 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Relevant Failure Detection for Trajectory Predictors in Autonomous Vehicles
Jul 25, 2022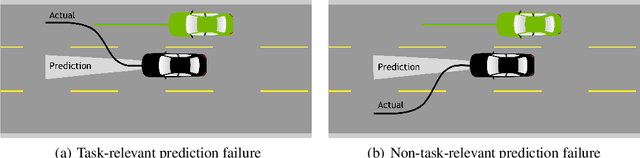
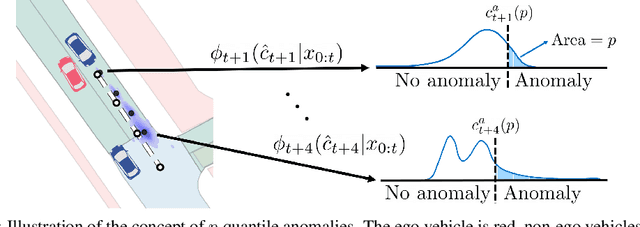
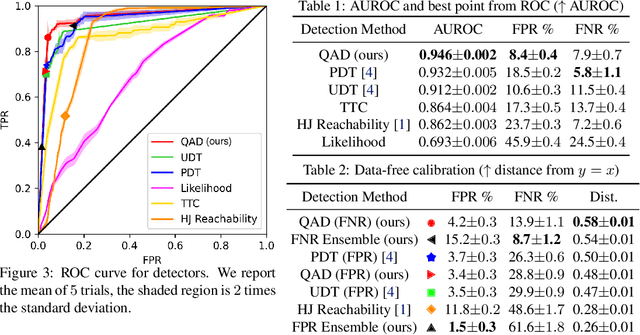
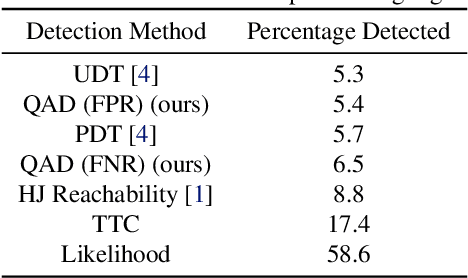
In modern autonomy stacks, prediction modules are paramount to planning motions in the presence of other mobile agents. However, failures in prediction modules can mislead the downstream planner into making unsafe decisions. Indeed, the high uncertainty inherent to the task of trajectory forecasting ensures that such mispredictions occur frequently. Motivated by the need to improve safety of autonomous vehicles without compromising on their performance, we develop a probabilistic run-time monitor that detects when a "harmful" prediction failure occurs, i.e., a task-relevant failure detector. We achieve this by propagating trajectory prediction errors to the planning cost to reason about their impact on the AV. Furthermore, our detector comes equipped with performance measures on the false-positive and the false-negative rate and allows for data-free calibration. In our experiments we compared our detector with various others and found that our detector has the highest area under the receiver operator characteristic curve.
