 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Masks to Worlds: A Hitchhiker's Guide to World Models
Oct 23, 2025This is not a typical survey of world models; it is a guide for those who want to build worlds. We do not aim to catalog every paper that has ever mentioned a ``world model". Instead, we follow one clear road: from early masked models that unified representation learning across modalities, to unified architectures that share a single paradigm, then to interactive generative models that close the action-perception loop, and finally to memory-augmented systems that sustain consistent worlds over time. We bypass loosely related branches to focus on the core: the generative heart, the interactive loop, and the memory system. We show that this is the most promising path towards true world models.
One Flight Over the Gap: A Survey from Perspective to Panoramic Vision
Sep 04, 2025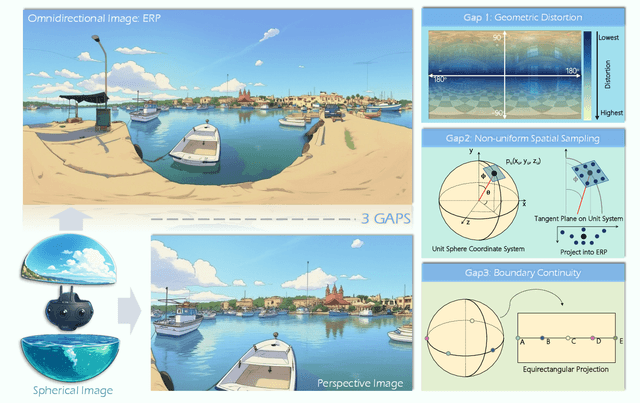
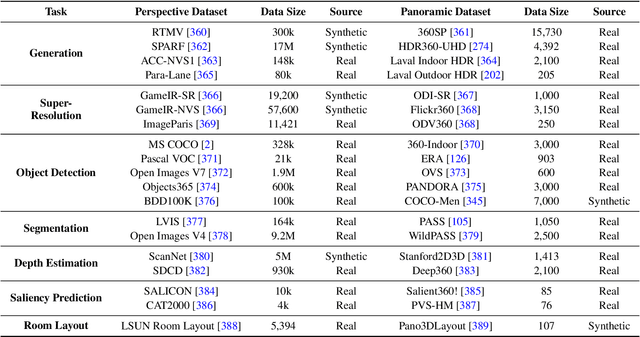
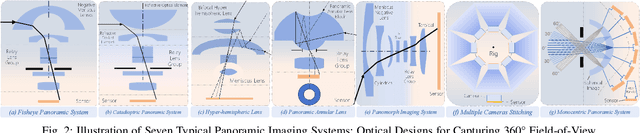
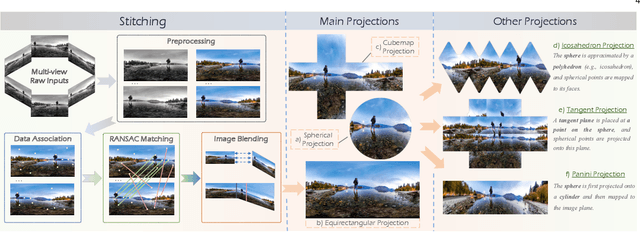
Driven by the demand for spatial intelligence and holistic scene perception, omnidirectional images (ODIs), which provide a complete 360\textdegree{} field of view, are receiving growing attention across diverse applications such as virtual reality, autonomous driving, and embodied robotics. Despite their unique characteristics, ODIs exhibit remarkable differences from perspective images in geometric projection, spatial distribution, and boundary continuity, making it challenging for direct domain adaption from perspective methods. This survey reviews recent panoramic vision techniques with a particular emphasis on the perspective-to-panorama adaptation. We first revisit the panoramic imaging pipeline and projection methods to build the prior knowledge required for analyzing the structural disparities. Then, we summarize three challenges of domain adaptation: severe geometric distortions near the poles, non-uniform sampling in Equirectangular Projection (ERP), and periodic boundary continuity. Building on this, we cover 20+ representative tasks drawn from more than 300 research papers in two dimensions. On one hand, we present a cross-method analysis of representative strategies for addressing panoramic specific challenges across different tasks. On the other hand, we conduct a cross-task comparison and classify panoramic vision into four major categories: visual quality enhancement and assessment, visual understanding, multimodal understanding, and visual generation. In addition, we discuss open challenges and future directions in data, models, and applications that will drive the advancement of panoramic vision research. We hope that our work can provide new insight and forward looking perspectives to advance the development of panoramic vision technologies. Our project page is https://insta360-research-team.github.io/Survey-of-Panorama
DrivingGaussian++: Towards Realistic Reconstruction and Editable Simulation for Surrounding Dynamic Driving Scenes
Aug 28, 2025We present DrivingGaussian++, an efficient and effective framework for realistic reconstructing and controllable editing of surrounding dynamic autonomous driving scenes. DrivingGaussian++ models the static background using incremental 3D Gaussians and reconstructs moving objects with a composite dynamic Gaussian graph, ensuring accurate positions and occlusions. By integrating a LiDAR prior, it achieves detailed and consistent scene reconstruction, outperforming existing methods in dynamic scene reconstruction and photorealistic surround-view synthesis. DrivingGaussian++ supports training-free controllable editing for dynamic driving scenes, including texture modification, weather simulation, and object manipulation, leveraging multi-view images and depth priors. By integrating large language models (LLMs) and controllable editing, our method can automatically generate dynamic object motion trajectories and enhance their realism during the optimization process. DrivingGaussian++ demonstrates consistent and realistic editing results and generates dynamic multi-view driving scenarios, while significantly enhancing scene diversity. More results and code can be found at the project site: https://xiong-creator.github.io/DrivingGaussian_plus.github.io
