 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Pre-trained Language Models End-to-end Few-shot Learners with Contrastive Prompt Tuning
Apr 01, 2022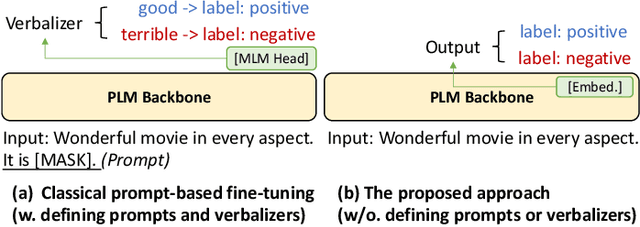

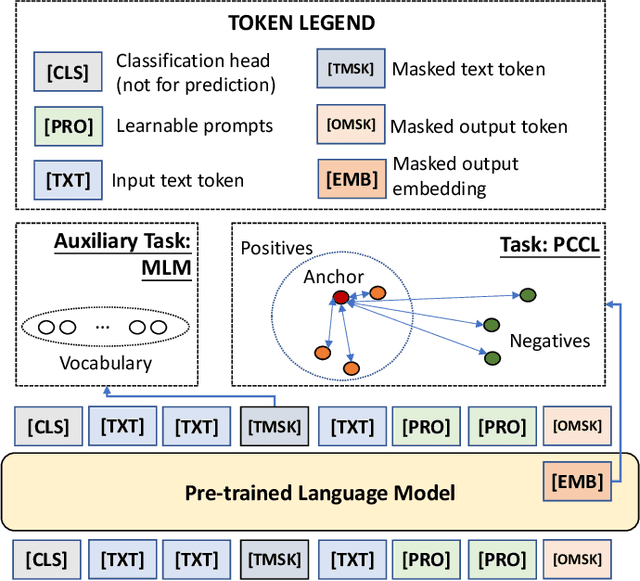
Pre-trained Language Models (PLMs) have achieved remarkable performance for various language understanding tasks in IR systems, which require the fine-tuning process based on labeled training data. For low-resource scenarios, prompt-based learning for PLMs exploits prompts as task guidance and turns downstream tasks into masked language problems for effective few-shot fine-tuning. In most existing approaches, the high performance of prompt-based learning heavily relies on handcrafted prompts and verbalizers, which may limit the application of such approaches in real-world scenarios. To solve this issue, we present CP-Tuning, the first end-to-end Contrastive Prompt Tuning framework for fine-tuning PLMs without any manual engineering of task-specific prompts and verbalizers. It is integrated with the task-invariant continuous prompt encoding technique with fully trainable prompt parameters. We further propose the pair-wise cost-sensitive contrastive learning procedure to optimize the model in order to achieve verbalizer-free class mapping and enhance the task-invariance of prompts. It explicitly learns to distinguish different classes and makes the decision boundary smoother by assigning different costs to easy and hard cases. Experiments over a variety of language understanding tasks used in IR systems and different PLMs show that CP-Tuning outperforms state-of-the-art methods.
DKPLM: Decomposable Knowledge-enhanced Pre-trained Language Model for Natural Language Understanding
Dec 02, 2021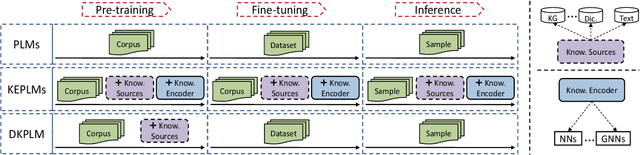
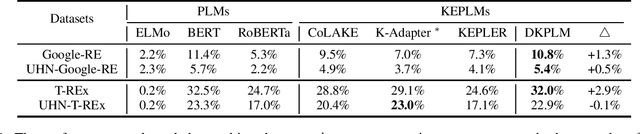
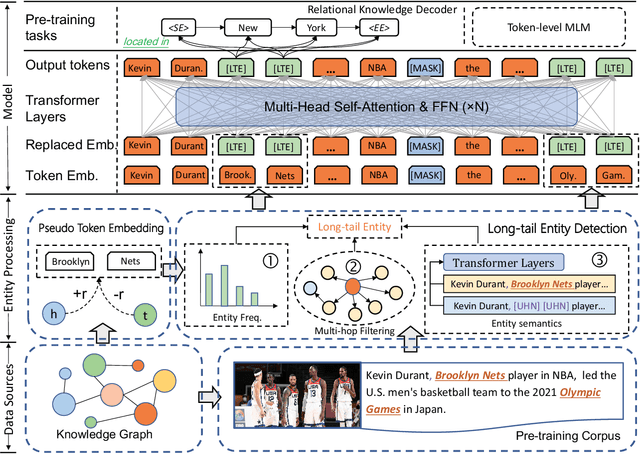
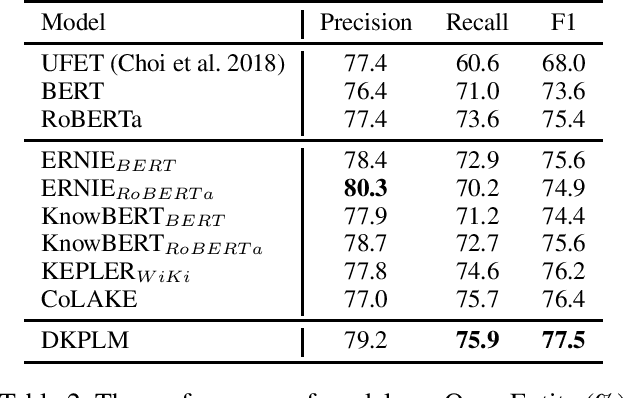
