 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Scene Video Deblurring using Non-Local Attention
Jan 01, 2022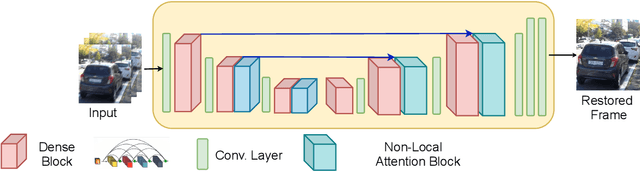
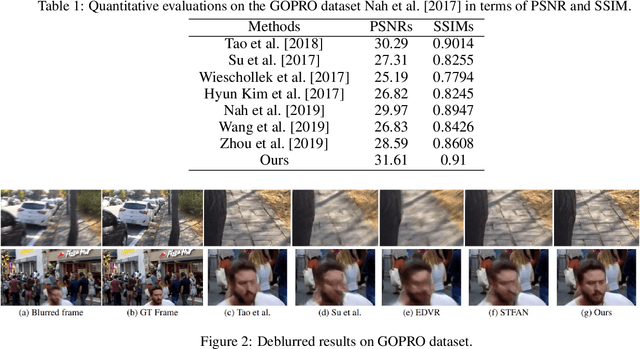
This paper tackles the challenging problem of video deblurring. Most of the existing works depend on implicit or explicit alignment for temporal information fusion which either increase the computational cost or result in suboptimal performance due to wrong alignment. In this study, we propose a factorized spatio-temporal attention to perform non-local operations across space and time to fully utilize the available information without depending on alignment. It shows superior performance compared to existing fusion techniques while being much efficient. Extensive experiments on multiple datasets demonstrate the superiority of our method.
Adaptive Single Image Deblurring
Jan 01, 2022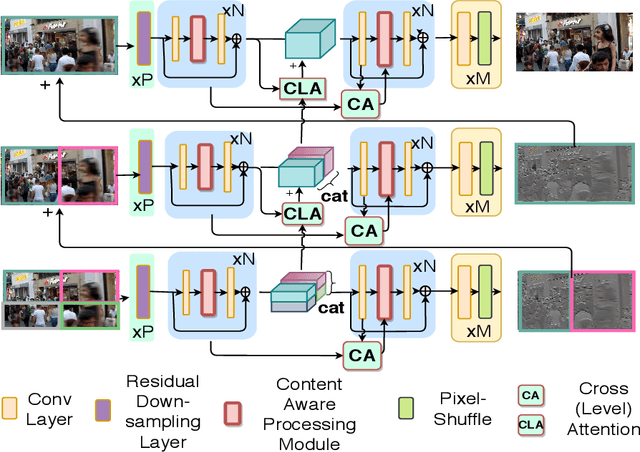
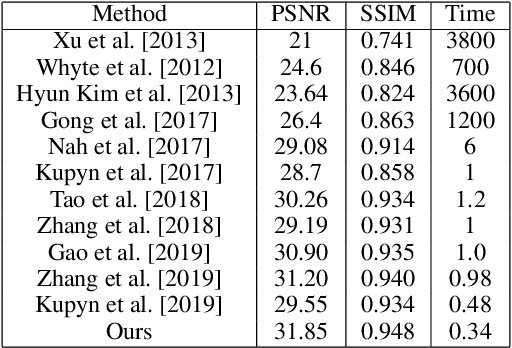

This paper tackles the problem of dynamic scene deblurring. Although end-to-end fully convolutional designs have recently advanced the state-of-the-art in non-uniform motion deblurring, their performance-complexity trade-off is still sub-optimal. Existing approaches achieve a large receptive field by a simple increment in the number of generic convolution layers, kernel-size, which comes with the burden of the increase in model size and inference speed. In this work, we propose an efficient pixel adaptive and feature attentive design for handling large blur variations within and across different images. We also propose an effective content-aware global-local filtering module that significantly improves the performance by considering not only the global dependencies of the pixel but also dynamically using the neighboring pixels. We use a patch hierarchical attentive architecture composed of the above module that implicitly discover the spatial variations in the blur present in the input image and in turn perform local and global modulation of intermediate features. Extensive qualitative and quantitative comparisons with prior art on deblurring benchmarks demonstrate the superiority of the proposed network.
