 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo Place to Hide: Benchmarking Video Hallucination with Background-Controlled Pairs
Jun 30, 2026We introduce VidPair-Halluc, a new benchmark for evaluating video hallucination in large video models (LVMs) under rigorous and controlled conditions. Unlike previous benchmarks that primarily rely on text-based perturbations or adversarial questions while neglecting the consistency of visual backgrounds, VidPair-Halluc features video pairs with highly similar backgrounds but distinctly different foreground semantics, enabling precise attribution of model errors to genuine hallucination rather than background variation. The benchmark is constructed through PairFlow, a pipeline that leverages recent advances in text-to-image and video generation to systematically compose stories, generate coherent video clips, and assemble them into adversarial pairs. Covering both spatial and temporal reasoning across ten semantic aspects, VidPair-Halluc comprises 1K high-quality adversarial video pairs and 11K spatio-temporal QA pairs with control over background and foreground variations. Evaluations on mainstream LVMs show persistent difficulty with robust fine-grained video understanding in adversarial settings, and code and data are available at the https://jethrojames.github.io/VidPair-Halluc/.
Story2Proposal: A Scaffold for Structured Scientific Paper Writing
Mar 28, 2026Generating scientific manuscripts requires maintaining alignment between narrative reasoning, experimental evidence, and visual artifacts across the document lifecycle. Existing language-model generation pipelines rely on unconstrained text synthesis with validation applied only after generation, often producing structural drift, missing figures or tables, and cross-section inconsistencies. We introduce Story2Proposal, a contract-governed multi-agent framework that converts a research story into a structured manuscript through coordinated agents operating under a persistent shared visual contract. The system organizes architect, writer, refiner, and renderer agents around a contract state that tracks section structure and registered visual elements, while evaluation agents supply feedback in a generate evaluate adapt loop that updates the contract during generation. Experiments on tasks derived from the Jericho research corpus show that Story2Proposal achieved an expert evaluation score of 6.145 versus 3.963 for DirectChat (+2.182) across GPT, Claude, Gemini, and Qwen backbones. Compared with the structured generation baseline Fars, Story2Proposal obtained an average score of 5.705 versus 5.197, indicating improved structural consistency and visual alignment.
Unveiling the Cognitive Compass: Theory-of-Mind-Guided Multimodal Emotion Reasoning
Feb 01, 2026Despite rapid progress in multimodal large language models (MLLMs), their capability for deep emotional understanding remains limited. We argue that genuine affective intelligence requires explicit modeling of Theory of Mind (ToM), the cognitive substrate from which emotions arise. To this end, we introduce HitEmotion, a ToM-grounded hierarchical benchmark that diagnoses capability breakpoints across increasing levels of cognitive depth. Second, we propose a ToM-guided reasoning chain that tracks mental states and calibrates cross-modal evidence to achieve faithful emotional reasoning. We further introduce TMPO, a reinforcement learning method that uses intermediate mental states as process-level supervision to guide and strengthen model reasoning. Extensive experiments show that HitEmotion exposes deep emotional reasoning deficits in state-of-the-art models, especially on cognitively demanding tasks. In evaluation, the ToM-guided reasoning chain and TMPO improve end-task accuracy and yield more faithful, more coherent rationales. In conclusion, our work provides the research community with a practical toolkit for evaluating and enhancing the cognition-based emotional understanding capabilities of MLLMs. Our dataset and code are available at: https://HitEmotion.github.io/.
Multi-Agent Intelligence for Multidisciplinary Decision-Making in Gastrointestinal Oncology
Dec 23, 2025Multimodal clinical reasoning in the field of gastrointestinal (GI) oncology necessitates the integrated interpretation of endoscopic imagery, radiological data, and biochemical markers. Despite the evident potential exhibited by Multimodal Large Language Models (MLLMs), they frequently encounter challenges such as context dilution and hallucination when confronted with intricate, heterogeneous medical histories. In order to address these limitations, a hierarchical Multi-Agent Framework is proposed, which emulates the collaborative workflow of a human Multidisciplinary Team (MDT). The system attained a composite expert evaluation score of 4.60/5.00, thereby demonstrating a substantial improvement over the monolithic baseline. It is noteworthy that the agent-based architecture yielded the most substantial enhancements in reasoning logic and medical accuracy. The findings indicate that mimetic, agent-based collaboration provides a scalable, interpretable, and clinically robust paradigm for automated decision support in oncology.
