 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNOVIS: A Case for End-to-End Near-Online Video Instance Segmentation
Aug 29, 2023



Until recently, the Video Instance Segmentation (VIS) community operated under the common belief that offline methods are generally superior to a frame by frame online processing. However, the recent success of online methods questions this belief, in particular, for challenging and long video sequences. We understand this work as a rebuttal of those recent observations and an appeal to the community to focus on dedicated near-online VIS approaches. To support our argument, we present a detailed analysis on different processing paradigms and the new end-to-end trainable NOVIS (Near-Online Video Instance Segmentation) method. Our transformer-based model directly predicts spatio-temporal mask volumes for clips of frames and performs instance tracking between clips via overlap embeddings. NOVIS represents the first near-online VIS approach which avoids any handcrafted tracking heuristics. We outperform all existing VIS methods by large margins and provide new state-of-the-art results on both YouTube-VIS (2019/2021) and the OVIS benchmarks.
SiLK -- Simple Learned Keypoints
Apr 12, 2023



Keypoint detection & descriptors are foundational tech-nologies for computer vision tasks like image matching, 3D reconstruction and visual odometry. Hand-engineered methods like Harris corners, SIFT, and HOG descriptors have been used for decades; more recently, there has been a trend to introduce learning in an attempt to improve keypoint detectors. On inspection however, the results are difficult to interpret; recent learning-based methods employ a vast diversity of experimental setups and design choices: empirical results are often reported using different backbones, protocols, datasets, types of supervisions or tasks. Since these differences are often coupled together, it raises a natural question on what makes a good learned keypoint detector. In this work, we revisit the design of existing keypoint detectors by deconstructing their methodologies and identifying the key components. We re-design each component from first-principle and propose Simple Learned Keypoints (SiLK) that is fully-differentiable, lightweight, and flexible. Despite its simplicity, SiLK advances new state-of-the-art on Detection Repeatability and Homography Estimation tasks on HPatches and 3D Point-Cloud Registration task on ScanNet, and achieves competitive performance to state-of-the-art on camera pose estimation in 2022 Image Matching Challenge and ScanNet.
MINOTAUR: Multi-task Video Grounding From Multimodal Queries
Feb 16, 2023



Video understanding tasks take many forms, from action detection to visual query localization and spatio-temporal grounding of sentences. These tasks differ in the type of inputs (only video, or video-query pair where query is an image region or sentence) and outputs (temporal segments or spatio-temporal tubes). However, at their core they require the same fundamental understanding of the video, i.e., the actors and objects in it, their actions and interactions. So far these tasks have been tackled in isolation with individual, highly specialized architectures, which do not exploit the interplay between tasks. In contrast, in this paper, we present a single, unified model for tackling query-based video understanding in long-form videos. In particular, our model can address all three tasks of the Ego4D Episodic Memory benchmark which entail queries of three different forms: given an egocentric video and a visual, textual or activity query, the goal is to determine when and where the answer can be seen within the video. Our model design is inspired by recent query-based approaches to spatio-temporal grounding, and contains modality-specific query encoders and task-specific sliding window inference that allow multi-task training with diverse input modalities and different structured outputs. We exhaustively analyze relationships among the tasks and illustrate that cross-task learning leads to improved performance on each individual task, as well as the ability to generalize to unseen tasks, such as zero-shot spatial localization of language queries.
EgoTracks: A Long-term Egocentric Visual Object Tracking Dataset
Jan 11, 2023



Visual object tracking is a key component to many egocentric vision problems. However, the full spectrum of challenges of egocentric tracking faced by an embodied AI is underrepresented in many existing datasets; these tend to focus on relatively short, third-person videos. Egocentric video has several distinguishing characteristics from those commonly found in past datasets: frequent large camera motions and hand interactions with objects commonly lead to occlusions or objects exiting the frame, and object appearance can change rapidly due to widely different points of view, scale, or object states. Embodied tracking is also naturally long-term, and being able to consistently (re-)associate objects to their appearances and disappearances over as long as a lifetime is critical. Previous datasets under-emphasize this re-detection problem, and their "framed" nature has led to adoption of various spatiotemporal priors that we find do not necessarily generalize to egocentric video. We thus introduce EgoTracks, a new dataset for long-term egocentric visual object tracking. Sourced from the Ego4D dataset, this new dataset presents a significant challenge to recent state-of-the-art single-object tracking models, which we find score poorly on traditional tracking metrics for our new dataset, compared to popular benchmarks. We further show improvements that can be made to a STARK tracker to significantly increase its performance on egocentric data, resulting in a baseline model we call EgoSTARK. We publicly release our annotations and benchmark, hoping our dataset leads to further advancements in tracking.
Open-World Instance Segmentation: Exploiting Pseudo Ground Truth From Learned Pairwise Affinity
Apr 12, 2022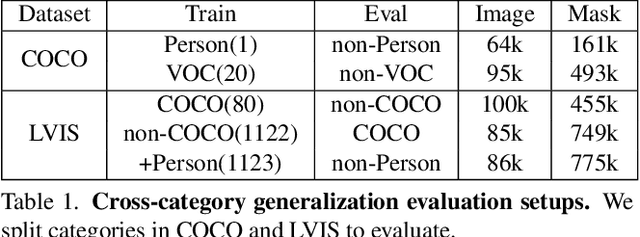
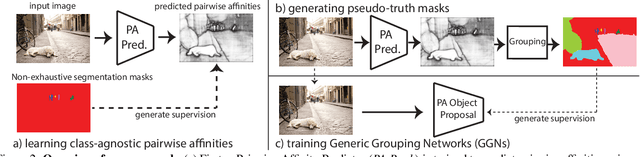