Blockwise SFT for Diffusion Language Models: Reconciling Bidirectional Attention and Autoregressive Decoding
Aug 27, 2025Discrete diffusion language models have shown strong potential for text generation, yet standard supervised fine-tuning (SFT) misaligns with their semi-autoregressive inference: training randomly masks tokens across the entire response, while inference generates fixed-size blocks sequentially. This mismatch introduces noisy prefixes and leaky suffixes, biasing gradients away from the desired blockwise likelihood. We propose Blockwise SFT, which partitions responses into fixed-size blocks, selects one active block per step for stochastic masking, freezes all preceding tokens, and fully hides future ones. Loss is computed only over the active block, directly mirroring the blockwise decoding process. Experiments on GSM8K, MATH, and MetaMathQA show consistent gains over classical SFT under equal compute or token budgets. Block size consistency studies and ablations confirm that improvements stem from faithful training-inference alignment rather than incidental masking effects. Our results highlight the importance of matching supervision granularity to the decoding procedure in diffusion-based language models.
MRFD: Multi-Region Fusion Decoding with Self-Consistency for Mitigating Hallucinations in LVLMs
Aug 14, 2025Large Vision-Language Models (LVLMs) have shown strong performance across multimodal tasks. However, they often produce hallucinations -- text that is inconsistent with visual input, due to the limited ability to verify information in different regions of the image. To address this, we propose Multi-Region Fusion Decoding (MRFD), a training-free decoding method that improves factual grounding by modeling inter-region consistency. MRFD identifies salient regions using cross-attention, generates initial responses for each, and computes reliability weights based on Jensen-Shannon Divergence (JSD) among the responses. These weights guide a consistency-aware fusion of per-region predictions, using region-aware prompts inspired by Chain-of-Thought reasoning. Experiments across multiple LVLMs and benchmarks show that MRFD significantly reduces hallucinations and improves response factuality without requiring model updates.
Human-in-Context: Unified Cross-Domain 3D Human Motion Modeling via In-Context Learning
Aug 14, 2025This paper aims to model 3D human motion across domains, where a single model is expected to handle multiple modalities, tasks, and datasets. Existing cross-domain models often rely on domain-specific components and multi-stage training, which limits their practicality and scalability. To overcome these challenges, we propose a new setting to train a unified cross-domain model through a single process, eliminating the need for domain-specific components and multi-stage training. We first introduce Pose-in-Context (PiC), which leverages in-context learning to create a pose-centric cross-domain model. While PiC generalizes across multiple pose-based tasks and datasets, it encounters difficulties with modality diversity, prompting strategy, and contextual dependency handling. We thus propose Human-in-Context (HiC), an extension of PiC that broadens generalization across modalities, tasks, and datasets. HiC combines pose and mesh representations within a unified framework, expands task coverage, and incorporates larger-scale datasets. Additionally, HiC introduces a max-min similarity prompt sampling strategy to enhance generalization across diverse domains and a network architecture with dual-branch context injection for improved handling of contextual dependencies. Extensive experimental results show that HiC performs better than PiC in terms of generalization, data scale, and performance across a wide range of domains. These results demonstrate the potential of HiC for building a unified cross-domain 3D human motion model with improved flexibility and scalability. The source codes and models are available at https://github.com/BradleyWang0416/Human-in-Context.
