 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBitDecoding: Unlocking Tensor Cores for Long-Context LLMs Decoding with Low-Bit KV Cache
Mar 24, 2025



The growing adoption of long-context Large Language Models (LLMs) has introduced significant memory and computational challenges in autoregressive decoding due to the expanding Key-Value (KV) cache. KV cache quantization has emerged as a promising solution, with prior work showing that 4-bit or even 2-bit quantization can maintain model accuracy while reducing memory costs. However, despite these benefits, preliminary implementations for the low-bit KV cache struggle to deliver the expected speedup due to quantization and dequantization overheads and the lack of Tensor Cores utilization. In this work, we propose BitDecoding, a GPU-optimized framework that unlocks Tensor Cores for efficient decoding with low-bit KV cache. Efficiently leveraging Tensor Cores for low-bit KV cache is challenging due to the dynamic nature of KV cache generation at each decoding step. BitDecoding addresses these challenges with a Tensor Cores-Centric BitFusion Scheme that ensures data layout compatibility to enable high utilization of Tensor Cores. Additionally, BitDecoding incorporates a warp-efficient parallel decoding kernel and a fine-grained asynchronous pipeline, minimizing dequantization overhead and improving computational efficiency. Experiments show that BitDecoding achieves up to 7.5x speedup on RTX 4090, 4.8x on A100, and 8.9x on H100, compared to FP16 FlashDecoding-v2. It also outperforms the state-of-the-art low-bit KV cache implementation (QServe) by up to 4.3x. On LLaMA-3.1-8B with a 128K sequence length, BitDecoding reduces single-batch decoding latency by 3x, demonstrating its effectiveness in long-context generation scenarios. The code is available at https://github.com/DD-DuDa/BitDecoding.
Refining Salience-Aware Sparse Fine-Tuning Strategies for Language Models
Dec 18, 2024



Parameter-Efficient Fine-Tuning (PEFT) has gained prominence through low-rank adaptation methods like LoRA. In this paper, we focus on sparsity-based PEFT (SPEFT), which introduces trainable sparse adaptations to the weight matrices in the model, offering greater flexibility in selecting fine-tuned parameters compared to low-rank methods. We conduct the first systematic evaluation of salience metrics for SPEFT, inspired by zero-cost NAS proxies, and identify simple gradient-based metrics is reliable, and results are on par with the best alternatives, offering both computational efficiency and robust performance. Additionally, we compare static and dynamic masking strategies, finding that static masking, which predetermines non-zero entries before training, delivers efficiency without sacrificing performance, while dynamic masking offers no substantial benefits. Across NLP tasks, a simple gradient-based, static SPEFT consistently outperforms other fine-tuning methods for LLMs, providing a simple yet effective baseline for SPEFT. Our work challenges the notion that complexity is necessary for effective PEFT. Our work is open source and available to the community at [https://github.com/0-ml/speft].
Scaling Laws for Mixed quantization in Large Language Models
Oct 09, 2024



Post-training quantization of Large Language Models (LLMs) has proven effective in reducing the computational requirements for running inference on these models. In this study, we focus on a straightforward question: When aiming for a specific accuracy or perplexity target for low-precision quantization, how many high-precision numbers or calculations are required to preserve as we scale LLMs to larger sizes? We first introduce a critical metric named the quantization ratio, which compares the number of parameters quantized to low-precision arithmetic against the total parameter count. Through extensive and carefully controlled experiments across different model families, arithmetic types, and quantization granularities (e.g. layer-wise, matmul-wise), we identify two central phenomenons. 1) The larger the models, the better they can preserve performance with an increased quantization ratio, as measured by perplexity in pre-training tasks or accuracy in downstream tasks. 2) The finer the granularity of mixed-precision quantization (e.g., matmul-wise), the more the model can increase the quantization ratio. We believe these observed phenomena offer valuable insights for future AI hardware design and the development of advanced Efficient AI algorithms.