Interaction-Dynamics-Aware Perception Zones for Obstacle Detection Safety Evaluation
Jun 24, 2022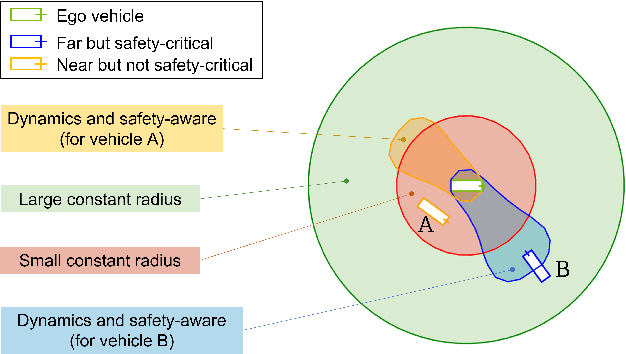
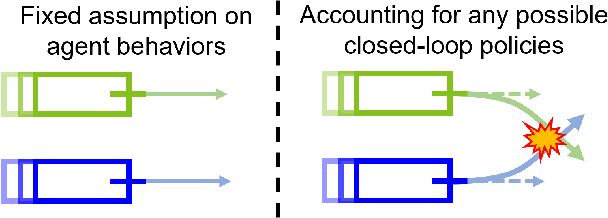
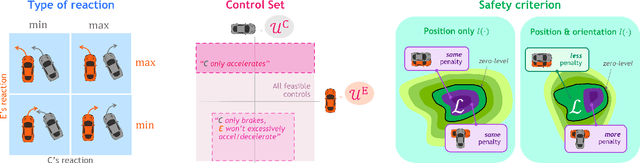
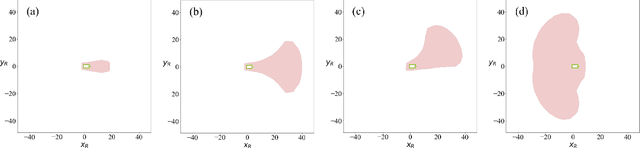
To enable safe autonomous vehicle (AV) operations, it is critical that an AV's obstacle detection module can reliably detect obstacles that pose a safety threat (i.e., are safety-critical). It is therefore desirable that the evaluation metric for the perception system captures the safety-criticality of objects. Unfortunately, existing perception evaluation metrics tend to make strong assumptions about the objects and ignore the dynamic interactions between agents, and thus do not accurately capture the safety risks in reality. To address these shortcomings, we introduce an interaction-dynamics-aware obstacle detection evaluation metric by accounting for closed-loop dynamic interactions between an ego vehicle and obstacles in the scene. By borrowing existing theory from optimal control theory, namely Hamilton-Jacobi reachability, we present a computationally tractable method for constructing a ``safety zone'': a region in state space that defines where safety-critical obstacles lie for the purpose of defining safety metrics. Our proposed safety zone is mathematically complete, and can be easily computed to reflect a variety of safety requirements. Using an off-the-shelf detection algorithm from the nuScenes detection challenge leaderboard, we demonstrate that our approach is computationally lightweight, and can better capture safety-critical perception errors than a baseline approach.
ScePT: Scene-consistent, Policy-based Trajectory Predictions for Planning
Jun 18, 2022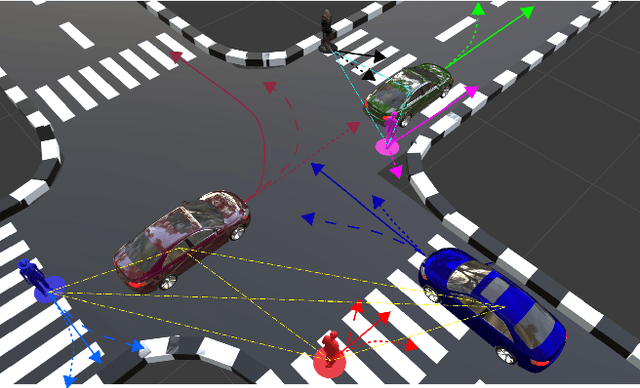
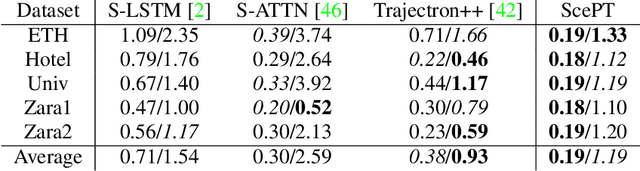
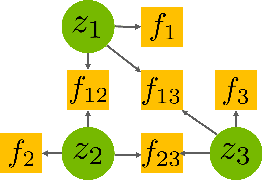
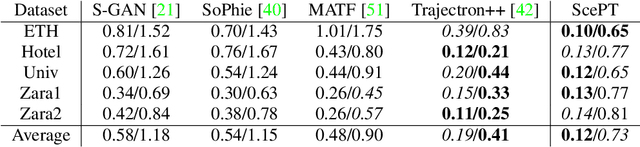
Trajectory prediction is a critical functionality of autonomous systems that share environments with uncontrolled agents, one prominent example being self-driving vehicles. Currently, most prediction methods do not enforce scene consistency, i.e., there are a substantial amount of self-collisions between predicted trajectories of different agents in the scene. Moreover, many approaches generate individual trajectory predictions per agent instead of joint trajectory predictions of the whole scene, which makes downstream planning difficult. In this work, we present ScePT, a policy planning-based trajectory prediction model that generates accurate, scene-consistent trajectory predictions suitable for autonomous system motion planning. It explicitly enforces scene consistency and learns an agent interaction policy that can be used for conditional prediction. Experiments on multiple real-world pedestrians and autonomous vehicle datasets show that ScePT} matches current state-of-the-art prediction accuracy with significantly improved scene consistency. We also demonstrate ScePT's ability to work with a downstream contingency planner.