Knowledge-Enhanced Pre-trained Language Models (KEPLMs) are pre-trained models with relation triples injecting from knowledge graphs to improve language understanding abilities. To guarantee effective knowledge injection, previous studies integrate models with knowledge encoders for representing knowledge retrieved from knowledge graphs. The operations for knowledge retrieval and encoding bring significant computational burdens, restricting the usage of such models in real-world applications that require high inference speed. In this paper, we propose a novel KEPLM named DKPLM that Decomposes Knowledge injection process of the Pre-trained Language Models in pre-training, fine-tuning and inference stages, which facilitates the applications of KEPLMs in real-world scenarios. Specifically, we first detect knowledge-aware long-tail entities as the target for knowledge injection, enhancing the KEPLMs' semantic understanding abilities and avoiding injecting redundant information. The embeddings of long-tail entities are replaced by "pseudo token representations" formed by relevant knowledge triples. We further design the relational knowledge decoding task for pre-training to force the models to truly understand the injected knowledge by relation triple reconstruction. Experiments show that our model outperforms other KEPLMs significantly over zero-shot knowledge probing tasks and multiple knowledge-aware language understanding tasks. We further show that DKPLM has a higher inference speed than other competing models due to the decomposing mechanism.
HRKD: Hierarchical Relational Knowledge Distillation for Cross-domain Language Model Compression
Oct 16, 2021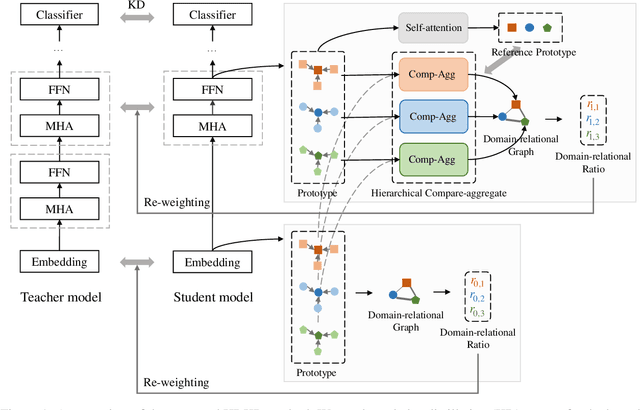
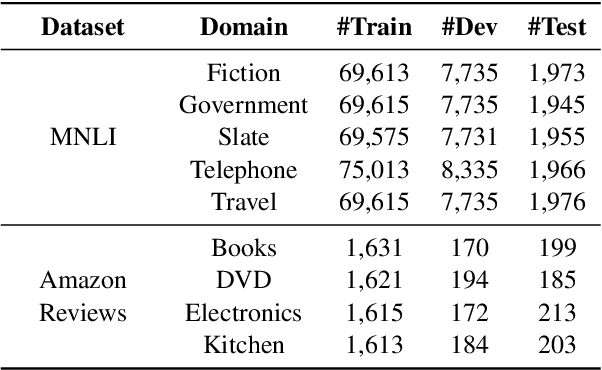
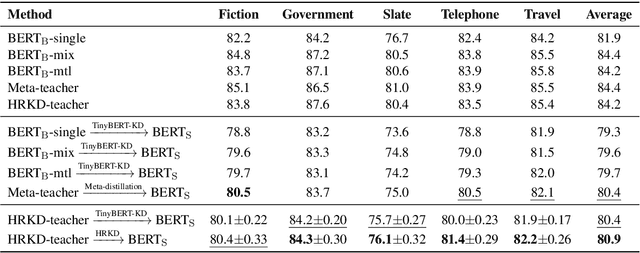
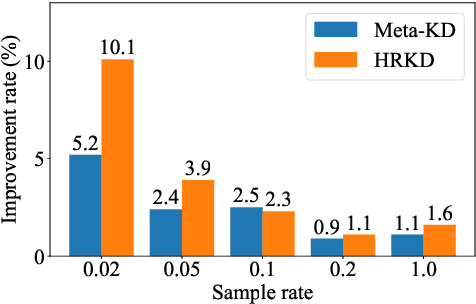
On many natural language processing tasks, large pre-trained language models (PLMs) have shown overwhelming performances compared with traditional neural network methods. Nevertheless, their huge model size and low inference speed have hindered the deployment on resource-limited devices in practice. In this paper, we target to compress PLMs with knowledge distillation, and propose a hierarchical relational knowledge distillation (HRKD) method to capture both hierarchical and domain relational information. Specifically, to enhance the