 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning long term climate-resilient transport adaptation pathways under direct and indirect flood impacts using reinforcement learning
Jan 26, 2026Climate change is expected to intensify rainfall and other hazards, increasing disruptions in urban transportation systems. Designing effective adaptation strategies is challenging due to the long-term, sequential nature of infrastructure investments, deep uncertainty, and complex cross-sector interactions. We propose a generic decision-support framework that couples an integrated assessment model (IAM) with reinforcement learning (RL) to learn adaptive, multi-decade investment pathways under uncertainty. The framework combines long-term climate projections (e.g., IPCC scenario pathways) with models that map projected extreme-weather drivers (e.g. rain) into hazard likelihoods (e.g. flooding), propagate hazards into urban infrastructure impacts (e.g. transport disruption), and value direct and indirect consequences for service performance and societal costs. Embedded in a reinforcement-learning loop, it learns adaptive climate adaptation policies that trade off investment and maintenance expenditures against avoided impacts. In collaboration with Copenhagen Municipality, we demonstrate the approach on pluvial flooding in the inner city for the horizon of 2024 to 2100. The learned strategies yield coordinated spatial-temporal pathways and improved robustness relative to conventional optimization baselines, namely inaction and random action, illustrating the framework's transferability to other hazards and cities.
Plugging Schema Graph into Multi-Table QA: A Human-Guided Framework for Reducing LLM Reliance
Jun 04, 2025



Large language models (LLMs) have shown promise in table Question Answering (Table QA). However, extending these capabilities to multi-table QA remains challenging due to unreliable schema linking across complex tables. Existing methods based on semantic similarity work well only on simplified hand-crafted datasets and struggle to handle complex, real-world scenarios with numerous and diverse columns. To address this, we propose a graph-based framework that leverages human-curated relational knowledge to explicitly encode schema links and join paths. Given a natural language query, our method searches this graph to construct interpretable reasoning chains, aided by pruning and sub-path merging strategies to enhance efficiency and coherence. Experiments on both standard benchmarks and a realistic, large-scale dataset demonstrate the effectiveness of our approach. To our knowledge, this is the first multi-table QA system applied to truly complex industrial tabular data.
Bayesian Hierarchical Invariant Prediction
May 16, 2025We propose Bayesian Hierarchical Invariant Prediction (BHIP) reframing Invariant Causal Prediction (ICP) through the lens of Hierarchical Bayes. We leverage the hierarchical structure to explicitly test invariance of causal mechanisms under heterogeneous data, resulting in improved computational scalability for a larger number of predictors compared to ICP. Moreover, given its Bayesian nature BHIP enables the use of prior information. In this paper, we test two sparsity inducing priors: horseshoe and spike-and-slab, both of which allow us a more reliable identification of causal features. We test BHIP in synthetic and real-world data showing its potential as an alternative inference method to ICP.
Using Reinforcement Learning to Integrate Subjective Wellbeing into Climate Adaptation Decision Making
Apr 14, 2025Subjective wellbeing is a fundamental aspect of human life, influencing life expectancy and economic productivity, among others. Mobility plays a critical role in maintaining wellbeing, yet the increasing frequency and intensity of both nuisance and high-impact floods due to climate change are expected to significantly disrupt access to activities and destinations, thereby affecting overall wellbeing. Addressing climate adaptation presents a complex challenge for policymakers, who must select and implement policies from a broad set of options with varying effects while managing resource constraints and uncertain climate projections. In this work, we propose a multi-modular framework that uses reinforcement learning as a decision-support tool for climate adaptation in Copenhagen, Denmark. Our framework integrates four interconnected components: long-term rainfall projections, flood modeling, transport accessibility, and wellbeing modeling. This approach enables decision-makers to identify spatial and temporal policy interventions that help sustain or enhance subjective wellbeing over time. By modeling climate adaptation as an open-ended system, our framework provides a structured framework for exploring and evaluating adaptation policy pathways. In doing so, it supports policymakers to make informed decisions that maximize wellbeing in the long run.
Climate Adaptation with Reinforcement Learning: Experiments with Flooding and Transportation in Copenhagen
Sep 27, 2024Due to climate change the frequency and intensity of extreme rainfall events, which contribute to urban flooding, are expected to increase in many places. These floods can damage transport infrastructure and disrupt mobility, highlighting the need for cities to adapt to escalating risks. Reinforcement learning (RL) serves as a powerful tool for uncovering optimal adaptation strategies, determining how and where to deploy adaptation measures effectively, even under significant uncertainty. In this study, we leverage RL to identify the most effective timing and locations for implementing measures, aiming to reduce both direct and indirect impacts of flooding. Our framework integrates climate change projections of future rainfall events and floods, models city-wide motorized trips, and quantifies direct and indirect impacts on infrastructure and mobility. Preliminary results suggest that our RL-based approach can significantly enhance decision-making by prioritizing interventions in specific urban areas and identifying the optimal periods for their implementation.