Robust-RRT: Probabilistically-Complete Motion Planning for Uncertain Nonlinear Systems
May 16, 2022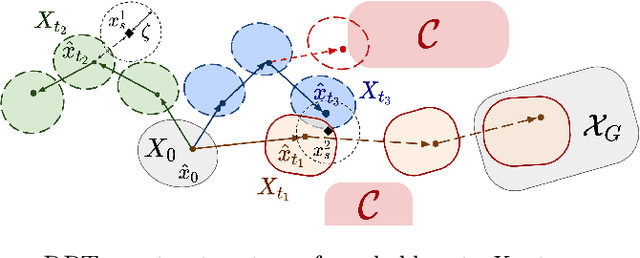
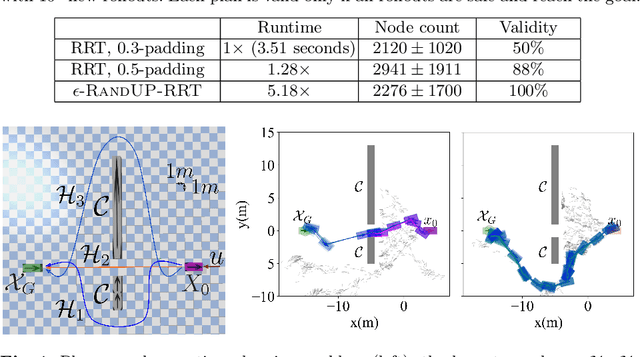
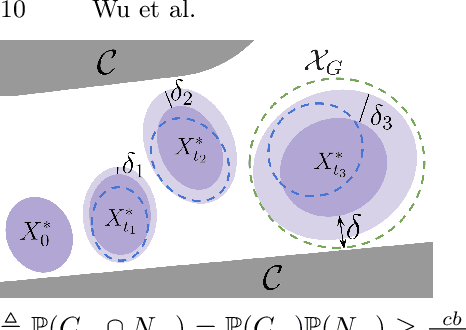

Robust motion planning entails computing a global motion plan that is safe under all possible uncertainty realizations, be it in the system dynamics, the robot's initial position, or with respect to external disturbances. Current approaches for robust motion planning either lack theoretical guarantees, or make restrictive assumptions on the system dynamics and uncertainty distributions. In this paper, we address these limitations by proposing the robust rapidly-exploring random-tree (Robust-RRT) algorithm, which integrates forward reachability analysis directly into sampling-based control trajectory synthesis. We prove that Robust-RRT is probabilistically complete (PC) for nonlinear Lipschitz continuous dynamical systems with bounded uncertainty. In other words, Robust-RRT eventually finds a robust motion plan that is feasible under all possible uncertainty realizations assuming such a plan exists. Our analysis applies even to unstable systems that admit only short-horizon feasible plans; this is because we explicitly consider the time evolution of reachable sets along control trajectories. Thanks to the explicit consideration of time dependency in our analysis, PC applies to unstabilizable systems. To the best of our knowledge, this is the most general PC proof for robust sampling-based motion planning, in terms of the types of uncertainties and dynamical systems it can handle. Considering that an exact computation of reachable sets can be computationally expensive for some dynamical systems, we incorporate sampling-based reachability analysis into Robust-RRT and demonstrate our robust planner on nonlinear, underactuated, and hybrid systems.