model capability and transferability, we leverage the idea of meta-learning and set up domain-relational graphs to capture the relational information across different domains. And to dynamically select the most representative prototypes for each domain, we propose a hierarchical compare-aggregate mechanism to capture hierarchical relationships. Extensive experiments on public multi-domain datasets demonstrate the superior performance of our HRKD method as well as its strong few-shot learning ability. For reproducibility, we release the code at https://github.com/cheneydon/hrkd.
SMedBERT: A Knowledge-Enhanced Pre-trained Language Model with Structured Semantics for Medical Text Mining
Aug 20, 2021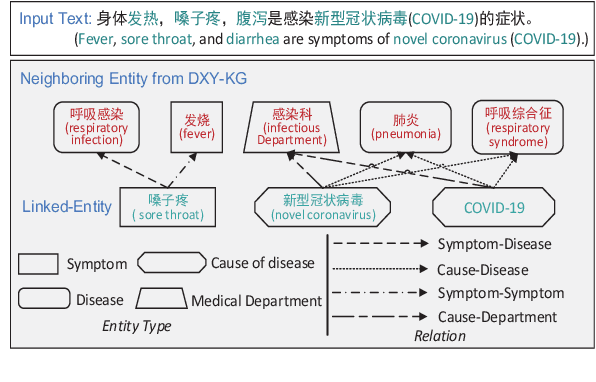
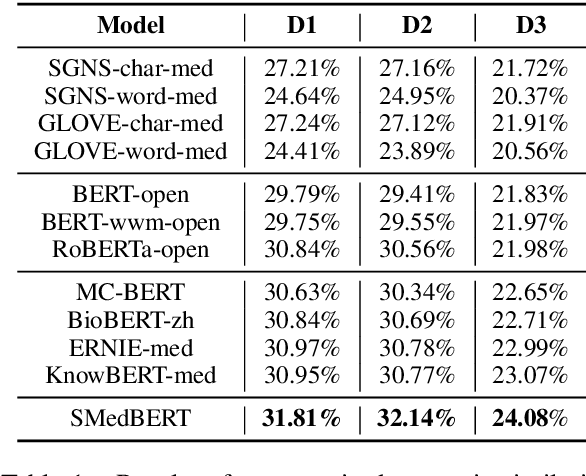
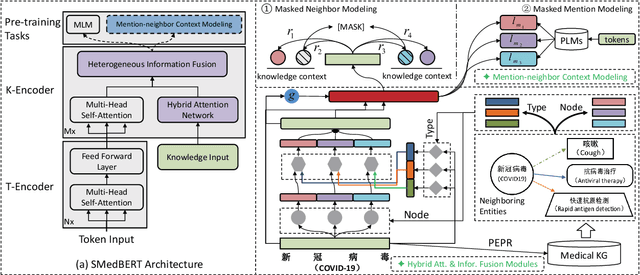
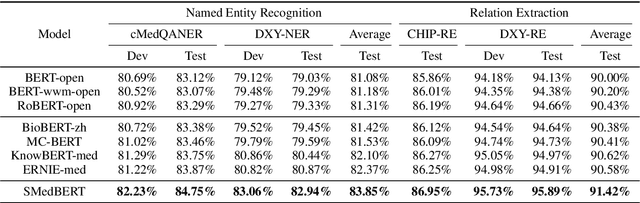
Recently, the performance of Pre-trained Language Models (PLMs) has been significantly improved by injecting knowledge facts to enhance their abilities of language understanding. For medical domains, the background knowledge sources are especially useful, due to the massive medical terms and their complicated relations are difficult to understand in text. In this work, we introduce SMedBERT, a medical PLM trained on large-scale medical corpora, incorporating deep structured semantic knowledge from neighbors of linked-entity.In SMedBERT, the mention-neighbor hybrid attention is proposed to learn heterogeneous-entity information, which infuses the semantic representations of entity types into the homogeneous neighboring entity structure. Apart from knowledge integration as external features, we propose to employ the neighbors of linked-entities in the knowledge graph as additional global contexts of text mentions, allowing them to communicate via shared neighbors, thus enrich their semantic representations. Experiments demonstrate that SMedBERT significantly outperforms strong baselines in various knowledge-intensive Chinese medical tasks. It also improves the performance of other tasks such as question answering, question matching and natural language inference.
