 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlVideo: Adding Conditional Control for One Shot Text-to-Video Editing
May 26, 2023



In this paper, we present ControlVideo, a novel method for text-driven video editing. Leveraging the capabilities of text-to-image diffusion models and ControlNet, ControlVideo aims to enhance the fidelity and temporal consistency of videos that align with a given text while preserving the structure of the source video. This is achieved by incorporating additional conditions such as edge maps, fine-tuning the key-frame and temporal attention on the source video-text pair with carefully designed strategies. An in-depth exploration of ControlVideo's design is conducted to inform future research on one-shot tuning video diffusion models. Quantitatively, ControlVideo outperforms a range of competitive baselines in terms of faithfulness and consistency while still aligning with the textual prompt. Additionally, it delivers videos with high visual realism and fidelity w.r.t. the source content, demonstrating flexibility in utilizing controls containing varying degrees of source video information, and the potential for multiple control combinations. The project page is available at \href{https://ml.cs.tsinghua.edu.cn/controlvideo/}{https://ml.cs.tsinghua.edu.cn/controlvideo/}.
Equivariant Energy-Guided SDE for Inverse Molecular Design
Sep 30, 2022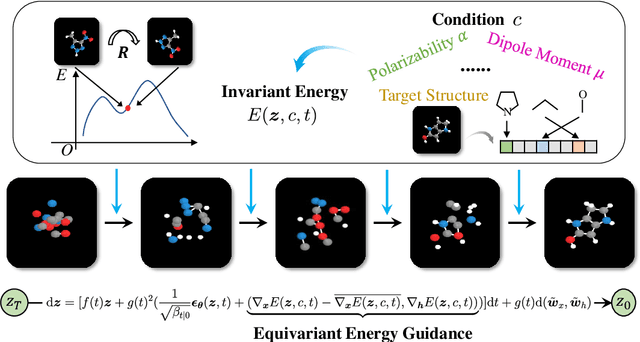
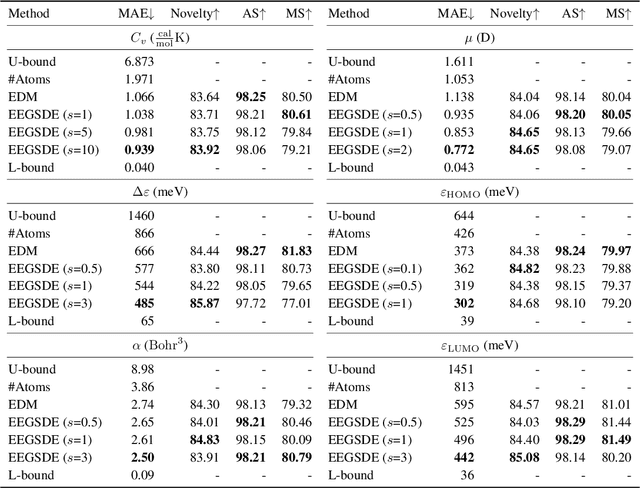
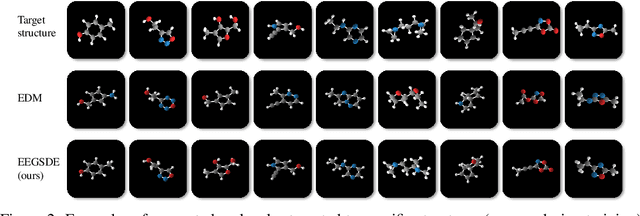
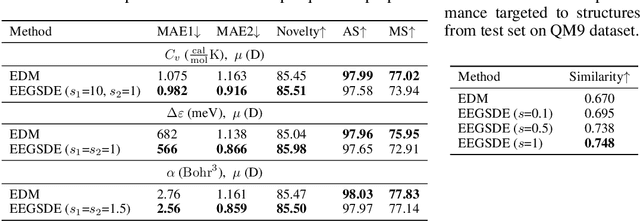
Inverse molecular design is critical in material science and drug discovery, where the generated molecules should satisfy certain desirable properties. In this paper, we propose equivariant energy-guided stochastic differential equations (EEGSDE), a flexible framework for controllable 3D molecule generation under the guidance of an energy function in diffusion models. Formally, we show that EEGSDE naturally exploits the geometric symmetry in 3D molecular conformation, as long as the energy function is invariant to orthogonal transformations. Empirically, under the guidance of designed energy functions, EEGSDE significantly improves the baseline on QM9, in inverse molecular design targeted to quantum properties and molecular structures. Furthermore, EEGSDE is able to generate molecules with multiple target properties by combining the corresponding energy functions linearly.