Second-Order Sensitivity Analysis for Bilevel Optimization
May 04, 2022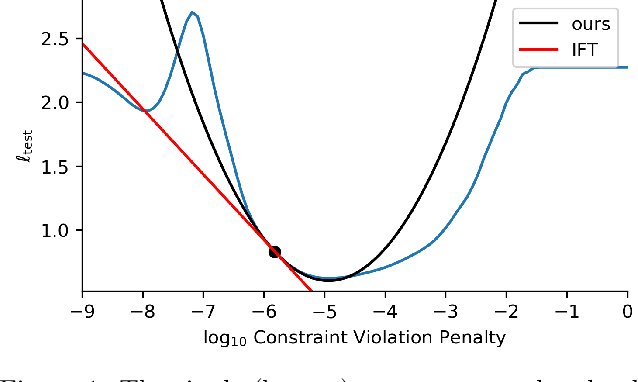
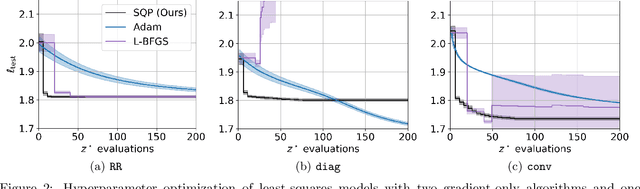
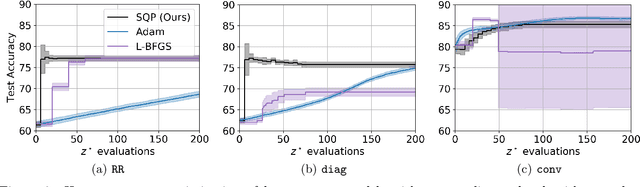
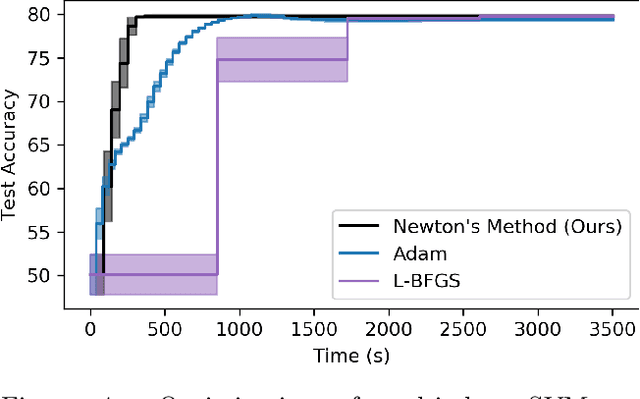
In this work we derive a second-order approach to bilevel optimization, a type of mathematical programming in which the solution to a parameterized optimization problem (the "lower" problem) is itself to be optimized (in the "upper" problem) as a function of the parameters. Many existing approaches to bilevel optimization employ first-order sensitivity analysis, based on the implicit function theorem (IFT), for the lower problem to derive a gradient of the lower problem solution with respect to its parameters; this IFT gradient is then used in a first-order optimization method for the upper problem. This paper extends this sensitivity analysis to provide second-order derivative information of the lower problem (which we call the IFT Hessian), enabling the usage of faster-converging second-order optimization methods at the upper level. Our analysis shows that (i) much of the computation already used to produce the IFT gradient can be reused for the IFT Hessian, (ii) errors bounds derived for the IFT gradient readily apply to the IFT Hessian, (iii) computing IFT Hessians can significantly reduce overall computation by extracting more information from each lower level solve. We corroborate our findings and demonstrate the broad range of applications of our method by applying it to problem instances of least squares hyperparameter auto-tuning, multi-class SVM auto-tuning, and inverse optimal control.