HASS: Hardware-Aware Sparsity Search for Dataflow DNN Accelerator
Jun 05, 2024



Deep Neural Networks (DNNs) excel in learning hierarchical representations from raw data, such as images, audio, and text. To compute these DNN models with high performance and energy efficiency, these models are usually deployed onto customized hardware accelerators. Among various accelerator designs, dataflow architecture has shown promising performance due to its layer-pipelined structure and its scalability in data parallelism. Exploiting weights and activations sparsity can further enhance memory storage and computation efficiency. However, existing approaches focus on exploiting sparsity in non-dataflow accelerators, which cannot be applied onto dataflow accelerators because of the large hardware design space introduced. As such, this could miss opportunities to find an optimal combination of sparsity features and hardware designs. In this paper, we propose a novel approach to exploit unstructured weights and activations sparsity for dataflow accelerators, using software and hardware co-optimization. We propose a Hardware-Aware Sparsity Search (HASS) to systematically determine an efficient sparsity solution for dataflow accelerators. Over a set of models, we achieve an efficiency improvement ranging from 1.3$\times$ to 4.2$\times$ compared to existing sparse designs, which are either non-dataflow or non-hardware-aware. Particularly, the throughput of MobileNetV3 can be optimized to 4895 images per second. HASS is open-source: \url{https://github.com/Yu-Zhewen/HASS}
LQER: Low-Rank Quantization Error Reconstruction for LLMs
Feb 04, 2024Post-training quantization of Large Language Models (LLMs) is challenging. In this work, we introduce Low-rank Quantization Error Reduction (LQER), which combines quantization and low-rank approximation to recover the model capability. LQER leverages an activation-induced scale matrix to drive the singular value distribution of quantization error towards a desirable distribution, which enables nearly-lossless W4A8 quantization on various LLMs and downstream tasks without the need for knowledge distillation, grid search, or gradient-base iterative optimization. Unlike existing methods, the computation pattern of LQER eliminates the need for specialized Scatter and Gather processes to collect high-precision weights from irregular memory locations. Our W4A8 LLMs achieve near-lossless performance on six popular downstream tasks, while using 1.36$\times$ fewer hardware resources than the leading state-of-the-art method. We will open-source our framework once the paper is accepted.
Revisiting Block-based Quantisation: What is Important for Sub-8-bit LLM Inference?
Oct 21, 2023



The inference of Large language models (LLMs) requires immense computation and memory resources. To curtail these costs, quantisation has merged as a promising solution, but existing LLM quantisation mainly focuses on 8-bit. In this work, we explore the statistical and learning properties of the LLM layer and attribute the bottleneck of LLM quantisation to numerical scaling offsets. To address this, we adapt block quantisations for LLMs, a family of methods that share scaling factors across packed numbers. Block quantisations efficiently reduce the numerical scaling offsets solely from an arithmetic perspective, without additional treatments in the computational path. Our nearly-lossless quantised 6-bit LLMs achieve a $19\times$ higher arithmetic density and $5\times$ memory density than the float32 baseline, surpassing the prior art 8-bit quantisation by $2.5\times$ in arithmetic density and $1.2\times$ in memory density, without requiring any data calibration or re-training. We also share our insights into sub-8-bit LLM quantisation, including the mismatch between activation and weight distributions, optimal fine-tuning strategies, and a lower quantisation granularity inherent in the statistical properties of LLMs. The latter two tricks enable nearly-lossless 4-bit LLMs on downstream tasks. Our code is open-sourced.
SEER: Super-Optimization Explorer for HLS using E-graph Rewriting with MLIR
Aug 15, 2023High-level synthesis (HLS) is a process that automatically translates a software program in a high-level language into a low-level hardware description. However, the hardware designs produced by HLS tools still suffer from a significant performance gap compared to manual implementations. This is because the input HLS programs must still be written using hardware design principles. Existing techniques either leave the program source unchanged or perform a fixed sequence of source transformation passes, potentially missing opportunities to find the optimal design. We propose a super-optimization approach for HLS that automatically rewrites an arbitrary software program into efficient HLS code that can be used to generate an optimized hardware design. We developed a toolflow named SEER, based on the e-graph data structure, to efficiently explore equivalent implementations of a program at scale. SEER provides an extensible framework, orchestrating existing software compiler passes and hardware synthesis optimizers. Our work is the first attempt to exploit e-graph rewriting for large software compiler frameworks, such as MLIR. Across a set of open-source benchmarks, we show that SEER achieves up to 38x the performance within 1.4x the area of the original program. Via an Intel-provided case study, SEER demonstrates the potential to outperform manually optimized designs produced by hardware experts.
