 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMerino: Entropy-driven Design for Generative Language Models on IoT Devices
Feb 28, 2024Generative Large Language Models (LLMs) stand as a revolutionary advancement in the modern era of artificial intelligence (AI). However, directly deploying LLMs in resource-constrained hardware, such as Internet-of-Things (IoT) devices, is difficult due to their high computational cost. In this paper, we propose a novel information-entropy framework for designing mobile-friendly generative language models. Our key design paradigm is to maximize the entropy of transformer decoders within the given computational budgets. The whole design procedure involves solving a mathematical programming (MP) problem, which can be done on the CPU within minutes, making it nearly zero-cost. We evaluate our designed models, termed MeRino, across nine NLP downstream tasks, showing their competitive performance against the state-of-the-art autoregressive transformer models under the mobile setting. Notably, MeRino achieves similar or better zero performance compared to the 350M parameter OPT while being 4.9x faster on NVIDIA Jetson Nano with 5.5x reduction in model size. Code will be made available soon.
SHARE: Single-view Human Adversarial REconstruction
Dec 30, 2023The accuracy of 3D Human Pose and Shape reconstruction (HPS) from an image is progressively improving. Yet, no known method is robust across all image distortion. To address issues due to variations of camera poses, we introduce SHARE, a novel fine-tuning method that utilizes adversarial data augmentation to enhance the robustness of existing HPS techniques. We perform a comprehensive analysis on the impact of camera poses on HPS reconstruction outcomes. We first generated large-scale image datasets captured systematically from diverse camera perspectives. We then established a mapping between camera poses and reconstruction errors as a continuous function that characterizes the relationship between camera poses and HPS quality. Leveraging this representation, we introduce RoME (Regions of Maximal Error), a novel sampling technique for our adversarial fine-tuning method. The SHARE framework is generalizable across various single-view HPS methods and we demonstrate its performance on HMR, SPIN, PARE, CLIFF and ExPose. Our results illustrate a reduction in mean joint errors across single-view HPS techniques, for images captured from multiple camera positions without compromising their baseline performance. In many challenging cases, our method surpasses the performance of existing models, highlighting its practical significance for diverse real-world applications.
VLAP: Efficient Video-Language Alignment via Frame Prompting and Distilling for Video Question Answering
Dec 13, 2023In this work, we propose an efficient Video-Language Alignment via Frame-Prompting and Distilling (VLAP) network. Our VLAP model addresses both efficient frame sampling and effective cross-modal alignment in a unified way. In our VLAP network, we design a new learnable question-aware Frame-Prompter together with a new cross-modal distillation (QFormer-Distiller) module. Pre-trained large image-language models have shown promising results on problems such as visual question answering. However, how to efficiently and effectively sample image frames when adapting pre-trained large image-language model to video-language alignment is still the major challenge. Compared with prior work, our VLAP model demonstrates the capability of selecting key frames with critical contents, thus improving the video-language alignment accuracy while reducing the inference latency (+3.3% on NExT-QA Temporal with 3.0X speed up). Overall, our VLAP network outperforms (e.g. +4.6% on STAR Interaction and +2.2% on STAR average with 3.0X speed up, ours 2-frames out-perform SeViLA 4-frames on VLEP with 4.2X speed up) the state-of-the-art methods on the video question-answering benchmarks.
Agile-Quant: Activation-Guided Quantization for Faster Inference of LLMs on the Edge
Dec 09, 2023