Meta-Learning Adversarial Domain Adaptation Network for Few-Shot Text Classification
Jul 26, 2021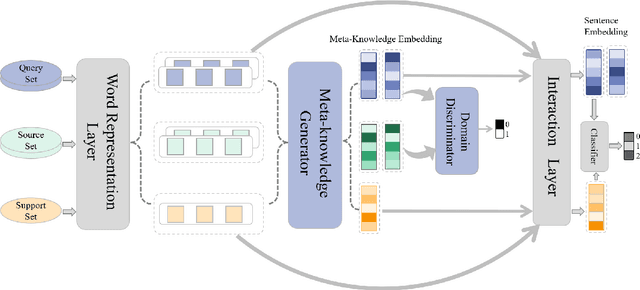
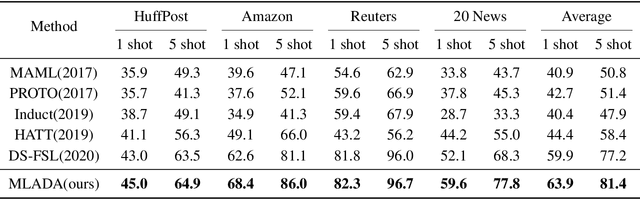
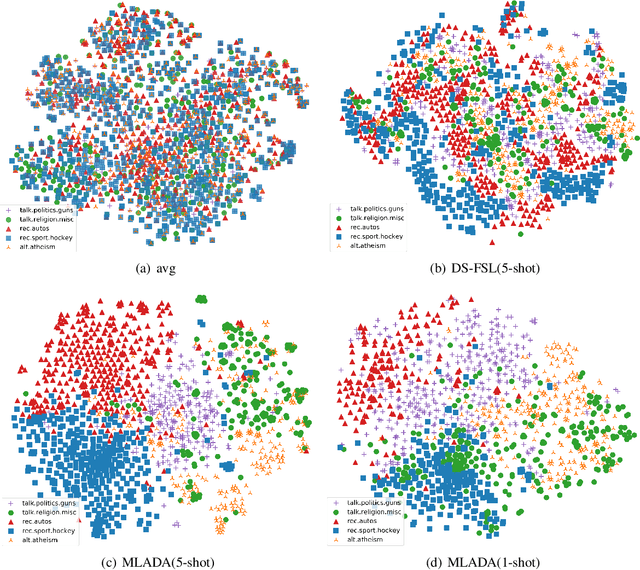
Meta-learning has emerged as a trending technique to tackle few-shot text classification and achieved state-of-the-art performance. However, existing solutions heavily rely on the exploitation of lexical features and their distributional signatures on training data, while neglecting to strengthen the model's ability to adapt to new tasks. In this paper, we propose a novel meta-learning framework integrated with an adversarial domain adaptation network, aiming to improve the adaptive ability of the model and generate high-quality text embedding for new classes. Extensive experiments are conducted on four benchmark datasets and our method demonstrates clear superiority over the state-of-the-art models in all the datasets. In particular, the accuracy of 1-shot and 5-shot classification on the dataset of 20 Newsgroups is boosted from 52.1% to 59.6%, and from 68.3% to 77.8%, respectively.