Open-world instance segmentation is the task of grouping pixels into object instances without any pre-determined taxonomy. This is challenging, as state-of-the-art methods rely on explicit class semantics obtained from large labeled datasets, and out-of-domain evaluation performance drops significantly. Here we propose a novel approach for mask proposals, Generic Grouping Networks (GGNs), constructed without semantic supervision. Our approach combines a local measure of pixel affinity with instance-level mask supervision, producing a training regimen designed to make the model as generic as the data diversity allows. We introduce a method for predicting Pairwise Affinities (PA), a learned local relationship between pairs of pixels. PA generalizes very well to unseen categories. From PA we construct a large set of pseudo-ground-truth instance masks; combined with human-annotated instance masks we train GGNs and significantly outperform the SOTA on open-world instance segmentation on various benchmarks including COCO, LVIS, ADE20K, and UVO. Code is available on project website: https://sites.google.com/view/generic-grouping/.
GEB+: A benchmark for generic event boundary captioning, grounding and text-based retrieval
Apr 10, 2022



Cognitive science has shown that humans perceive videos in terms of events separated by state changes of dominant subjects. State changes trigger new events and are one of the most useful among the large amount of redundant information perceived. However, previous research focuses on the overall understanding of segments without evaluating the fine-grained status changes inside. In this paper, we introduce a new dataset called Kinetic-GEBC (Generic Event Boundary Captioning). The dataset consists of over 170k boundaries associated with captions describing status changes in the generic events in 12K videos. Upon this new dataset, we propose three tasks supporting the development of a more fine-grained, robust, and human-like understanding of videos through status changes. We evaluate many representative baselines in our dataset, where we also design a new TPD (Temporal-based Pairwise Difference) Modeling method for current state-of-the-art backbones and achieve significant performance improvements. Besides, the results show there are still formidable challenges for current methods in the utilization of different granularities, representation of visual difference, and the accurate localization of status changes. Further analysis shows that our dataset can drive developing more powerful methods to understand status changes and thus improve video level comprehension.
PyTorchVideo: A Deep Learning Library for Video Understanding
Nov 18, 2021
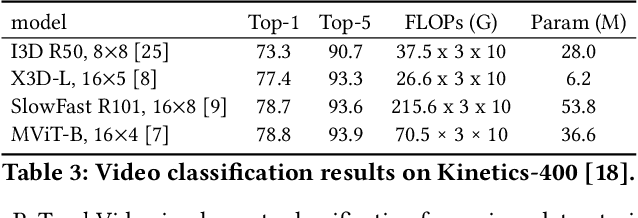