* 16 pages, 6 figures
Safe Reinforcement Learning Using Black-Box Reachability Analysis
Apr 15, 2022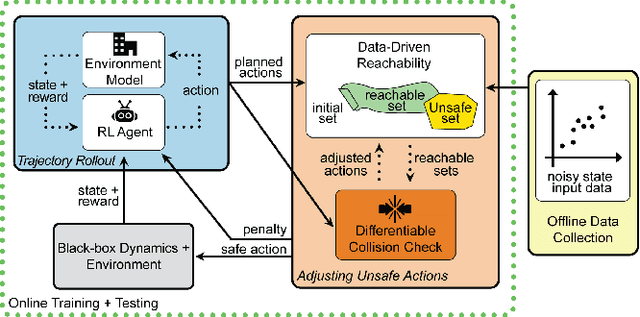
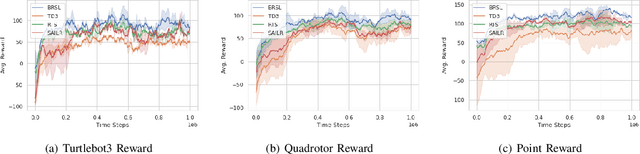

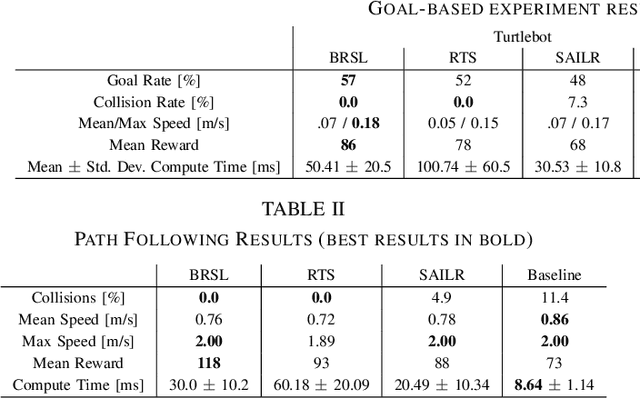
Reinforcement learning (RL) is capable of sophisticated motion planning and control for robots in uncertain environments. However, state-of-the-art deep RL approaches typically lack safety guarantees, especially when the robot and environment models are unknown. To justify widespread deployment, robots must respect safety constraints without sacrificing performance. Thus, we propose a Black-box Reachability-based Safety Layer (BRSL) with three main components: (1) data-driven reachability analysis for a black-box robot model, (2) a trajectory rollout planner that predicts future actions and observations using an ensemble of neural networks trained online, and (3) a differentiable polytope collision check between the reachable set and obstacles that enables correcting unsafe actions. In simulation, BRSL outperforms other state-of-the-art safe RL methods on a Turtlebot 3, a quadrotor, and a trajectory-tracking point mass with an unsafe set adjacent to the area of highest reward.
Control-oriented meta-learning
Apr 14, 2022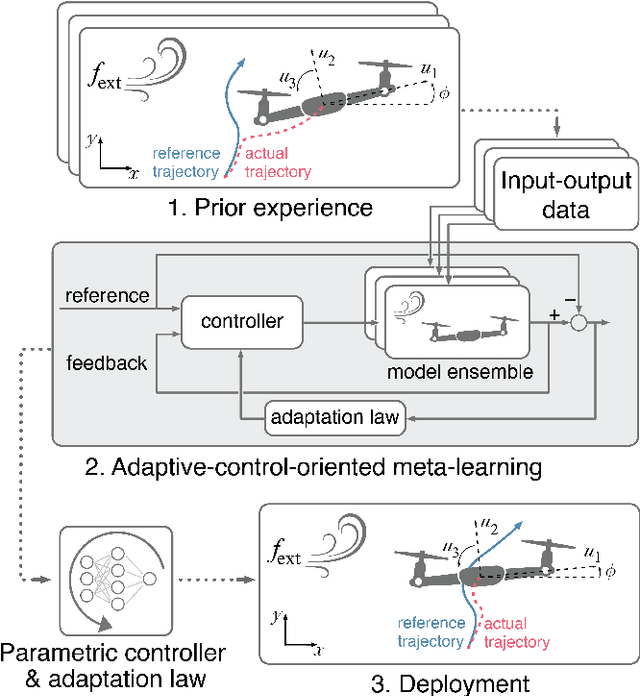
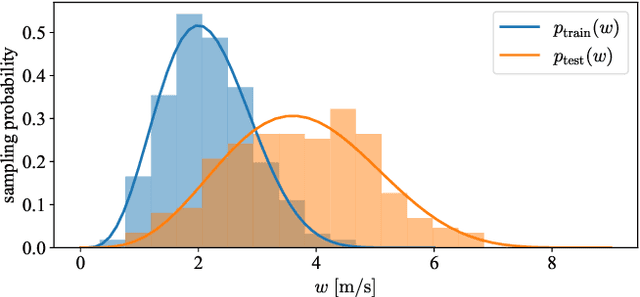
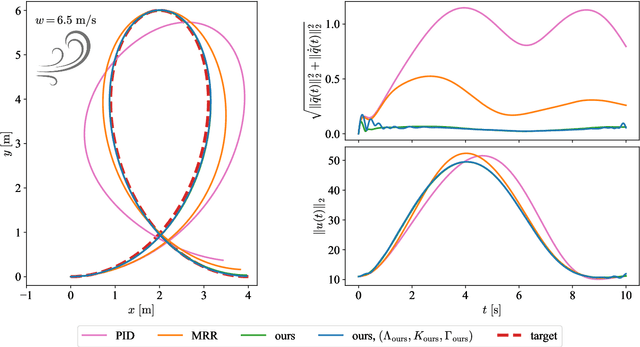