Automatic reorientation by deep learning to generate short axis SPECT myocardial perfusion images
Aug 07, 2022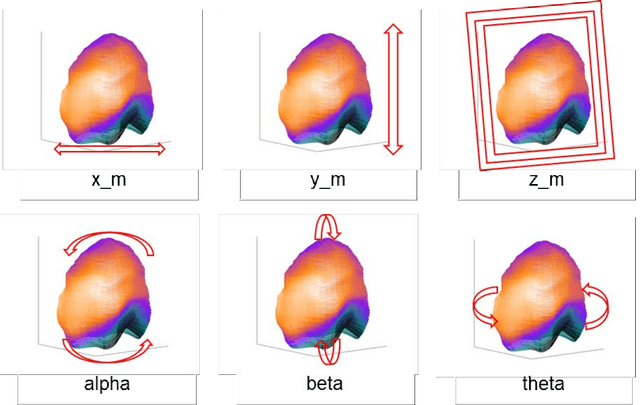
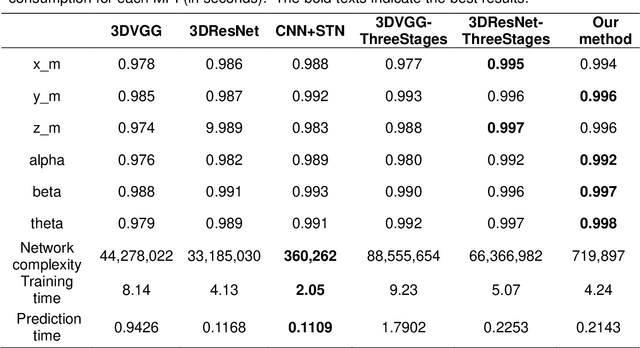
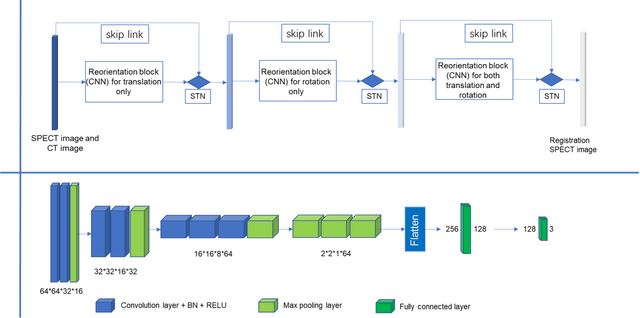
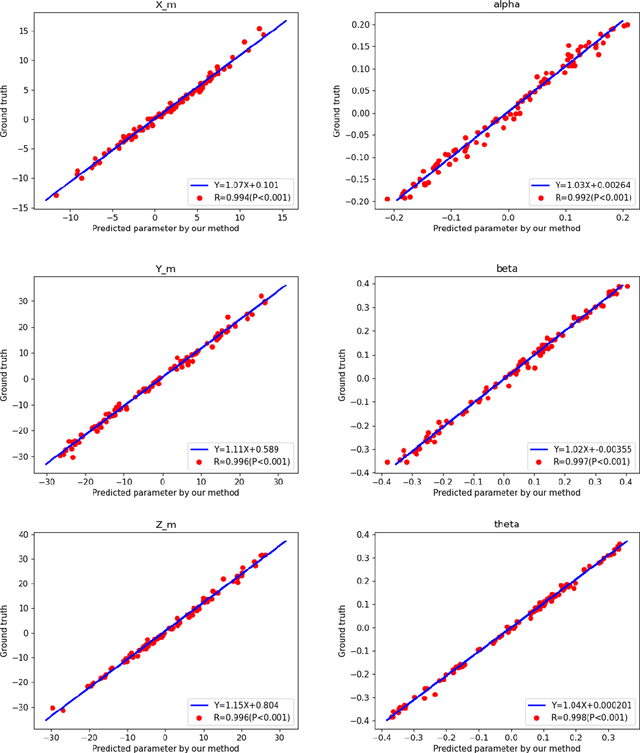
Single photon emission computed tomography (SPECT) myocardial perfusion images (MPI) can be displayed both in traditional short-axis (SA) cardiac planes and polar maps for interpretation and quantification. It is essential to reorient the reconstructed transaxial SPECT MPI into standard SA slices. This study is aimed to develop a deep-learning-based approach for automatic reorientation of MPI. Methods: A total of 254 patients were enrolled, including 228 stress SPECT MPIs and 248 rest SPECT MPIs. Five-fold cross-validation with 180 stress and 201 rest MPIs was used for training and internal validation; the remaining images were used for testing. The rigid transformation parameters (translation and rotation) from manual reorientation were annotated by an experienced operator and used as the ground truth. A convolutional neural network (CNN) was designed to predict the transformation parameters. Then, the derived transform was applied to the grid generator and sampler in spatial transformer network (STN) to generate the reoriented image. A loss function containing mean absolute errors for translation and mean square errors for rotation was employed. A three-stage optimization strategy was adopted for model optimization: 1) optimize the translation parameters while fixing the rotation parameters; 2) optimize rotation parameters while fixing the translation parameters; 3) optimize both translation and rotation parameters together.