We introduce PyTorchVideo, an open-source deep-learning library that provides a rich set of modular, efficient, and reproducible components for a variety of video understanding tasks, including classification, detection, self-supervised learning, and low-level processing. The library covers a full stack of video understanding tools including multimodal data loading, transformations, and models that reproduce state-of-the-art performance. PyTorchVideo further supports hardware acceleration that enables real-time inference on mobile devices. The library is based on PyTorch and can be used by any training framework; for example, PyTorchLightning, PySlowFast, or Classy Vision. PyTorchVideo is available at https://pytorchvideo.org/
Searching for Two-Stream Models in Multivariate Space for Video Recognition
Aug 30, 2021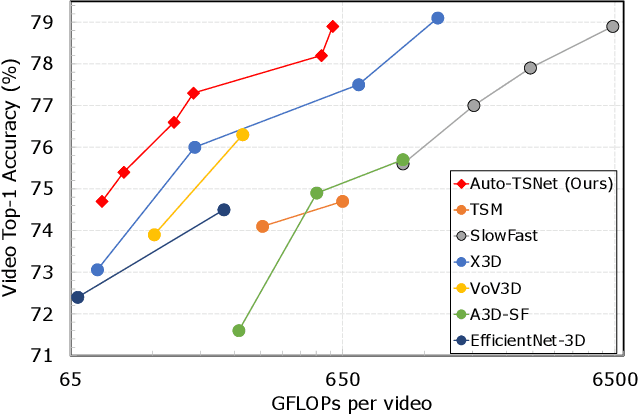
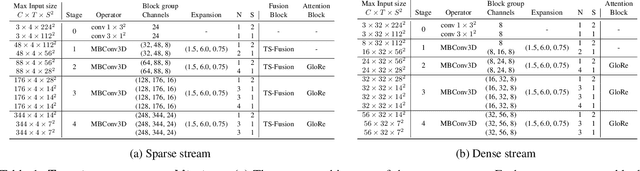
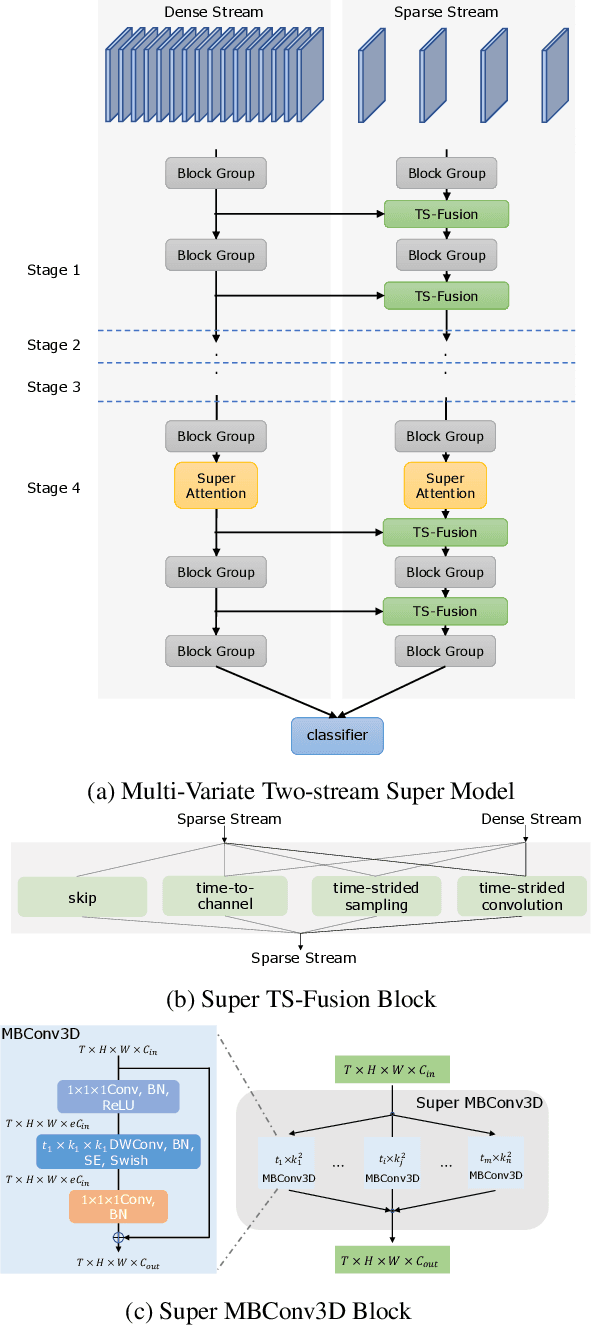

Conventional video models rely on a single stream to capture the complex spatial-temporal features. Recent work on two-stream video models, such as SlowFast network and AssembleNet, prescribe separate streams to learn complementary features, and achieve stronger performance. However, manually designing both streams as well as the in-between fusion blocks is a daunting task, requiring to explore a tremendously large design space. Such manual exploration is time-consuming and often ends up with sub-optimal architectures when computational resources are limited and the exploration is insufficient. In this work, we present a pragmatic neural architecture search approach, which is able to search for two-stream video models in giant spaces efficiently. We design a multivariate search space, including 6 search variables to capture a wide variety of choices in designing two-stream models. Furthermore, we propose a progressive search procedure, by searching for the architecture of individual streams, fusion blocks, and attention blocks one after the other. We demonstrate two-stream models with significantly better performance can be automatically discovered in our design space. Our searched two-stream models, namely Auto-TSNet, consistently outperform other models on standard benchmarks. On Kinetics, compared with the SlowFast model, our Auto-TSNet-L model reduces FLOPS by nearly 11 times while achieving the same accuracy 78.9%. On Something-Something-V2, Auto-TSNet-M improves the accuracy by at least 2% over other methods which use less than 50 GFLOPS per video.
Unidentified Video Objects: A Benchmark for Dense, Open-World Segmentation
Apr 10, 2021
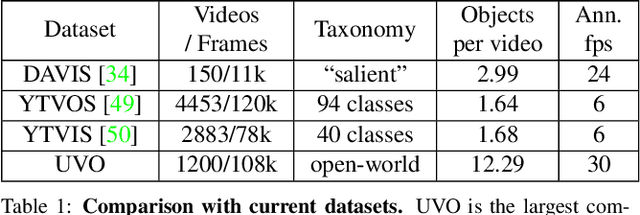
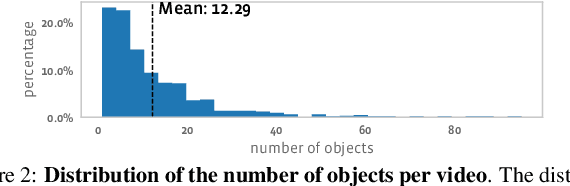