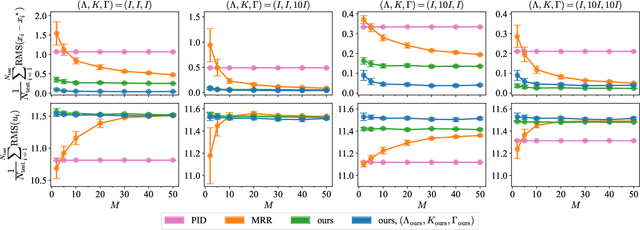
Real-time adaptation is imperative to the control of robots operating in complex, dynamic environments. Adaptive control laws can endow even nonlinear systems with good trajectory tracking performance, provided that any uncertain dynamics terms are linearly parameterizable with known nonlinear features. However, it is often difficult to specify such features a priori, such as for aerodynamic disturbances on rotorcraft or interaction forces between a manipulator arm and various objects. In this paper, we turn to data-driven modeling with neural networks to learn, offline from past data, an adaptive controller with an internal parametric model of these nonlinear features. Our key insight is that we can better prepare the controller for deployment with control-oriented meta-learning of features in closed-loop simulation, rather than regression-oriented meta-learning of features to fit input-output data. Specifically, we meta-learn the adaptive controller with closed-loop tracking simulation as the base-learner and the average tracking error as the meta-objective. With both fully-actuated and underactuated nonlinear planar rotorcraft subject to wind, we demonstrate that our adaptive controller outperforms other controllers trained with regression-oriented meta-learning when deployed in closed-loop for trajectory tracking control.