EGSDE: Unpaired Image-to-Image Translation via Energy-Guided Stochastic Differential Equations
Jul 14, 2022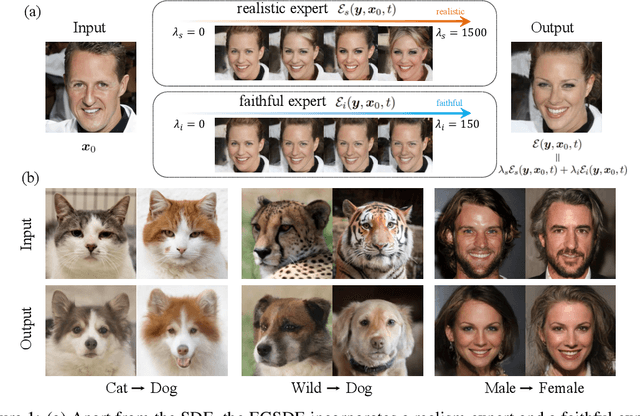
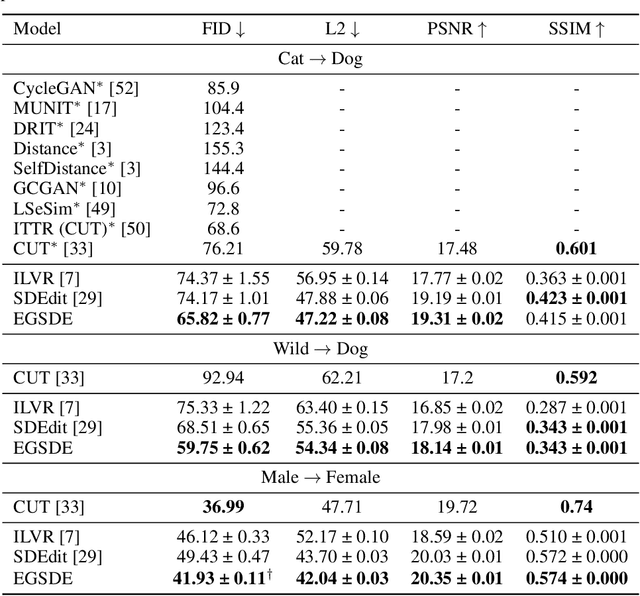
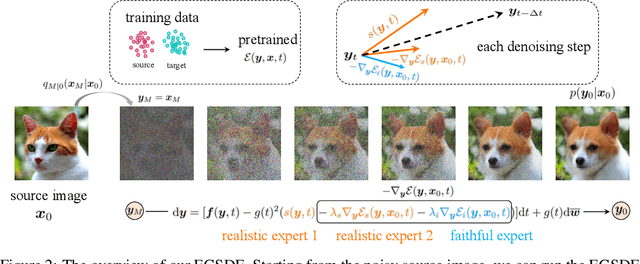

Score-based diffusion generative models (SDGMs) have achieved the SOTA FID results in unpaired image-to-image translation (I2I). However, we notice that existing methods totally ignore the training data in the source domain, leading to sub-optimal solutions for unpaired I2I. To this end, we propose energy-guided stochastic differential equations (EGSDE) that employs an energy function pretrained on both the source and target domains to guide the inference process of a pretrained SDE for realistic and faithful unpaired I2I. Building upon two feature extractors, we carefully design the energy function such that it encourages the transferred image to preserve the domain-independent features and discard domainspecific ones. Further, we provide an alternative explanation of the EGSDE as a product of experts, where each of the three experts (corresponding to the SDE and two feature extractors) solely contributes to faithfulness or realism. Empirically, we compare EGSDE to a large family of baselines on three widely-adopted unpaired I2I tasks under four metrics. EGSDE not only consistently outperforms existing SDGMs-based methods in almost all settings but also achieves the SOTA realism results (e.g., FID of 65.82 in Cat to Dog and FID of 59.75 in Wild to Dog on AFHQ) without harming the faithful performance.