Learning and Generalizing Polynomials in Simulation Metamodeling
Jul 20, 2023



The ability to learn polynomials and generalize out-of-distribution is essential for simulation metamodels in many disciplines of engineering, where the time step updates are described by polynomials. While feed forward neural networks can fit any function, they cannot generalize out-of-distribution for higher-order polynomials. Therefore, this paper collects and proposes multiplicative neural network (MNN) architectures that are used as recursive building blocks for approximating higher-order polynomials. Our experiments show that MNNs are better than baseline models at generalizing, and their performance in validation is true to their performance in out-of-distribution tests. In addition to MNN architectures, a simulation metamodeling approach is proposed for simulations with polynomial time step updates. For these simulations, simulating a time interval can be performed in fewer steps by increasing the step size, which entails approximating higher-order polynomials. While our approach is compatible with any simulation with polynomial time step updates, a demonstration is shown for an epidemiology simulation model, which also shows the inductive bias in MNNs for learning and generalizing higher-order polynomials.
Graph Reinforcement Learning for Network Control via Bi-Level Optimization
May 16, 2023



Optimization problems over dynamic networks have been extensively studied and widely used in the past decades to formulate numerous real-world problems. However, (1) traditional optimization-based approaches do not scale to large networks, and (2) the design of good heuristics or approximation algorithms often requires significant manual trial-and-error. In this work, we argue that data-driven strategies can automate this process and learn efficient algorithms without compromising optimality. To do so, we present network control problems through the lens of reinforcement learning and propose a graph network-based framework to handle a broad class of problems. Instead of naively computing actions over high-dimensional graph elements, e.g., edges, we propose a bi-level formulation where we (1) specify a desired next state via RL, and (2) solve a convex program to best achieve it, leading to drastically improved scalability and performance. We further highlight a collection of desirable features to system designers, investigate design decisions, and present experiments on real-world control problems showing the utility, scalability, and flexibility of our framework.
Large Scale Passenger Detection with Smartphone/Bus Implicit Interaction and Multisensory Unsupervised Cause-effect Learning
Feb 24, 2022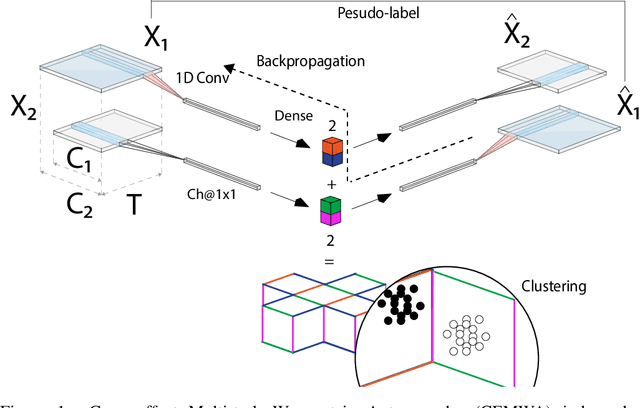
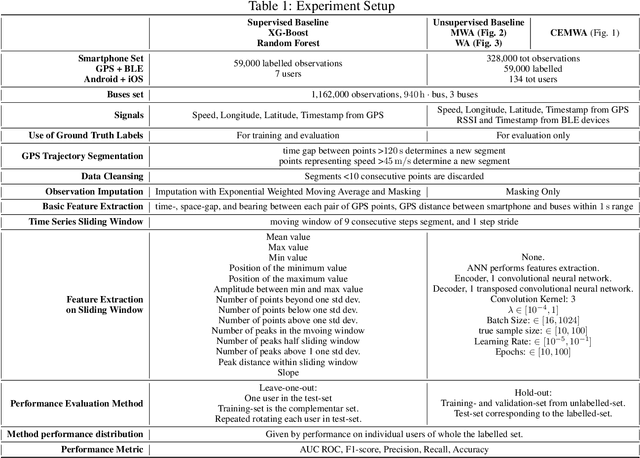
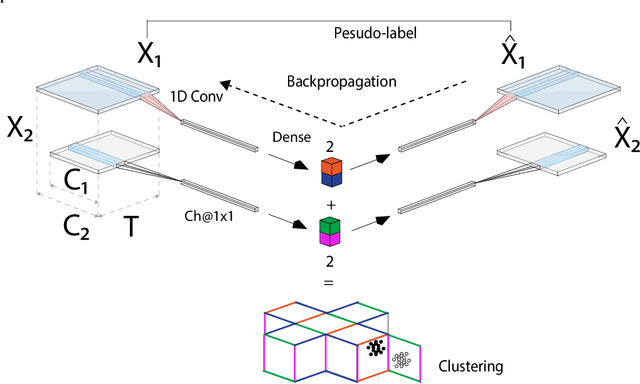