Online Learning for Traffic Routing under Unknown Preferences
Mar 31, 2022
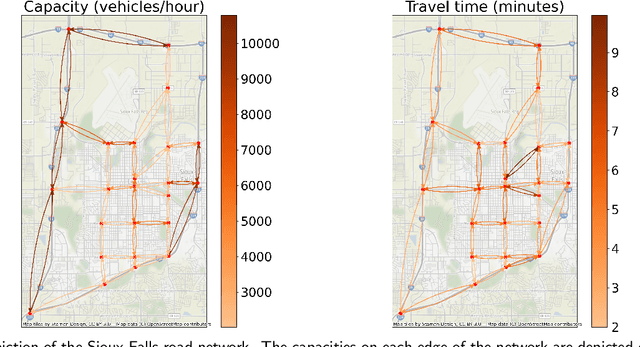
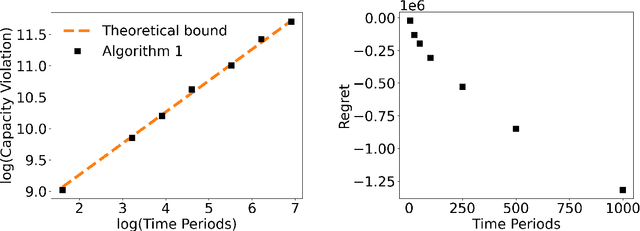
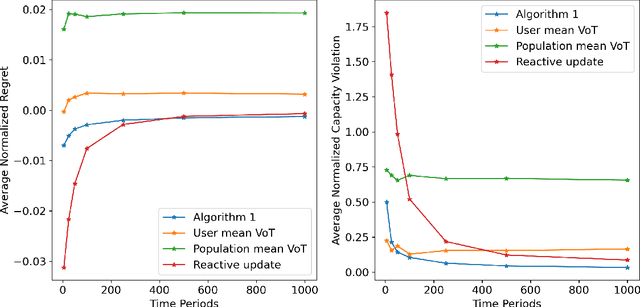
In transportation networks, users typically choose routes in a decentralized and self-interested manner to minimize their individual travel costs, which, in practice, often results in inefficient overall outcomes for society. As a result, there has been a growing interest in designing road tolling schemes to cope with these efficiency losses and steer users toward a system-efficient traffic pattern. However, the efficacy of road tolling schemes often relies on having access to complete information on users' trip attributes, such as their origin-destination (O-D) travel information and their values of time, which may not be available in practice. Motivated by this practical consideration, we propose an online learning approach to set tolls in a traffic network to drive heterogeneous users with different values of time toward a system-efficient traffic pattern. In particular, we develop a simple yet effective algorithm that adjusts tolls at each time period solely based on the observed aggregate flows on the roads of the network without relying on any additional trip attributes of users, thereby preserving user privacy. In the setting where the O-D pairs and values of time of users are drawn i.i.d. at each period, we show that our approach obtains an expected regret and road capacity violation of $O(\sqrt{T})$, where $T$ is the number of periods over which tolls are updated. Our regret guarantee is relative to an offline oracle that has complete information on users' trip attributes. We further establish a $\Omega(\sqrt{T})$ lower bound on the regret of any algorithm, which establishes that our algorithm is optimal up to constants. Finally, we demonstrate the superior performance of our approach relative to several benchmarks on a real-world transportation network, thereby highlighting its practical applicability.
Motron: Multimodal Probabilistic Human Motion Forecasting
Mar 25, 2022

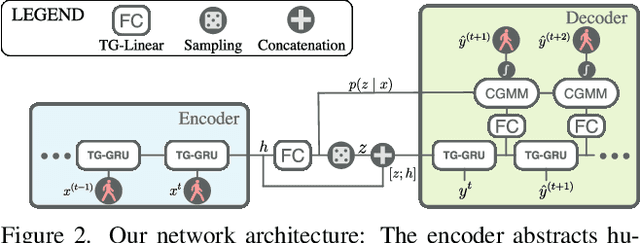
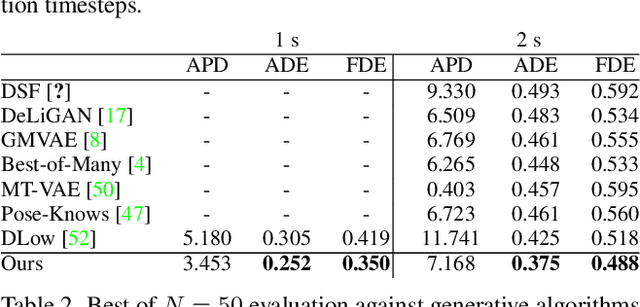
Autonomous systems and humans are increasingly sharing the same space. Robots work side by side or even hand in hand with humans to balance each other's limitations. Such cooperative interactions are ever more sophisticated. Thus, the ability to reason not just about a human's center of gravity position, but also its granular motion is an important prerequisite for human-robot interaction. Though, many algorithms ignore the multimodal nature of humans or neglect uncertainty in their motion forecasts. We present Motron, a multimodal, probabilistic, graph-structured model, that captures human's multimodality using probabilistic methods while being able to output deterministic maximum-likelihood motions and corresponding confidence values for each mode. Our model aims to be tightly integrated with the robotic planning-control-interaction loop; outputting physically feasible human motions and being computationally efficient. We demonstrate the performance of our model on several challenging real-world motion forecasting datasets, outperforming a wide array of generative/variational methods while providing state-of-the-art single-output motions if required. Both using significantly less computational power than state-of-the art algorithms.