Large Language Models (LLMs) stand out for their impressive performance in intricate language modeling tasks. However, their demanding computational and memory needs pose obstacles for broad use on edge devices. Quantization is then introduced to boost LLMs' on-device efficiency. Recent works show that 8-bit or lower weight quantization is feasible with minimal impact on end-to-end task performance, while the activation is still not quantized. On the other hand, mainstream commodity edge devices still struggle to execute these sub-8-bit quantized networks effectively. In this paper, we propose Agile-Quant, an activation-guided quantization framework for popular Large Language Models (LLMs), and implement an end-to-end accelerator on multiple edge devices for faster inference. Considering the hardware profiling and activation analysis, we first introduce a basic activation quantization strategy to balance the trade-off of task performance and real inference speed. Then we leverage the activation-aware token pruning technique to reduce the outliers and the adverse impact on attentivity. Ultimately, we utilize the SIMD-based 4-bit multiplier and our efficient TRIP matrix multiplication to implement the accelerator for LLMs on the edge. We apply our framework on different scales of LLMs including LLaMA, OPT, and BLOOM with 4-bit or 8-bit for the activation and 4-bit for the weight quantization. Experiments show that Agile-Quant achieves simultaneous quantization of model weights and activations while maintaining task performance comparable to existing weight-only quantization methods. Moreover, in the 8- and 4-bit scenario, Agile-Quant achieves an on-device speedup of up to 2.55x compared to its FP16 counterparts across multiple edge devices, marking a pioneering advancement in this domain.
HandyPriors: Physically Consistent Perception of Hand-Object Interactions with Differentiable Priors
Dec 03, 2023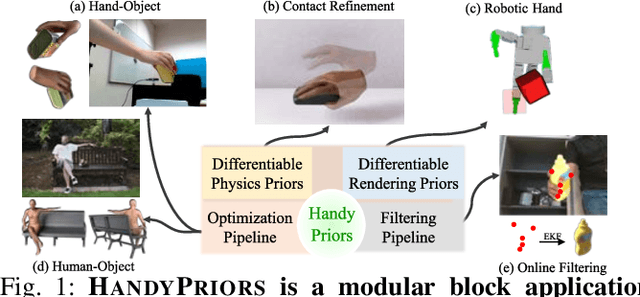
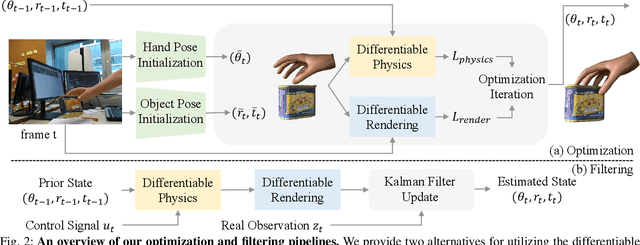
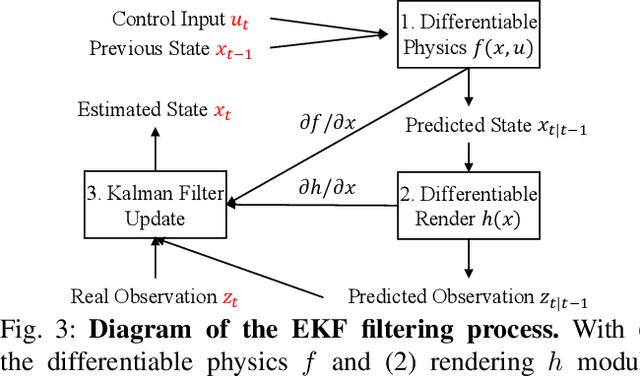

Various heuristic objectives for modeling hand-object interaction have been proposed in past work. However, due to the lack of a cohesive framework, these objectives often possess a narrow scope of applicability and are limited by their efficiency or accuracy. In this paper, we propose HandyPriors, a unified and general pipeline for pose estimation in human-object interaction scenes by leveraging recent advances in differentiable physics and rendering. Our approach employs rendering priors to align with input images and segmentation masks along with physics priors to mitigate penetration and relative-sliding across frames. Furthermore, we present two alternatives for hand and object pose estimation. The optimization-based pose estimation achieves higher accuracy, while the filtering-based tracking, which utilizes the differentiable priors as dynamics and observation models, executes faster. We demonstrate that HandyPriors attains comparable or superior results in the pose estimation task, and that the differentiable physics module can predict contact information for pose refinement. We also show that our approach generalizes to perception tasks, including robotic hand manipulation and human-object pose estimation in the wild.
AerialBooth: Mutual Information Guidance for Text Controlled Aerial View Synthesis from a Single Image
Nov 27, 2023



We present a novel method, AerialBooth, for synthesizing the aerial view from a single input image using its text description. We leverage the pretrained text-to-2D image stable diffusion model as prior knowledge of the 3D world. The model is finetuned in two steps to optimize for the text embedding and the UNet that reconstruct the input image and its inverse perspective mapping respectively. The inverse perspective mapping creates variance within the text-image space of the diffusion model, while providing weak guidance for aerial view synthesis. At inference, we steer the contents of the generated image towards the input image using novel mutual information guidance that maximizes the information content between the probability distributions of the two images. We evaluate our approach on a wide spectrum of real and synthetic data, including natural scenes, indoor scenes, human action, etc. Through extensive experiments and ablation studies, we demonstrate the effectiveness of AerialBooth and also its generalizability to other text-controlled views. We also show that AerialBooth achieves the best viewpoint-fidelity trade-off though quantitative evaluation on 7 metrics analyzing viewpoint and fidelity w.r.t. input image. Code and data is available at https://github.com/divyakraman/AerialBooth2023.
ICAR: Image-based Complementary Auto Reasoning
Aug 17, 2023