Integration of Physics-Based and Data-Driven Models for Hyperspectral Image Unmixing
Jun 11, 2022
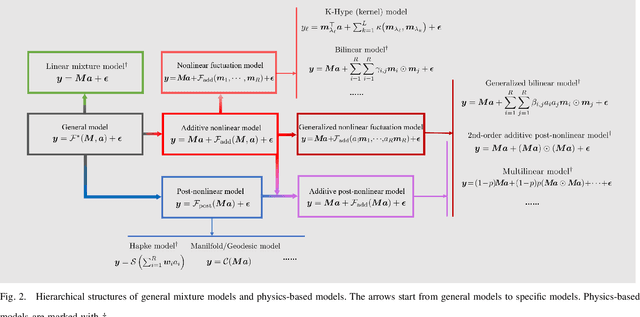
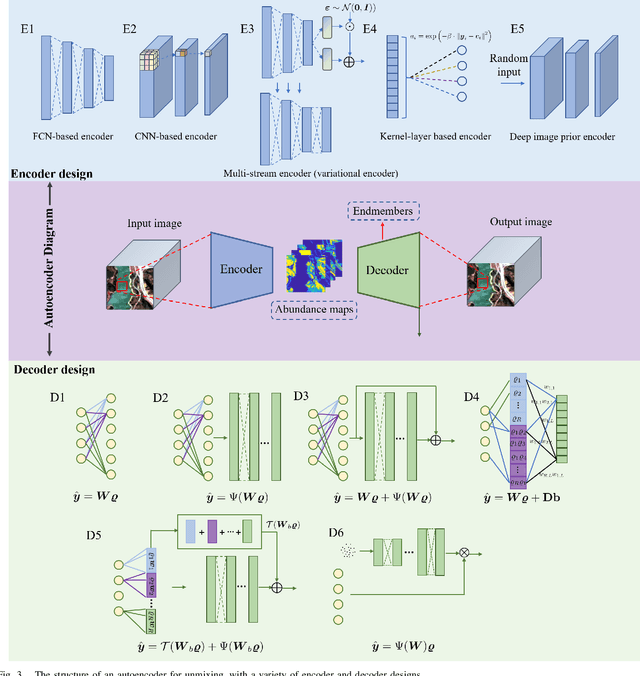

Spectral unmixing is one of the most important quantitative analysis tasks in hyperspectral data processing. Conventional physics-based models are characterized by clear interpretation. However, due to the complex mixture mechanism and limited nonlinearity modeling capacity, these models may not be accurate, especially, in analyzing scenes with unknown physical characteristics. Data-driven methods have developed rapidly in recent years, in particular deep learning methods as they possess superior capability in modeling complex and nonlinear systems. Simply transferring these methods as black-boxes to conduct unmixing may lead to low physical interpretability and generalization ability. Consequently, several contributions have been dedicated to integrating advantages of both physics-based models and data-driven methods. In this article, we present an overview of recent advances on this topic from several aspects, including deep neural network (DNN) structures design, prior capturing and loss design, and summarise these methods in a common mathematical optimization framework. In addition, relevant remarks and discussions are conducted made for providing further understanding and prospective improvement of the methods. The related source codes and data are collected and made available at http://github.com/xiuheng-wang/awesome-hyperspectral-image-unmixing.