On the Generalization of SFT: A Reinforcement Learning Perspective with Reward Rectification
Aug 07, 2025We present a simple yet theoretically motivated improvement to Supervised Fine-Tuning (SFT) for the Large Language Model (LLM), addressing its limited generalization compared to reinforcement learning (RL). Through mathematical analysis, we reveal that standard SFT gradients implicitly encode a problematic reward structure that may severely restrict the generalization capabilities of model. To rectify this, we propose Dynamic Fine-Tuning (DFT), stabilizing gradient updates for each token by dynamically rescaling the objective function with the probability of this token. Remarkably, this single-line code change significantly outperforms standard SFT across multiple challenging benchmarks and base models, demonstrating greatly improved generalization. Additionally, our approach shows competitive results in offline RL settings, offering an effective yet simpler alternative. This work bridges theoretical insight and practical solutions, substantially advancing SFT performance. The code will be available at https://github.com/yongliang-wu/DFT.
Learning Deblurring Texture Prior from Unpaired Data with Diffusion Model
Jul 18, 2025



Since acquiring large amounts of realistic blurry-sharp image pairs is difficult and expensive, learning blind image deblurring from unpaired data is a more practical and promising solution. Unfortunately, dominant approaches rely heavily on adversarial learning to bridge the gap from blurry domains to sharp domains, ignoring the complex and unpredictable nature of real-world blur patterns. In this paper, we propose a novel diffusion model (DM)-based framework, dubbed \ours, for image deblurring by learning spatially varying texture prior from unpaired data. In particular, \ours performs DM to generate the prior knowledge that aids in recovering the textures of blurry images. To implement this, we propose a Texture Prior Encoder (TPE) that introduces a memory mechanism to represent the image textures and provides supervision for DM training. To fully exploit the generated texture priors, we present the Texture Transfer Transformer layer (TTformer), in which a novel Filter-Modulated Multi-head Self-Attention (FM-MSA) efficiently removes spatially varying blurring through adaptive filtering. Furthermore, we implement a wavelet-based adversarial loss to preserve high-frequency texture details. Extensive evaluations show that \ours provides a promising unsupervised deblurring solution and outperforms SOTA methods in widely-used benchmarks.
4KAgent: Agentic Any Image to 4K Super-Resolution
Jul 09, 2025We present 4KAgent, a unified agentic super-resolution generalist system designed to universally upscale any image to 4K resolution (and even higher, if applied iteratively). Our system can transform images from extremely low resolutions with severe degradations, for example, highly distorted inputs at 256x256, into crystal-clear, photorealistic 4K outputs. 4KAgent comprises three core components: (1) Profiling, a module that customizes the 4KAgent pipeline based on bespoke use cases; (2) A Perception Agent, which leverages vision-language models alongside image quality assessment experts to analyze the input image and make a tailored restoration plan; and (3) A Restoration Agent, which executes the plan, following a recursive execution-reflection paradigm, guided by a quality-driven mixture-of-expert policy to select the optimal output for each step. Additionally, 4KAgent embeds a specialized face restoration pipeline, significantly enhancing facial details in portrait and selfie photos. We rigorously evaluate our 4KAgent across 11 distinct task categories encompassing a total of 26 diverse benchmarks, setting new state-of-the-art on a broad spectrum of imaging domains. Our evaluations cover natural images, portrait photos, AI-generated content, satellite imagery, fluorescence microscopy, and medical imaging like fundoscopy, ultrasound, and X-ray, demonstrating superior performance in terms of both perceptual (e.g., NIQE, MUSIQ) and fidelity (e.g., PSNR) metrics. By establishing a novel agentic paradigm for low-level vision tasks, we aim to catalyze broader interest and innovation within vision-centric autonomous agents across diverse research communities. We will release all the code, models, and results at: https://4kagent.github.io.
Frequency Domain-Based Diffusion Model for Unpaired Image Dehazing
Jul 02, 2025Unpaired image dehazing has attracted increasing attention due to its flexible data requirements during model training. Dominant methods based on contrastive learning not only introduce haze-unrelated content information, but also ignore haze-specific properties in the frequency domain (\ie,~haze-related degradation is mainly manifested in the amplitude spectrum). To address these issues, we propose a novel frequency domain-based diffusion model, named \ours, for fully exploiting the beneficial knowledge in unpaired clear data. In particular, inspired by the strong generative ability shown by Diffusion Models (DMs), we tackle the dehazing task from the perspective of frequency domain reconstruction and perform the DMs to yield the amplitude spectrum consistent with the distribution of clear images. To implement it, we propose an Amplitude Residual Encoder (ARE) to extract the amplitude residuals, which effectively compensates for the amplitude gap from the hazy to clear domains, as well as provide supervision for the DMs training. In addition, we propose a Phase Correction Module (PCM) to eliminate artifacts by further refining the phase spectrum during dehazing with a simple attention mechanism. Experimental results demonstrate that our \ours outperforms other state-of-the-art methods on both synthetic and real-world datasets.