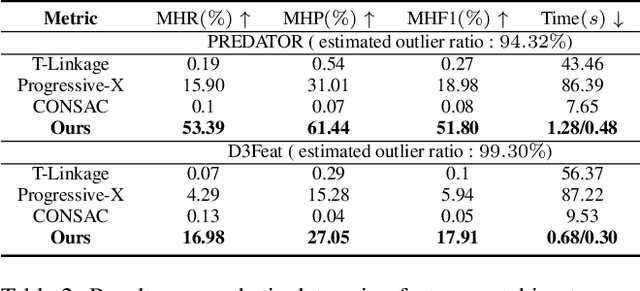
We address the problem of estimating the poses of multiple instances of the source point cloud within a target point cloud. Existing solutions require sampling a lot of hypotheses to detect possible instances and reject the outliers, whose robustness and efficiency degrade notably when the number of instances and outliers increase. We propose to directly group the set of noisy correspondences into different clusters based on a distance invariance matrix. The instances and outliers are automatically identified through clustering. Our method is robust and fast. We evaluated our method on both synthetic and real-world datasets. The results show that our approach can correctly register up to 20 instances with an F1 score of 90.46% in the presence of 70% outliers, which performs significantly better and at least 10x faster than existing methods
Improving Cost Learning for JPEG Steganography by Exploiting JPEG Domain Knowledge
May 09, 2021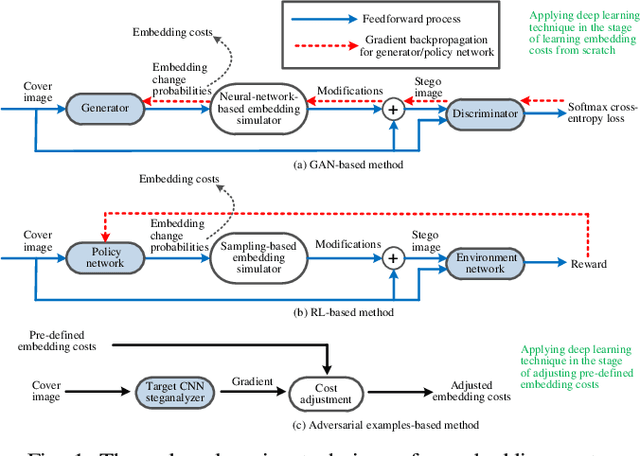
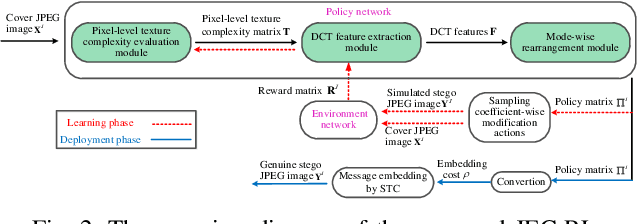
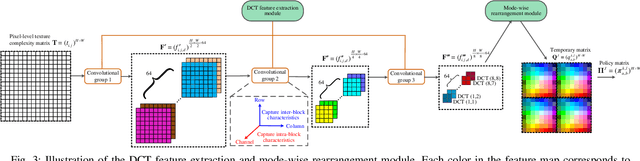

Although significant progress in automatic learning of steganographic cost has been achieved recently, existing methods designed for spatial images are not well applicable to JPEG images which are more common media in daily life. The difficulties of migration mostly lie in the unique and complicated JPEG characteristics caused by 8x8 DCT mode structure. To address the issue, in this paper we extend an existing automatic cost learning scheme to JPEG, where the proposed scheme called JEC-RL (JPEG Embedding Cost with Reinforcement Learning) is explicitly designed to tailor the JPEG DCT structure. It works with the embedding action sampling mechanism under reinforcement learning, where a policy network learns the optimal embedding policies via maximizing the rewards provided by an environment network. The policy network is constructed following a domain-transition design paradigm, where three modules including pixel-level texture complexity evaluation, DCT feature extraction, and mode-wise rearrangement, are proposed. These modules operate in serial, gradually extracting useful features from a decompressed JPEG image and converting them into embedding policies for DCT elements, while considering JPEG characteristics including inter-block and intra-block correlations simultaneously. The environment network is designed in a gradient-oriented way to provide stable reward values by using a wide architecture equipped with a fixed preprocessing layer with 8x8 DCT basis filters. Extensive experiments and ablation studies demonstrate that the proposed method can achieve good security performance for JPEG images against both advanced feature based and modern CNN based steganalyzers.