Scene-aware Complementary Item Retrieval (CIR) is a challenging task which requires to generate a set of compatible items across domains. Due to the subjectivity, it is difficult to set up a rigorous standard for both data collection and learning objectives. To address this challenging task, we propose a visual compatibility concept, composed of similarity (resembling in color, geometry, texture, and etc.) and complementarity (different items like table vs chair completing a group). Based on this notion, we propose a compatibility learning framework, a category-aware Flexible Bidirectional Transformer (FBT), for visual "scene-based set compatibility reasoning" with the cross-domain visual similarity input and auto-regressive complementary item generation. We introduce a "Flexible Bidirectional Transformer (FBT)" consisting of an encoder with flexible masking, a category prediction arm, and an auto-regressive visual embedding prediction arm. And the inputs for FBT are cross-domain visual similarity invariant embeddings, making this framework quite generalizable. Furthermore, our proposed FBT model learns the inter-object compatibility from a large set of scene images in a self-supervised way. Compared with the SOTA methods, this approach achieves up to 5.3% and 9.6% in FITB score and 22.3% and 31.8% SFID improvement on fashion and furniture, respectively.
Zero-Shot Neural Architecture Search: Challenges, Solutions, and Opportunities
Jul 05, 2023Recently, zero-shot (or training-free) Neural Architecture Search (NAS) approaches have been proposed to liberate the NAS from training requirements. The key idea behind zero-shot NAS approaches is to design proxies that predict the accuracies of the given networks without training network parameters. The proxies proposed so far are usually inspired by recent progress in theoretical deep learning and have shown great potential on several NAS benchmark datasets. This paper aims to comprehensively review and compare the state-of-the-art (SOTA) zero-shot NAS approaches, with an emphasis on their hardware awareness. To this end, we first review the mainstream zero-shot proxies and discuss their theoretical underpinnings. We then compare these zero-shot proxies through large-scale experiments and demonstrate their effectiveness in both hardware-aware and hardware-oblivious NAS scenarios. Finally, we point out several promising ideas to design better proxies. Our source code and the related paper list are available on https://github.com/SLDGroup/survey-zero-shot-nas.
Making Vision Transformers Efficient from A Token Sparsification View
Mar 30, 2023



The quadratic computational complexity to the number of tokens limits the practical applications of Vision Transformers (ViTs). Several works propose to prune redundant tokens to achieve efficient ViTs. However, these methods generally suffer from (i) dramatic accuracy drops, (ii) application difficulty in the local vision transformer, and (iii) non-general-purpose networks for downstream tasks. In this work, we propose a novel Semantic Token ViT (STViT), for efficient global and local vision transformers, which can also be revised to serve as backbone for downstream tasks. The semantic tokens represent cluster centers, and they are initialized by pooling image tokens in space and recovered by attention, which can adaptively represent global or local semantic information. Due to the cluster properties, a few semantic tokens can attain the same effect as vast image tokens, for both global and local vision transformers. For instance, only 16 semantic tokens on DeiT-(Tiny,Small,Base) can achieve the same accuracy with more than 100% inference speed improvement and nearly 60% FLOPs reduction; on Swin-(Tiny,Small,Base), we can employ 16 semantic tokens in each window to further speed it up by around 20% with slight accuracy increase. Besides great success in image classification, we also extend our method to video recognition. In addition, we design a STViT-R(ecover) network to restore the detailed spatial information based on the STViT, making it work for downstream tasks, which is powerless for previous token sparsification methods. Experiments demonstrate that our method can achieve competitive results compared to the original networks in object detection and instance segmentation, with over 30% FLOPs reduction for backbone. Code is available at http://github.com/changsn/STViT-R
Aerial Diffusion: Text Guided Ground-to-Aerial View Translation from a Single Image using Diffusion Models
Mar 15, 2023



We present a novel method, Aerial Diffusion, for generating aerial views from a single ground-view image using text guidance. Aerial Diffusion leverages a pretrained text-image diffusion model for prior knowledge. We address two main challenges corresponding to domain gap between the ground-view and the aerial view and the two views being far apart in the text-image embedding manifold. Our approach uses a homography inspired by inverse perspective mapping prior to finetuning the pretrained diffusion model. Additionally, using the text corresponding to the ground-view to finetune the model helps us capture the details in the ground-view image at a relatively low bias towards the ground-view image. Aerial Diffusion uses an alternating sampling strategy to compute the optimal solution on complex high-dimensional manifold and generate a high-fidelity (w.r.t. ground view) aerial image. We demonstrate the quality and versatility of Aerial Diffusion on a plethora of images from various domains including nature, human actions, indoor scenes, etc. We qualitatively prove the effectiveness of our method with extensive ablations and comparisons. To the best of our knowledge, Aerial Diffusion is the first approach that performs ground-to-aerial translation in an unsupervised manner.