A Concept Knowledge-Driven Keywords Retrieval Framework for Sponsored Search
Feb 21, 2021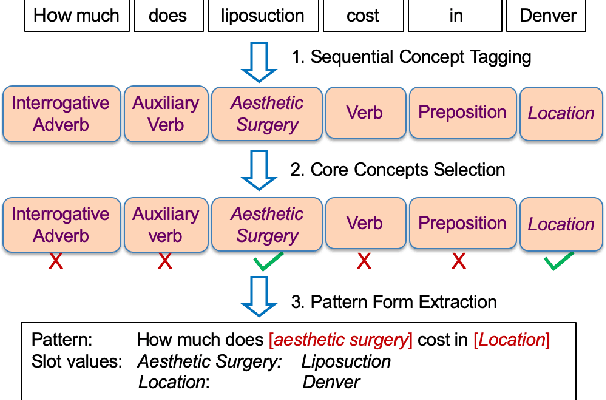

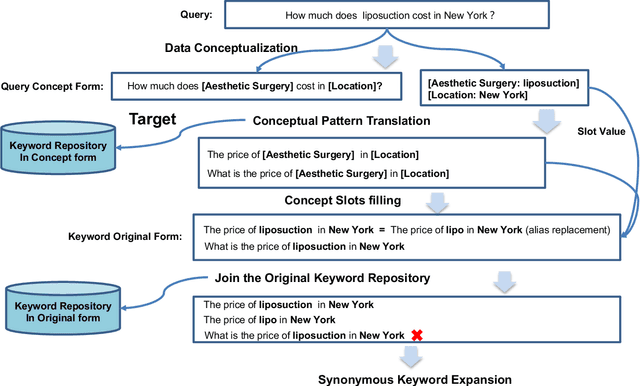
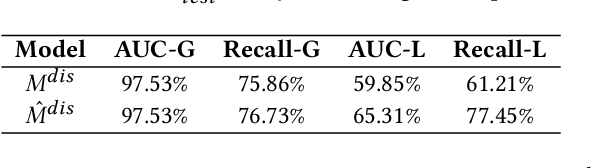
In sponsored search, retrieving synonymous keywords for exact match type is important for accurately targeted advertising. Data-driven deep learning-based method has been proposed to tackle this problem. An apparent disadvantage of this method is its poor generalization performance on entity-level long-tail instances, even though they might share similar concept-level patterns with frequent instances. With the help of a large knowledge base, we find that most commercial synonymous query-keyword pairs can be abstracted into meaningful conceptual patterns through concept tagging. Based on this fact, we propose a novel knowledge-driven conceptual retrieval framework to mitigate this problem, which consists of three parts: data conceptualization, matching via conceptual patterns and concept-augmented discrimination. Both offline and online experiments show that our method is very effective. This framework has been successfully applied to Baidu's sponsored search system, which yields a significant improvement in revenue.