Nexus: Execution-Grounded Multi-Agent Test Oracle Synthesis
Oct 30, 2025Test oracle generation in non-regression testing is a longstanding challenge in software engineering, where the goal is to produce oracles that can accurately determine whether a function under test (FUT) behaves as intended for a given input. In this paper, we introduce Nexus, a novel multi-agent framework to address this challenge. Nexus generates test oracles by leveraging a diverse set of specialized agents that synthesize test oracles through a structured process of deliberation, validation, and iterative self-refinement. During the deliberation phase, a panel of four specialist agents, each embodying a distinct testing philosophy, collaboratively critiques and refines an initial set of test oracles. Then, in the validation phase, Nexus generates a plausible candidate implementation of the FUT and executes the proposed oracles against it in a secure sandbox. For any oracle that fails this execution-based check, Nexus activates an automated selfrefinement loop, using the specific runtime error to debug and correct the oracle before re-validation. Our extensive evaluation on seven diverse benchmarks demonstrates that Nexus consistently and substantially outperforms state-of-theart baselines. For instance, Nexus improves the test-level oracle accuracy on the LiveCodeBench from 46.30% to 57.73% for GPT-4.1-Mini. The improved accuracy also significantly enhances downstream tasks: the bug detection rate of GPT4.1-Mini generated test oracles on HumanEval increases from 90.91% to 95.45% for Nexus compared to baselines, and the success rate of automated program repair improves from 35.23% to 69.32%.
EMULATE: A Multi-Agent Framework for Determining the Veracity of Atomic Claims by Emulating Human Actions
May 22, 2025



Determining the veracity of atomic claims is an imperative component of many recently proposed fact-checking systems. Many approaches tackle this problem by first retrieving evidence by querying a search engine and then performing classification by providing the evidence set and atomic claim to a large language model, but this process deviates from what a human would do in order to perform the task. Recent work attempted to address this issue by proposing iterative evidence retrieval, allowing for evidence to be collected several times and only when necessary. Continuing along this line of research, we propose a novel claim verification system, called EMULATE, which is designed to better emulate human actions through the use of a multi-agent framework where each agent performs a small part of the larger task, such as ranking search results according to predefined criteria or evaluating webpage content. Extensive experiments on several benchmarks show clear improvements over prior work, demonstrating the efficacy of our new multi-agent framework.
On Path to Multimodal Generalist: General-Level and General-Bench
May 07, 2025The Multimodal Large Language Model (MLLM) is currently experiencing rapid growth, driven by the advanced capabilities of LLMs. Unlike earlier specialists, existing MLLMs are evolving towards a Multimodal Generalist paradigm. Initially limited to understanding multiple modalities, these models have advanced to not only comprehend but also generate across modalities. Their capabilities have expanded from coarse-grained to fine-grained multimodal understanding and from supporting limited modalities to arbitrary ones. While many benchmarks exist to assess MLLMs, a critical question arises: Can we simply assume that higher performance across tasks indicates a stronger MLLM capability, bringing us closer to human-level AI? We argue that the answer is not as straightforward as it seems. This project introduces General-Level, an evaluation framework that defines 5-scale levels of MLLM performance and generality, offering a methodology to compare MLLMs and gauge the progress of existing systems towards more robust multimodal generalists and, ultimately, towards AGI. At the core of the framework is the concept of Synergy, which measures whether models maintain consistent capabilities across comprehension and generation, and across multiple modalities. To support this evaluation, we present General-Bench, which encompasses a broader spectrum of skills, modalities, formats, and capabilities, including over 700 tasks and 325,800 instances. The evaluation results that involve over 100 existing state-of-the-art MLLMs uncover the capability rankings of generalists, highlighting the challenges in reaching genuine AI. We expect this project to pave the way for future research on next-generation multimodal foundation models, providing a robust infrastructure to accelerate the realization of AGI. Project page: https://generalist.top/