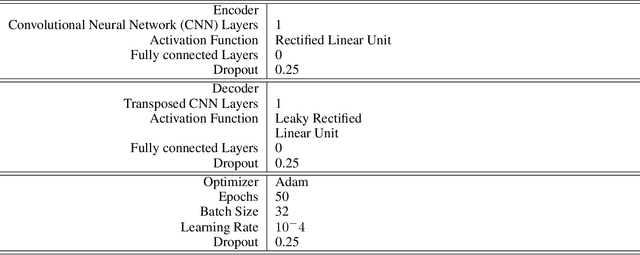
Intelligent Transportation Systems (ITS) underpin the concept of Mobility as a Service (MaaS), which requires universal and seamless users' access across multiple public and private transportation systems while allowing operators' proportional revenue sharing. Current user sensing technologies such as Walk-in/Walk-out (WIWO) and Check-in/Check-out (CICO) have limited scalability for large-scale deployments. These limitations prevent ITS from supporting analysis, optimization, calculation of revenue sharing, and control of MaaS comfort, safety, and efficiency. We focus on the concept of implicit Be-in/Be-out (BIBO) smartphone-sensing and classification. To close the gap and enhance smartphones towards MaaS, we developed a proprietary smartphone-sensing platform collecting contemporary Bluetooth Low Energy (BLE) signals from BLE devices installed on buses and Global Positioning System (GPS) locations of both buses and smartphones. To enable the training of a model based on GPS features against the BLE pseudo-label, we propose the Cause-Effect Multitask Wasserstein Autoencoder (CEMWA). CEMWA combines and extends several frameworks around Wasserstein autoencoders and neural networks. As a dimensionality reduction tool, CEMWA obtains an auto-validated representation of a latent space describing users' smartphones within the transport system. This representation allows BIBO clustering via DBSCAN. We perform an ablation study of CEMWA's alternative architectures and benchmark against the best available supervised methods. We analyze performance's sensitivity to label quality. Under the na\"ive assumption of accurate ground truth, XGBoost outperforms CEMWA. Although XGBoost and Random Forest prove to be tolerant to label noise, CEMWA is agnostic to label noise by design and provides the best performance with an 88\% F1 score.
"Is not the truth the truth?": Analyzing the Impact of User Validations for Bus In/Out Detection in Smartphone-based Surveys
Feb 24, 2022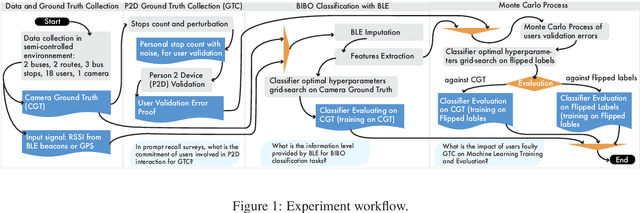
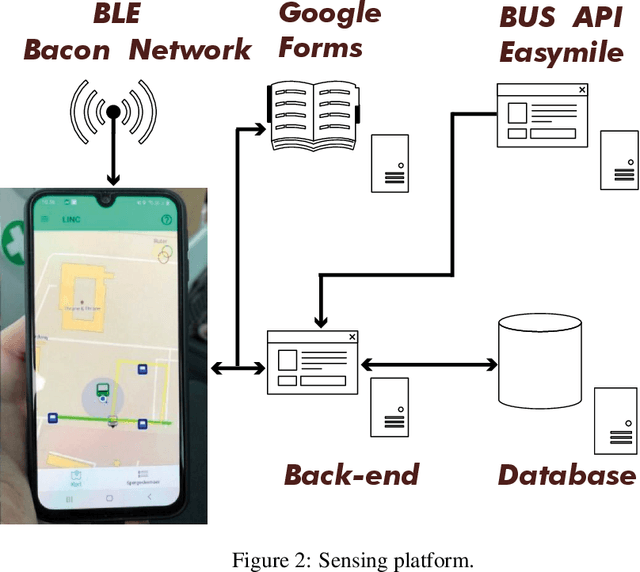
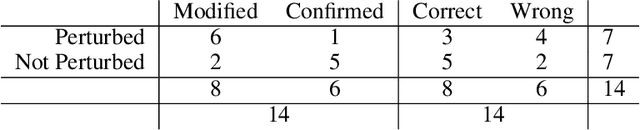
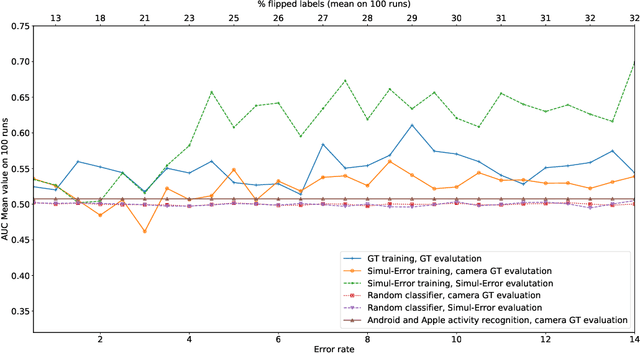
Passenger flow allows the study of users' behavior through the public network and assists in designing new facilities and services. This flow is observed through interactions between passengers and infrastructure. For this task, Bluetooth technology and smartphones represent the ideal solution. The latter component allows users' identification, authentication, and billing, while the former allows short-range implicit interactions, device-to-device. To assess the potential of such a use case, we need to verify how robust Bluetooth signal and related machine learning (ML) classifiers are against the noise of realistic contexts. Therefore, we