Spatially-Adaptive Image Restoration using Distortion-Guided Networks
Aug 19, 2021
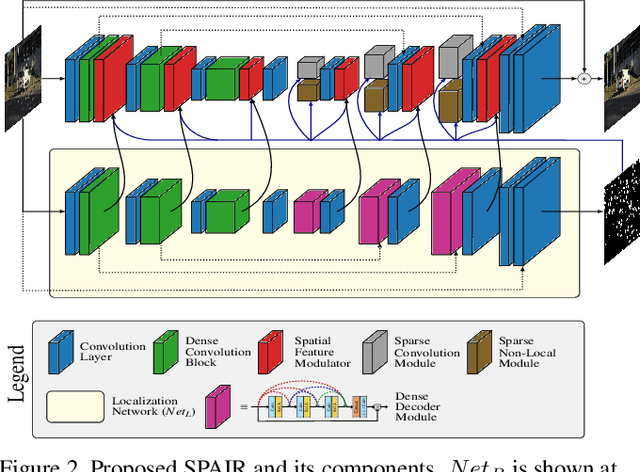
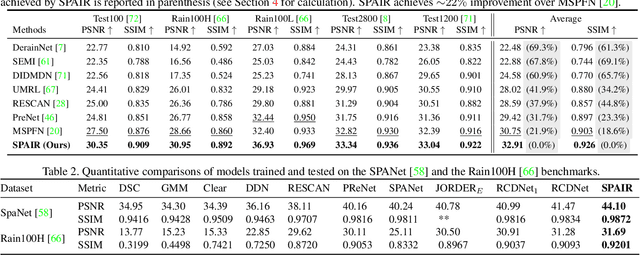
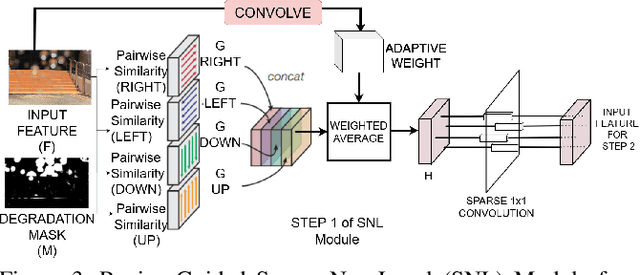
We present a general learning-based solution for restoring images suffering from spatially-varying degradations. Prior approaches are typically degradation-specific and employ the same processing across different images and different pixels within. However, we hypothesize that such spatially rigid processing is suboptimal for simultaneously restoring the degraded pixels as well as reconstructing the clean regions of the image. To overcome this limitation, we propose SPAIR, a network design that harnesses distortion-localization information and dynamically adjusts computation to difficult regions in the image. SPAIR comprises of two components, (1) a localization network that identifies degraded pixels, and (2) a restoration network that exploits knowledge from the localization network in filter and feature domain to selectively and adaptively restore degraded pixels. Our key idea is to exploit the non-uniformity of heavy degradations in spatial-domain and suitably embed this knowledge within distortion-guided modules performing sparse normalization, feature extraction and attention. Our architecture is agnostic to physical formation model and generalizes across several types of spatially-varying degradations. We demonstrate the efficacy of SPAIR individually on four restoration tasks-removal of rain-streaks, raindrops, shadows and motion blur. Extensive qualitative and quantitative comparisons with prior art on 11 benchmark datasets demonstrate that our degradation-agnostic network design offers significant performance gains over state-of-the-art degradation-specific architectures. Code available at https://github.com/human-analysis/spatially-adaptive-image-restoration.