Building a comprehensive syntactic and semantic corpus of Chinese clinical texts
Nov 08, 2016
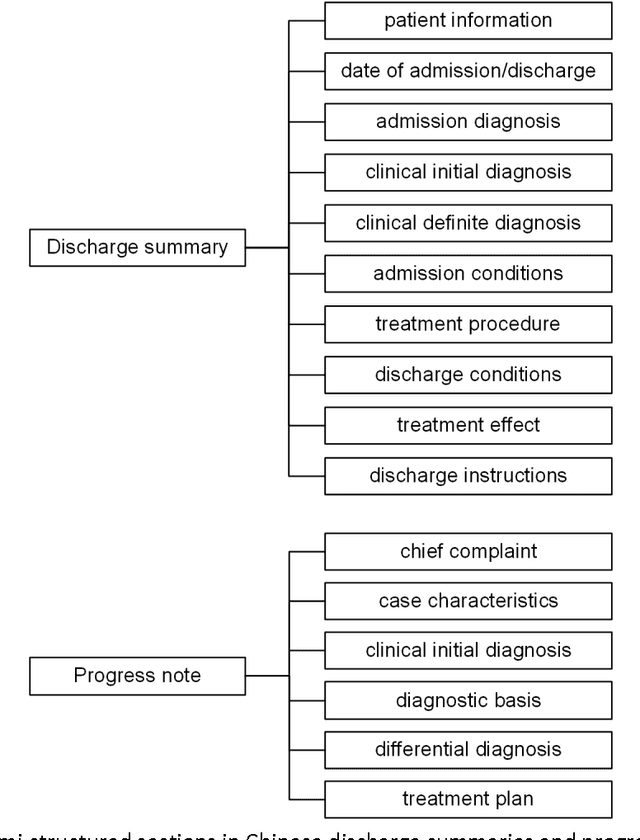
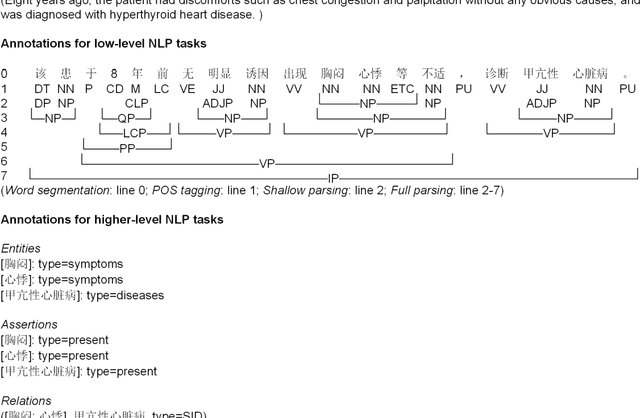
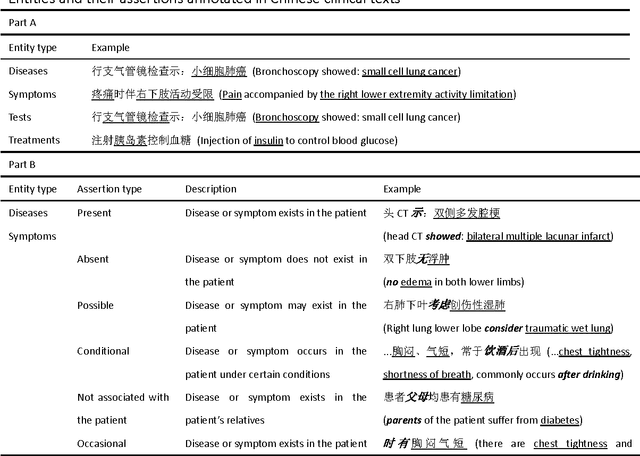
Objective: To build a comprehensive corpus covering syntactic and semantic annotations of Chinese clinical texts with corresponding annotation guidelines and methods as well as to develop tools trained on the annotated corpus, which supplies baselines for research on Chinese texts in the clinical domain. Materials and methods: An iterative annotation method was proposed to train annotators and to develop annotation guidelines. Then, by using annotation quality assurance measures, a comprehensive corpus was built, containing annotations of part-of-speech (POS) tags, syntactic tags, entities, assertions, and relations. Inter-annotator agreement (IAA) was calculated to evaluate the annotation quality and a Chinese clinical text processing and information extraction system (CCTPIES) was developed based on our annotated corpus. Results: The syntactic corpus consists of 138 Chinese clinical documents with 47,424 tokens and 2553 full parsing trees, while the semantic corpus includes 992 documents that annotated 39,511 entities with their assertions and 7695 relations. IAA evaluation shows that this comprehensive corpus is of good quality, and the system modules are effective. Discussion: The annotated corpus makes a considerable contribution to natural language processing (NLP) research into Chinese texts in the clinical domain. However, this corpus has a number of limitations. Some additional types of clinical text should be introduced to improve corpus coverage and active learning methods should be utilized to promote annotation efficiency. Conclusions: In this study, several annotation guidelines and an annotation method for Chinese clinical texts were proposed, and a comprehensive corpus with its NLP modules were constructed, providing a foundation for further study of applying NLP techniques to Chinese texts in the clinical domain.