model binary passenger states with respect to a public vehicle, where one can either be-in or be-out (BIBO). The BIBO label identifies a fundamental building block of continuously-valued passenger flow. This paper describes the Human-Computer interaction experimental setting in a semi-controlled environment, which involves: two autonomous vehicles operating on two routes, serving three bus stops and eighteen users, as well as a proprietary smartphone-Bluetooth sensing platform. The resulting dataset includes multiple sensors' measurements of the same event and two ground-truth levels, the first being validation by participants, the second by three video-cameras surveilling buses and track. We performed a Monte-Carlo simulation of labels-flip to emulate human errors in the labeling process, as is known to happen in smartphone surveys; next we used such flipped labels for supervised training of ML classifiers. The impact of errors on model performance bias can be large. Results show ML tolerance to label flips caused by human or machine errors up to 30%.
Unboxing the graph: Neural Relational Inference for Mobility Prediction
Jan 25, 2022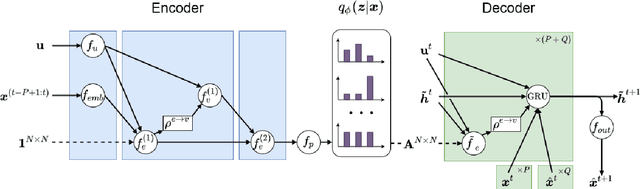
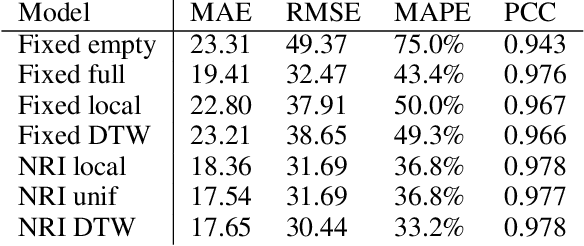
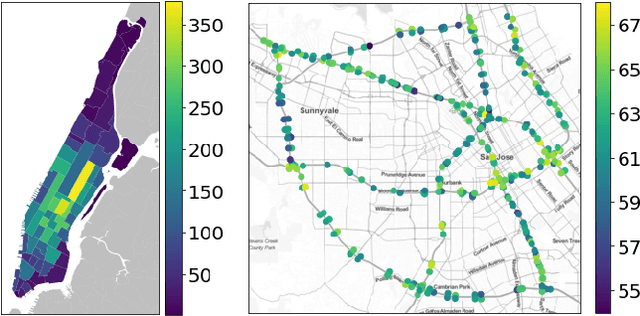
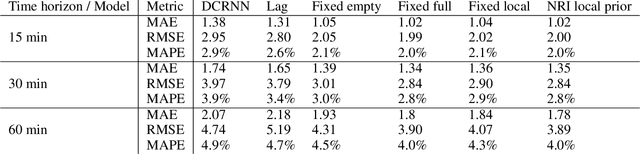
Predicting the supply and demand of transport systems is vital for efficient traffic management, control, optimization, and planning. For example, predicting where from/to and when people intend to travel by taxi can support fleet managers to distribute resources; better predicting traffic speeds/congestion allows for pro-active control measures or for users to better choose their paths. Making spatio-temporal predictions is known to be a hard task, but recently Graph Neural Networks (GNNs) have been widely applied on non-euclidean spatial data. However, most GNN models require a predefined graph, and so far, researchers rely on heuristics to generate this graph for the model to use. In this paper, we use Neural Relational Inference to learn the optimal graph for the model. Our approach has several advantages: 1) a Variational Auto Encoder structure allows for the graph to be dynamically determined by the data, potentially changing through time; 2) the encoder structure allows the use of external data in the generation of the graph; 3) it is possible to place Bayesian priors on the generated graphs to encode domain knowledge. We conduct experiments on two datasets, namely the NYC Yellow Taxi and the PEMS road traffic datasets. In both datasets, we outperform benchmarks and show performance comparable to state-of-the-art. Furthermore, we do an in-depth analysis of the learned graphs, providing insights on what kinds of connections GNNs use for spatio-temporal predictions in the transport domain.