A General Framework for Lifelong Localization and Mapping in Changing Environment
Nov 22, 2021
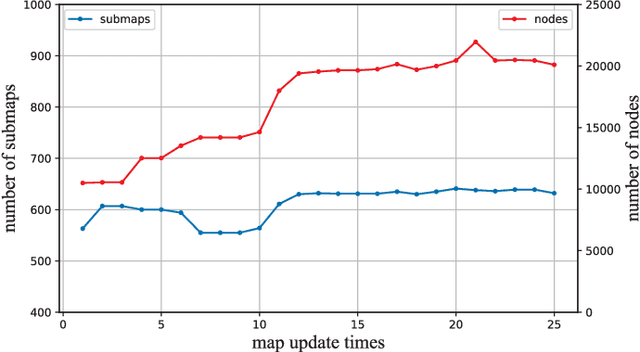
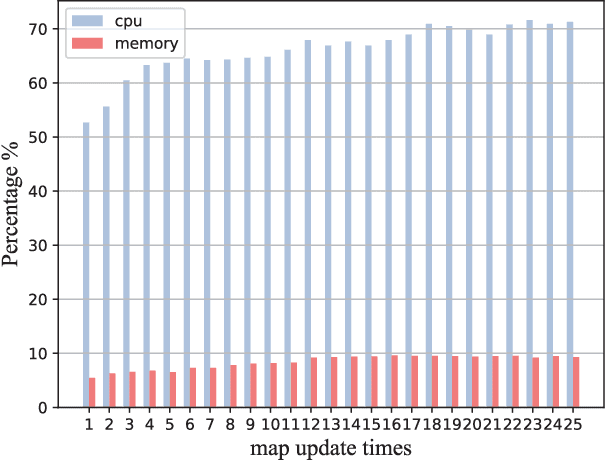
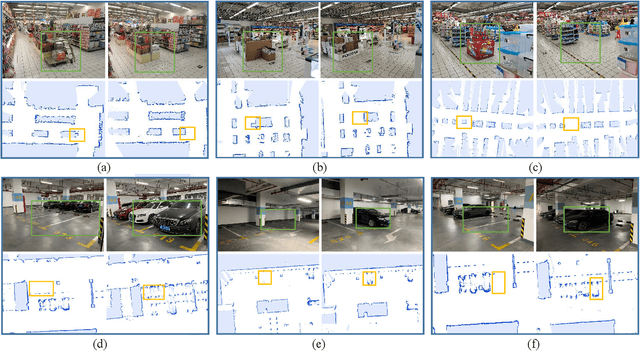
The environment of most real-world scenarios such as malls and supermarkets changes at all times. A pre-built map that does not account for these changes becomes out-of-date easily. Therefore, it is necessary to have an up-to-date model of the environment to facilitate long-term operation of a robot. To this end, this paper presents a general lifelong simultaneous localization and mapping (SLAM) framework. Our framework uses a multiple session map representation, and exploits an efficient map updating strategy that includes map building, pose graph refinement and sparsification. To mitigate the unbounded increase of memory usage, we propose a map-trimming method based on the Chow-Liu maximum-mutual-information spanning tree. The proposed SLAM framework has been comprehensively validated by over a month of robot deployment in real supermarket environment. Furthermore, we release the dataset collected from the indoor and outdoor changing environment with the hope to accelerate lifelong SLAM research in the community. Our dataset is available at https://github.com/sanduan168/lifelong-SLAM-dataset.
AB-Mapper: Attention and BicNet Based Multi-agent Path Finding for Dynamic Crowded Environment