Current state-of-the-art object detection and segmentation methods work well under the closed-world assumption. This closed-world setting assumes that the list of object categories is available during training and deployment. However, many real-world applications require detecting or segmenting novel objects, i.e., object categories never seen during training. In this paper, we present, UVO (Unidentified Video Objects), a new benchmark for open-world class-agnostic object segmentation in videos. Besides shifting the problem focus to the open-world setup, UVO is significantly larger, providing approximately 8 times more videos compared with DAVIS, and 7 times more mask (instance) annotations per video compared with YouTube-VOS and YouTube-VIS. UVO is also more challenging as it includes many videos with crowded scenes and complex background motions. We demonstrated that UVO can be used for other applications, such as object tracking and super-voxel segmentation, besides open-world object segmentation. We believe that UVo is a versatile testbed for researchers to develop novel approaches for open-world class-agnostic object segmentation, and inspires new research directions towards a more comprehensive video understanding beyond classification and detection.
Generic Event Boundary Detection: A Benchmark for Event Segmentation
Jan 26, 2021
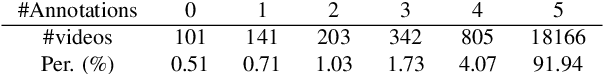
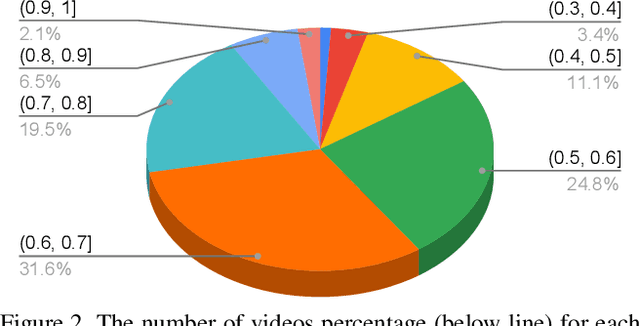
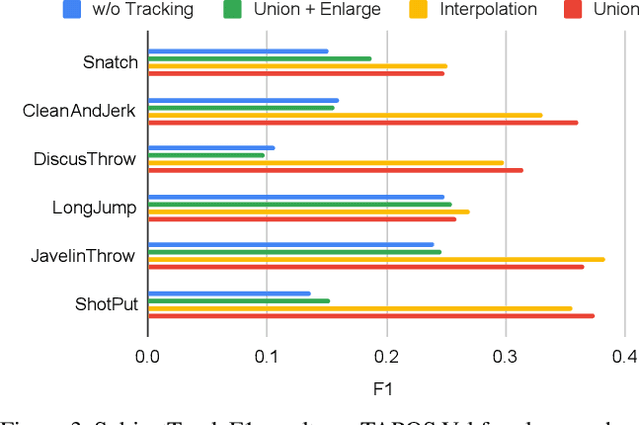
This paper presents a novel task together with a new benchmark for detecting generic, taxonomy-free event boundaries that segment a whole video into chunks. Conventional work in temporal video segmentation and action detection focuses on localizing pre-defined action categories and thus does not scale to generic videos. Cognitive Science has known since last century that humans consistently segment videos into meaningful temporal chunks. This segmentation happens naturally, with no pre-defined event categories and without being explicitly asked to do so. Here, we repeat these cognitive experiments on mainstream CV datasets; with our novel annotation guideline which addresses the complexities of taxonomy-free event boundary annotation, we introduce the task of Generic Event Boundary Detection (GEBD) and the new benchmark Kinetics-GEBD. Through experiment and human study we demonstrate the value of the annotations. We view this as an important stepping stone towards understanding the video as a whole, and believe it has been previously neglected due to a lack of proper task definition and annotations. Further, inspired by the cognitive finding that humans mark boundaries at points where they are unable to predict the future accurately, we explore un-supervised approaches based on temporal predictability. We identify and extensively explore important design factors for GEBD models on the TAPOS dataset and our Kinetics-GEBD while achieving competitive performance and suggesting future work. We will release our annotations and code at CVPR'21 LOVEU Challenge: https://sites.google.com/view/loveucvpr21