Global Context Enhanced Graph Neural Networks for Session-based Recommendation
Jun 09, 2021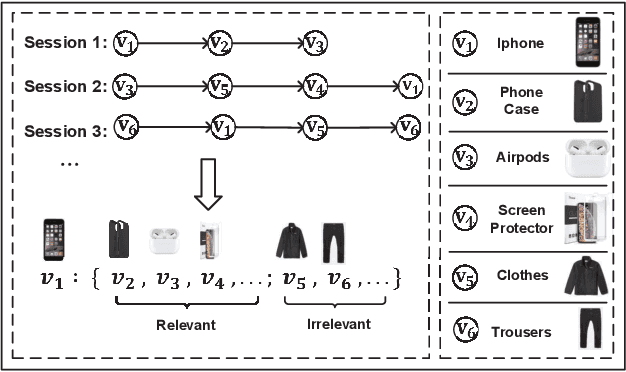
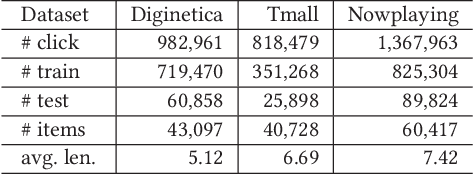
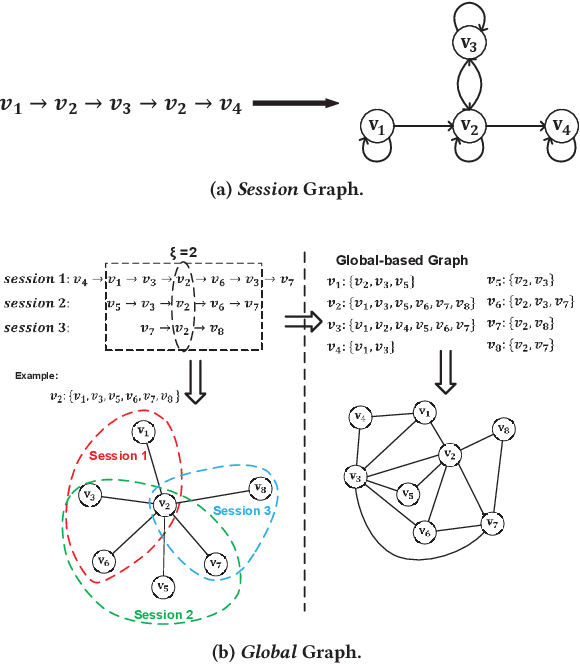
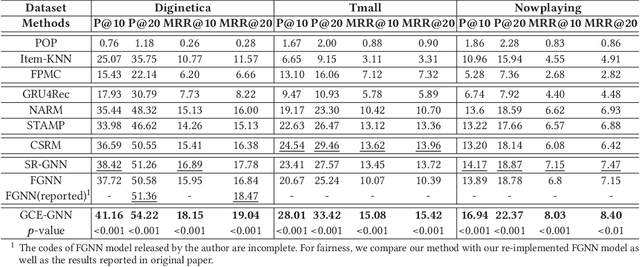
Session-based recommendation (SBR) is a challenging task, which aims at recommending items based on anonymous behavior sequences. Almost all the existing solutions for SBR model user preference only based on the current session without exploiting the other sessions, which may contain both relevant and irrelevant item-transitions to the current session. This paper proposes a novel approach, called Global Context Enhanced Graph Neural Networks (GCE-GNN) to exploit item transitions over all sessions in a more subtle manner for better inferring the user preference of the current session. Specifically, GCE-GNN learns two levels of item embeddings from session graph and global graph, respectively: (i) Session graph, which is to learn the session-level item embedding by modeling pairwise item-transitions within the current session; and (ii) Global graph, which is to learn the global-level item embedding by modeling pairwise item-transitions over all sessions. In GCE-GNN, we propose a novel global-level item representation learning layer, which employs a session-aware attention mechanism to recursively incorporate the neighbors' embeddings of each node on the global graph. We also design a session-level item representation learning layer, which employs a GNN on the session graph to learn session-level item embeddings within the current session. Moreover, GCE-GNN aggregates the learnt item representations in the two levels with a soft attention mechanism. Experiments on three benchmark datasets demonstrate that GCE-GNN outperforms the state-of-the-art methods consistently.