Oct 02, 2021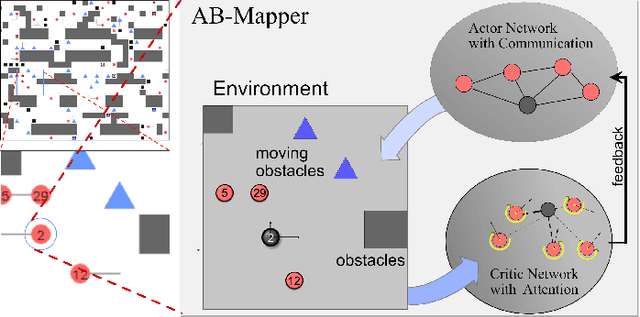
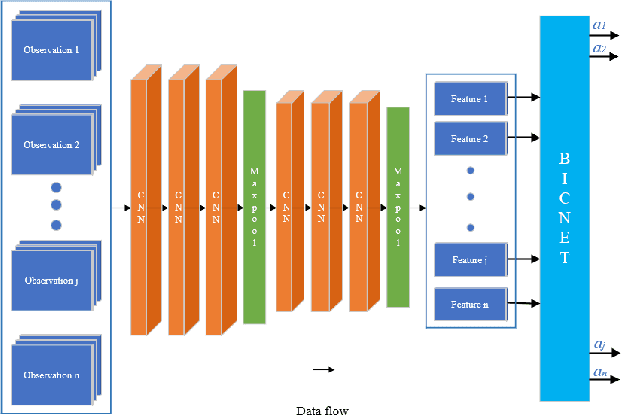
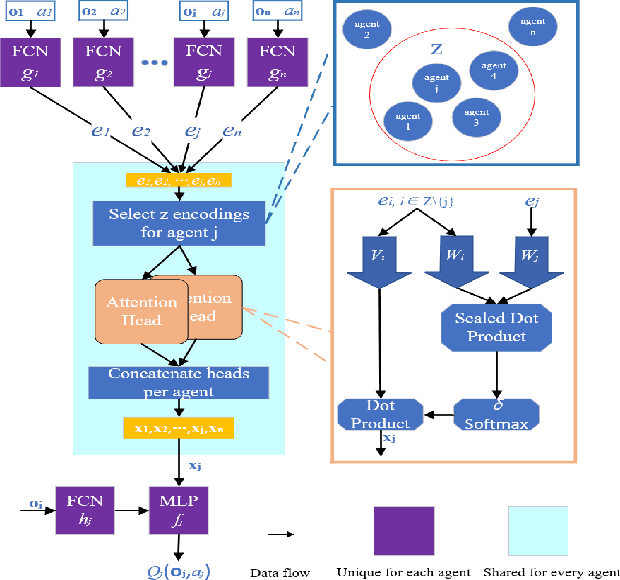
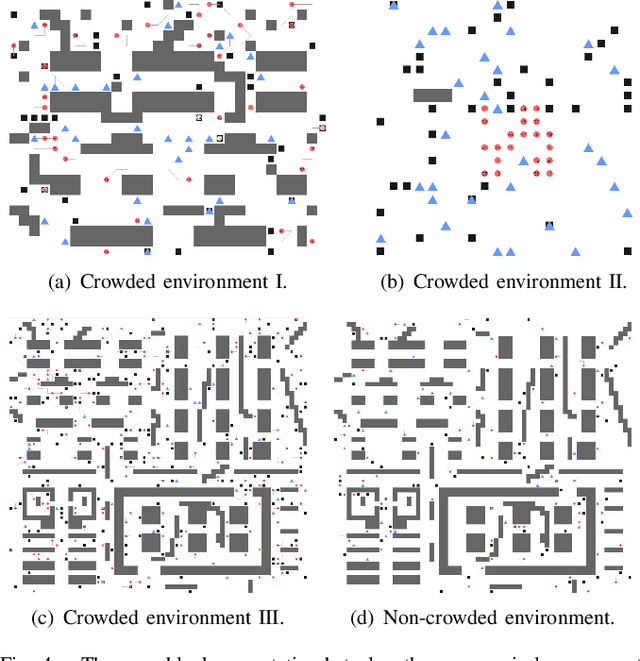
Multi-agent path finding in dynamic crowded environments is of great academic and practical value for multi-robot systems in the real world. To improve the effectiveness and efficiency of communication and learning process during path planning in dynamic crowded environments, we introduce an algorithm called Attention and BicNet based Multi-agent path planning with effective reinforcement (AB-Mapper)under the actor-critic reinforcement learning framework. In this framework, on the one hand, we utilize the BicNet with communication function in the actor-network to achieve intra team coordination. On the other hand, we propose a centralized critic network that can selectively allocate attention weights to surrounding agents. This attention mechanism allows an individual agent to automatically learn a better evaluation of actions by also considering the behaviours of its surrounding agents. Compared with the state-of-the-art method Mapper,our AB-Mapper is more effective (85.86% vs. 81.56% in terms of success rate) in solving the general path finding problems with dynamic obstacles. In addition, in crowded scenarios, our method outperforms the Mapper method by a large margin,reaching a stunning gap of more than 40% for each experiment.