Neural-MPC: Deep Learning Model Predictive Control for Quadrotors and Agile Robotic Platforms
Mar 15, 2022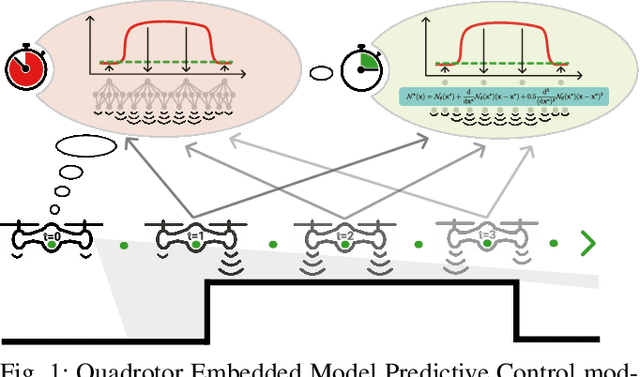
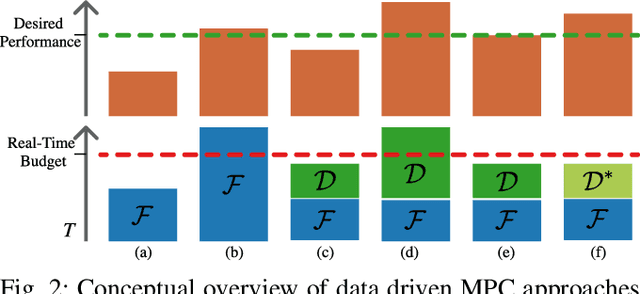
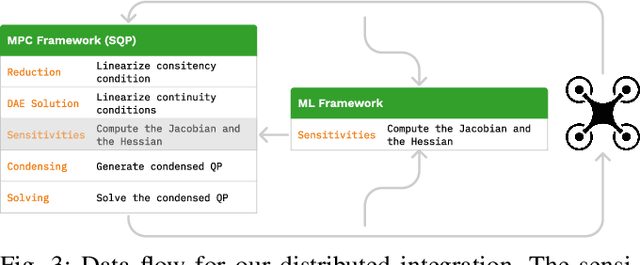
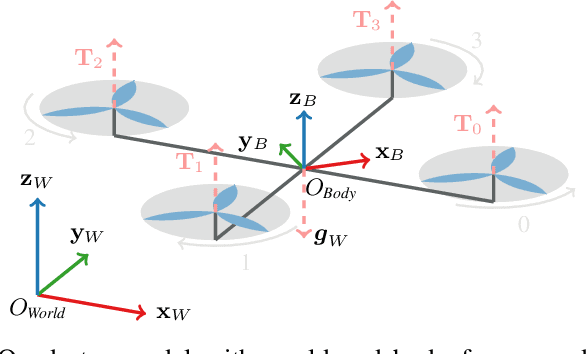
Model Predictive Control (MPC) has become a popular framework in embedded control for high-performance autonomous systems. However, to achieve good control performance using MPC, an accurate dynamics model is key. To maintain real-time operation, the dynamics models used on embedded systems have been limited to simple first-principle models, which substantially limits their representative power. In contrast, neural networks can model complex effects purely from data. In contrast to such simple models, machine learning approaches such as neural networks have been shown to accurately model even complex dynamic effects, but their large computational complexity hindered combination with fast real-time iteration loops. With this work, we present Neural-MPC, a framework to efficiently integrate large, complex neural network architectures as dynamics models within a model-predictive control pipeline. Our experiments, performed in simulation and the real world on a highly agile quadrotor platform, demonstrate up to 83% reduction in positional tracking error when compared to state-of-the-art MPC approaches without neural network dynamics.