* arXiv admin note: substantial text overlap with arXiv:2011.10173
Kaleido-BERT: Vision-Language Pre-training on Fashion Domain
Apr 15, 2021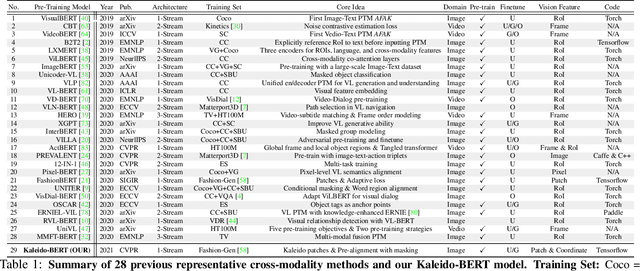
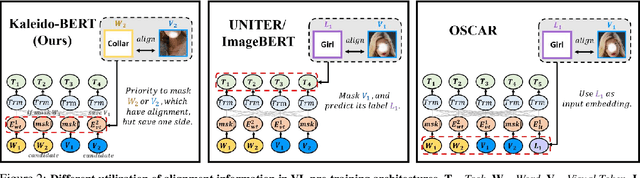
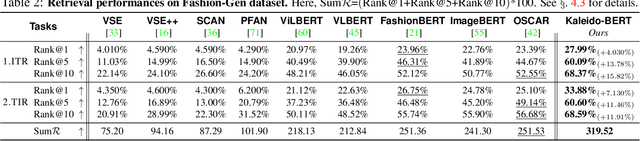
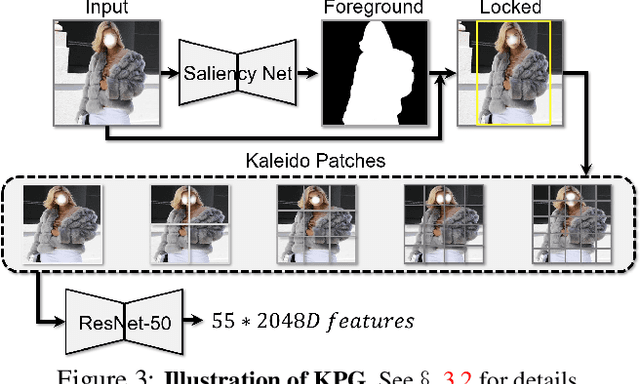
We present a new vision-language (VL) pre-training model dubbed Kaleido-BERT, which introduces a novel kaleido strategy for fashion cross-modality representations from transformers. In contrast to random masking strategy of recent VL models, we design alignment guided masking to jointly focus more on image-text semantic relations. To this end, we carry out five novel tasks, i.e., rotation, jigsaw, camouflage, grey-to-color, and blank-to-color for self-supervised VL pre-training at patches of different scale. Kaleido-BERT is conceptually simple and easy to extend to the existing BERT framework, it attains new state-of-the-art results by large margins on four downstream tasks, including text retrieval (R@1: 4.03% absolute improvement), image retrieval (R@1: 7.13% abs imv.), category recognition (ACC: 3.28% abs imv.), and fashion captioning (Bleu4: 1.2 abs imv.). We validate the efficiency of Kaleido-BERT on a wide range of e-commerical websites, demonstrating its broader potential in real-world applications.
Learning to Augment for Data-Scarce Domain BERT Knowledge Distillation
Jan 20, 2021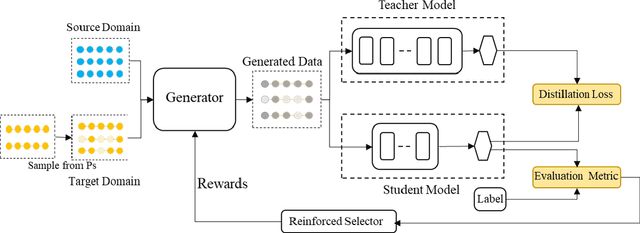
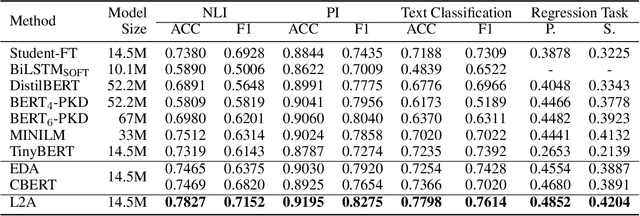
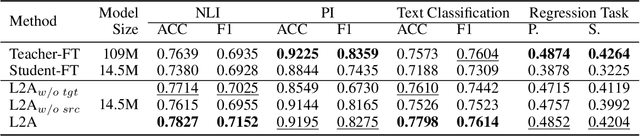
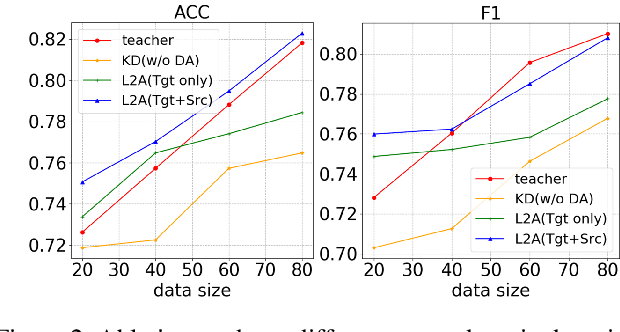
Despite pre-trained language models such as BERT have achieved appealing performance in a wide range of natural language processing tasks, they are computationally expensive to be deployed in real-time applications. A typical method is to adopt knowledge distillation to compress these large pre-trained models (teacher models) to small student models. However, for a target domain with scarce training data, the teacher can hardly pass useful knowledge to the student, which yields performance degradation for the student models. To tackle this problem, we propose a method to learn to augment for data-scarce domain BERT knowledge distillation, by learning a cross-domain manipulation