A Concept Knowledge-Driven Keywords Retrieval Framework for Sponsored Search
Feb 21, 2021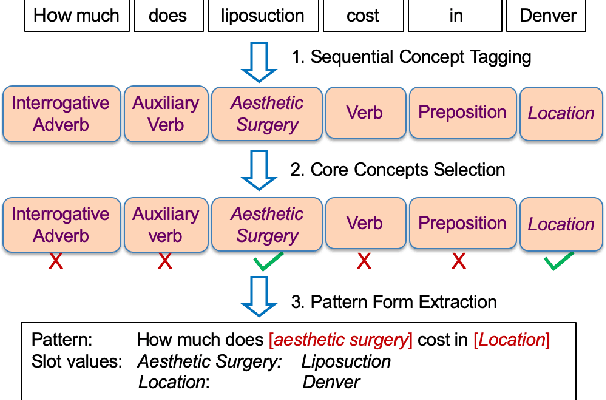

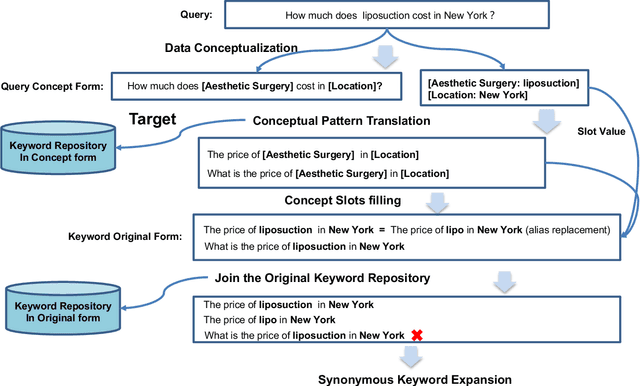
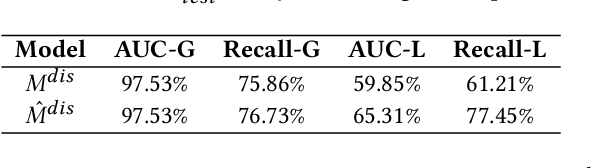
In sponsored search, retrieving synonymous keywords for exact match type is important for accurately targeted advertising. Data-driven deep learning-based method has been proposed to tackle this problem. An apparent disadvantage of this method is its poor generalization performance on entity-level long-tail instances, even though they might share similar concept-level patterns with frequent instances. With the help of a large knowledge base, we find that most commercial synonymous query-keyword pairs can be abstracted into meaningful conceptual patterns through concept tagging. Based on this fact, we propose a novel knowledge-driven conceptual retrieval framework to mitigate this problem, which consists of three parts: data conceptualization, matching via conceptual patterns and concept-augmented discrimination. Both offline and online experiments show that our method is very effective. This framework has been successfully applied to Baidu's sponsored search system, which yields a significant improvement in revenue.
Proactive Interaction Framework for Intelligent Social Receptionist Robots
Dec 09, 2020
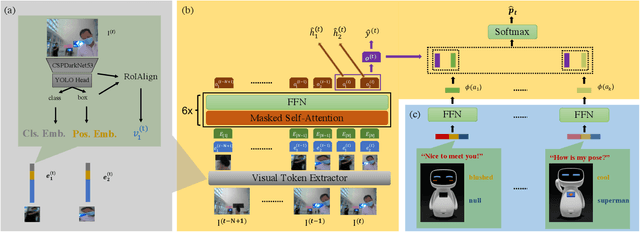

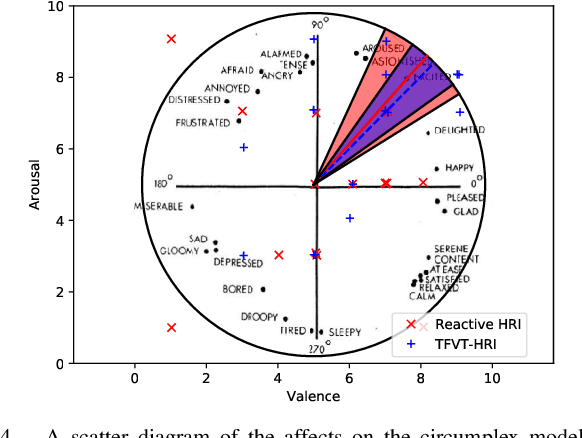
Proactive human-robot interaction (HRI) allows the receptionist robots to actively greet people and offer services based on vision, which has been found to improve acceptability and customer satisfaction. Existing approaches are either based on multi-stage decision processes or based on end-to-end decision models. However, the rule-based approaches require sedulous expert efforts and only handle minimal pre-defined scenarios. On the other hand, existing works with end-to-end models are limited to very general greetings or few behavior patterns (typically less than 10). To address those challenges, we propose a new end-to-end framework, the TransFormer with Visual Tokens for Human-Robot Interaction (TFVT-HRI). The proposed framework extracts visual tokens of relative objects from an RGB camera first. To ensure the correct interpretation of the scenario, a transformer decision model is then employed to process the visual tokens, which is augmented with the temporal and spatial information. It predicts the appropriate action to take in each scenario and identifies the right target. Our data is collected from an in-service receptionist robot in an office building, which is then annotated by experts for appropriate proactive behavior. The action set includes 1000+ diverse patterns by combining language, emoji expression, and body motions. We compare our model with other SOTA end-to-end models on both offline test sets and online user experiments in realistic office building environments to validate this framework. It is demonstrated that the decision model achieves SOTA performance in action triggering and selection, resulting in more humanness and intelligence when compared with the previous reactive reception policies.