VistaDPO: Video Hierarchical Spatial-Temporal Direct Preference Optimization for Large Video Models
Apr 17, 2025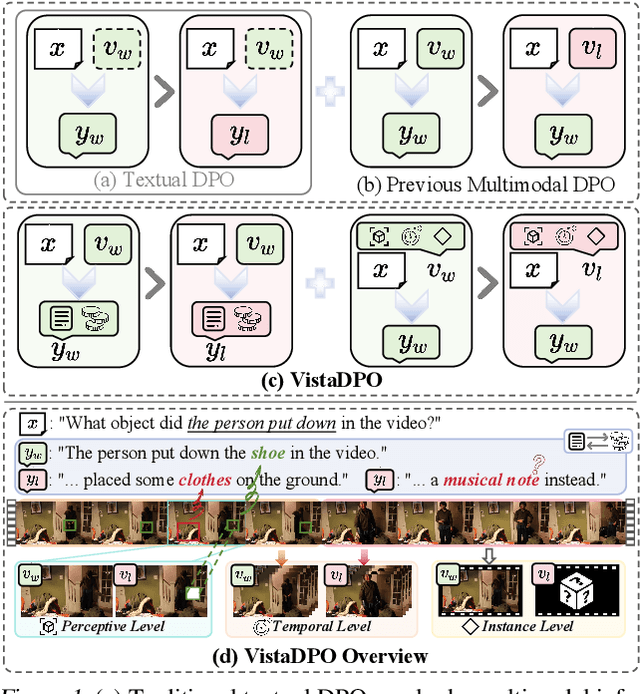
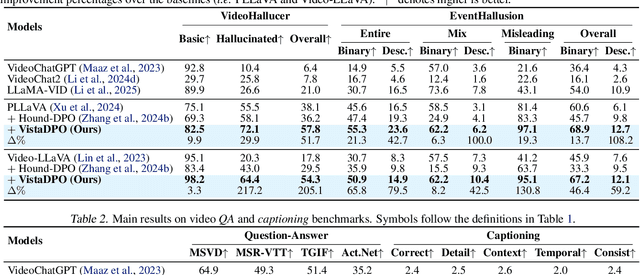
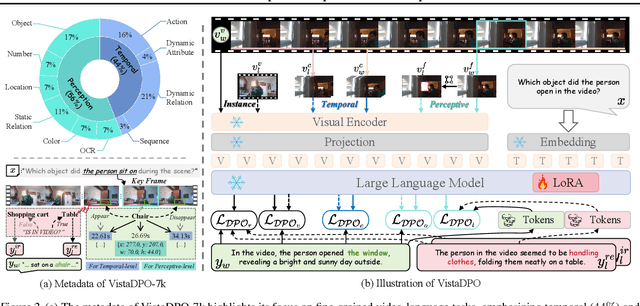
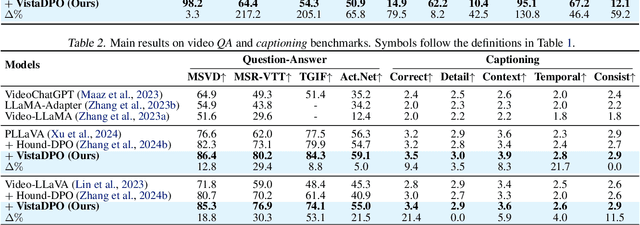
Large Video Models (LVMs) built upon Large Language Models (LLMs) have shown promise in video understanding but often suffer from misalignment with human intuition and video hallucination issues. To address these challenges, we introduce VistaDPO, a novel framework for Video Hierarchical Spatial-Temporal Direct Preference Optimization. VistaDPO enhances text-video preference alignment across three hierarchical levels: i) Instance Level, aligning overall video content with responses; ii) Temporal Level, aligning video temporal semantics with event descriptions; and iii) Perceptive Level, aligning spatial objects with language tokens. Given the lack of datasets for fine-grained video-language preference alignment, we construct VistaDPO-7k, a dataset of 7.2K QA pairs annotated with chosen and rejected responses, along with spatial-temporal grounding information such as timestamps, keyframes, and bounding boxes. Extensive experiments on benchmarks such as Video Hallucination, Video QA, and Captioning performance tasks demonstrate that VistaDPO significantly improves the performance of existing LVMs, effectively mitigating video-language misalignment and hallucination. The code and data are available at https://github.com/HaroldChen19/VistaDPO.
Aristotle: Mastering Logical Reasoning with A Logic-Complete Decompose-Search-Resolve Framework
Dec 22, 2024In the context of large language models (LLMs), current advanced reasoning methods have made impressive strides in various reasoning tasks. However, when it comes to logical reasoning tasks, major challenges remain in both efficacy and efficiency. This is rooted in the fact that these systems fail to fully leverage the inherent structure of logical tasks throughout the reasoning processes such as decomposition, search, and resolution. To address this, we propose a logic-complete reasoning framework, Aristotle, with three key components: Logical Decomposer, Logical Search Router, and Logical Resolver. In our framework, symbolic expressions and logical rules are comprehensively integrated into the entire reasoning process, significantly alleviating the bottlenecks of logical reasoning, i.e., reducing sub-task complexity, minimizing search errors, and resolving logical contradictions. The experimental results on several datasets demonstrate that Aristotle consistently outperforms state-of-the-art reasoning frameworks in both accuracy and efficiency, particularly excelling in complex logical reasoning scenarios. We will open-source all our code at https://github.com/Aiden0526/Aristotle.
PAD: Personalized Alignment at Decoding-Time
Oct 14, 2024



Aligning with personalized preferences, which vary significantly across cultural, educational, and political differences, poses a significant challenge due to the computational costs and data demands of traditional alignment methods. In response, this paper presents Personalized Alignment at Decoding-time (PAD), a novel framework designed to align LLM outputs with diverse personalized preferences during the inference phase, eliminating the need for additional training. By introducing a unique personalized reward modeling strategy, this framework decouples the text generation process from personalized preferences, facilitating the generation of generalizable token-level personalized rewards. The PAD algorithm leverages these rewards to guide the decoding process, dynamically tailoring the base model's predictions to personalized preferences. Extensive experimental results demonstrate that PAD not only outperforms existing training-based alignment methods in terms of aligning with diverse preferences but also shows significant generalizability to preferences unseen during training and scalability across different base models. This work advances the capability of LLMs to meet user needs in real-time applications, presenting a substantial step forward in personalized LLM alignment.