scheme that automatically augments the target with the help of resource-rich source domains. Specifically, the proposed method generates samples acquired from a stationary distribution near the target data and adopts a reinforced selector to automatically refine the augmentation strategy according to the performance of the student. Extensive experiments demonstrate that the proposed method significantly outperforms state-of-the-art baselines on four different tasks, and for the data-scarce domains, the compressed student models even perform better than the original large teacher model, with much fewer parameters (only ${\sim}13.3\%$) when only a few labeled examples available.
Meta-KD: A Meta Knowledge Distillation Framework for Language Model Compression across Domains
Dec 02, 2020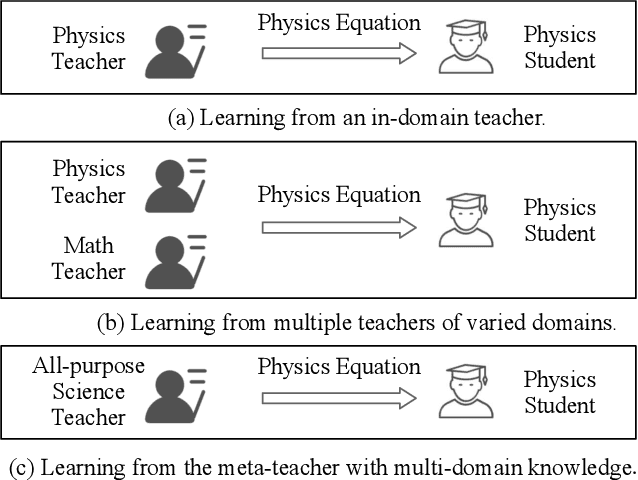
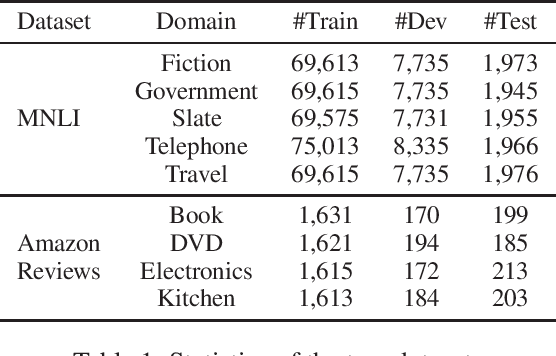
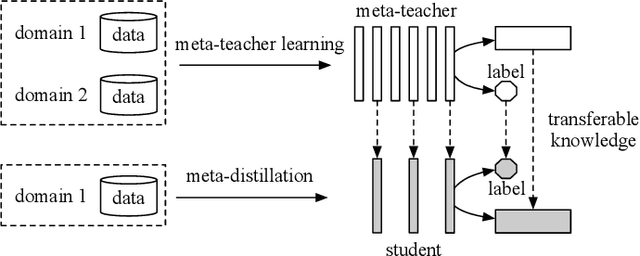
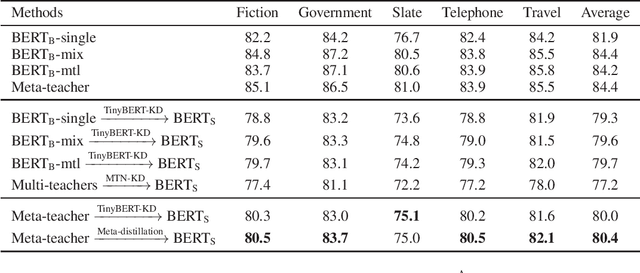
Pre-trained language models have been applied to various NLP tasks with considerable performance gains. However, the large model sizes, together with the long inference time, limit the deployment of such models in real-time applications. Typical approaches consider knowledge distillation to distill large teacher models into small student models. However, most of these studies focus on single-domain only, which ignores the transferable knowledge from other domains. We argue that training a teacher with transferable knowledge digested across domains can achieve better generalization capability to help knowledge distillation. To this end, we propose a Meta-Knowledge Distillation (Meta-KD) framework to build a meta-teacher model that captures transferable knowledge across domains inspired by meta-learning and use it to pass knowledge to students. Specifically, we first leverage a cross-domain learning process to train the meta-teacher on multiple domains, and then propose a meta-distillation algorithm to learn single-domain student models with guidance from the meta-teacher. Experiments on two public multi-domain NLP tasks show the effectiveness and superiority of the proposed Meta-KD framework. We also demonstrate the capability of Meta-KD in both few-shot and zero-shot learning settings.