Hyperspectral Unmixing via Nonnegative Matrix Factorization with Handcrafted and Learnt Priors
Oct 09, 2020
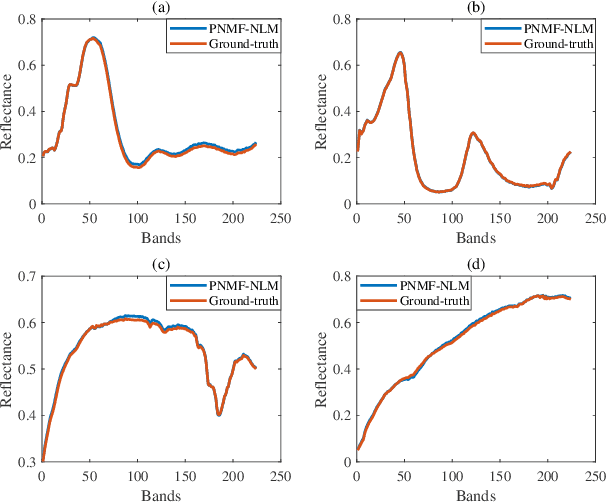
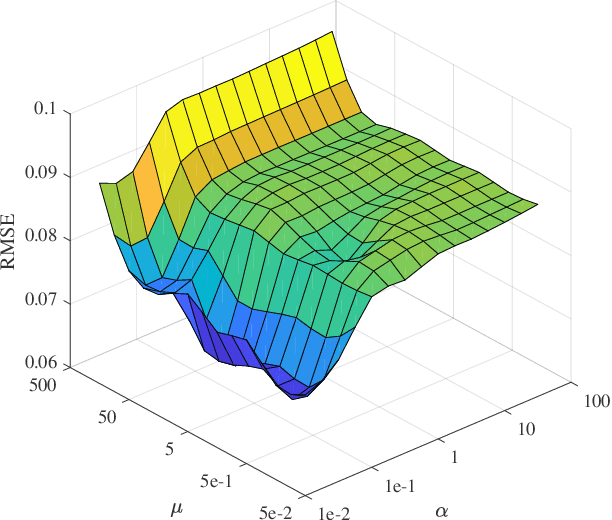
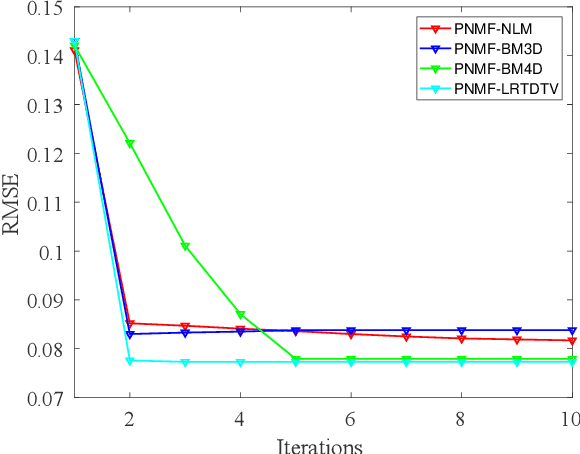
Nowadays, nonnegative matrix factorization (NMF) based methods have been widely applied to blind spectral unmixing. Introducing proper regularizers to NMF is crucial for mathematically constraining the solutions and physically exploiting spectral and spatial properties of images. Generally, properly handcrafting regularizers and solving the associated complex optimization problem are non-trivial tasks. In our work, we propose an NMF based unmixing framework which jointly uses a handcrafting regularizer and a learnt regularizer from data. we plug learnt priors of abundances where the associated subproblem can be addressed using various image denoisers, and we consider an l_2,1-norm regularizer to the abundance matrix to promote sparse unmixing results. The proposed framework is flexible and extendable. Both synthetic data and real airborne data are conducted to confirm the effectiveness of our method.