Learning to Expand: Reinforced Pseudo-relevance Feedback Selection for Information-seeking Conversations
Nov 25, 2020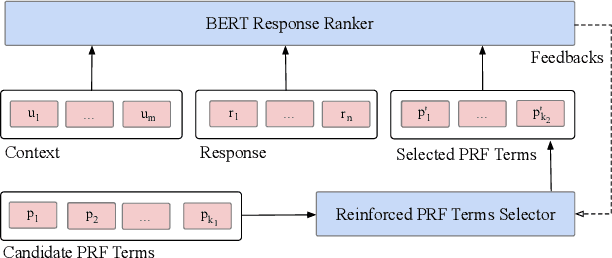
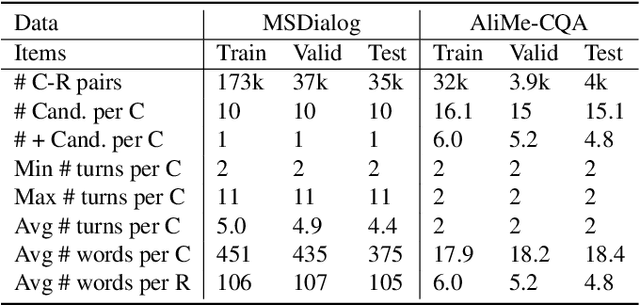
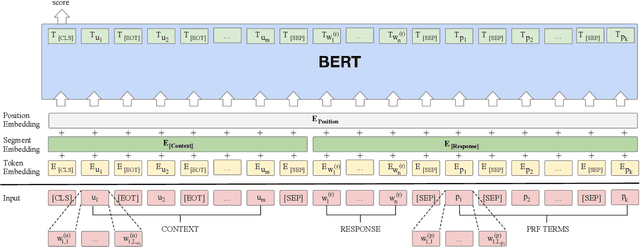
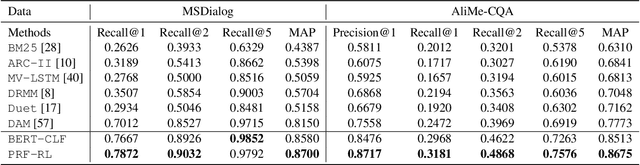
Intelligent personal assistant systems for information-seeking conversations are increasingly popular in real-world applications, especially for e-commerce companies. With the development of research in such conversation systems, the pseudo-relevance feedback (PRF) has demonstrated its effectiveness in incorporating relevance signals from external documents. However, the existing studies are either based on heuristic rules or require heavy manual labeling. In this work, we treat the PRF selection as a learning task and proposed a reinforced learning based method that can be trained in an end-to-end manner without any human annotations. More specifically, we proposed a reinforced selector to extract useful PRF terms to enhance response candidates and a BERT based response ranker to rank the PRF-enhanced responses. The performance of the ranker serves as rewards to guide the selector to extract useful PRF terms, and thus boost the task performance. Extensive experiments on both standard benchmark and commercial datasets show the superiority of our reinforced PRF term selector compared with other potential soft or hard selection methods. Both qualitative case studies and quantitative analysis show that our model can not only select meaningful PRF terms to expand response candidates but also achieve the best results compared with all the baseline methods on a variety of evaluation metrics. We have also deployed our method on online production in an e-commerce company, which shows a significant improvement over the existing online ranking system.