AIM 2020 Challenge on Rendering Realistic Bokeh
Nov 10, 2020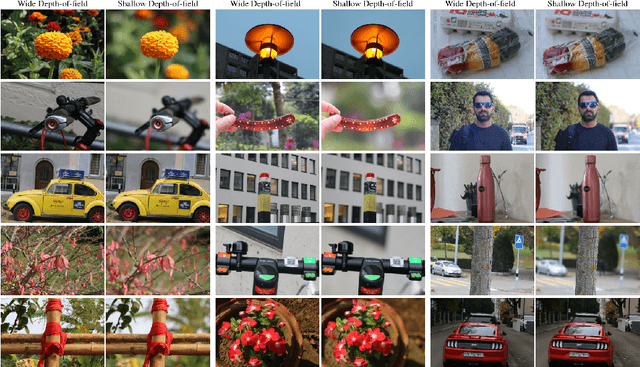


This paper reviews the second AIM realistic bokeh effect rendering challenge and provides the description of the proposed solutions and results. The participating teams were solving a real-world bokeh simulation problem, where the goal was to learn a realistic shallow focus technique using a large-scale EBB! bokeh dataset consisting of 5K shallow / wide depth-of-field image pairs captured using the Canon 7D DSLR camera. The participants had to render bokeh effect based on only one single frame without any additional data from other cameras or sensors. The target metric used in this challenge combined the runtime and the perceptual quality of the solutions measured in the user study. To ensure the efficiency of the submitted models, we measured their runtime on standard desktop CPUs as well as were running the models on smartphone GPUs. The proposed solutions significantly improved the baseline results, defining the state-of-the-art for practical bokeh effect rendering problem.
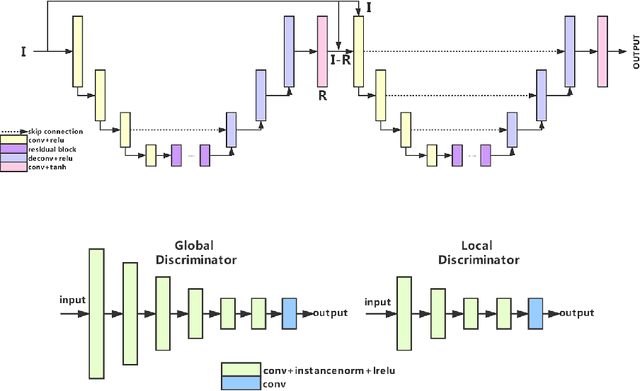
AIM 2020: Scene Relighting and Illumination Estimation Challenge
Sep 27, 2020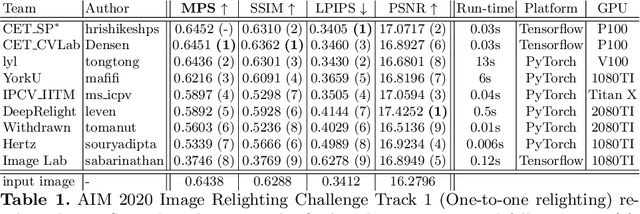

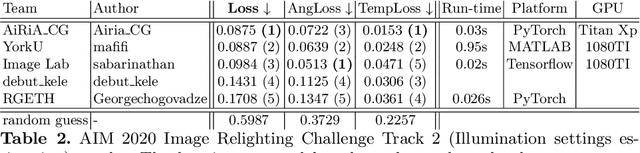

We review the AIM 2020 challenge on virtual image relighting and illumination estimation. This paper presents the novel VIDIT dataset used in the challenge and the different proposed solutions and final evaluation results over the 3 challenge tracks. The first track considered one-to-one relighting; the objective was to relight an input photo of a scene with a different color temperature and illuminant orientation (i.e., light source position). The goal of the second track was to estimate illumination settings, namely the color temperature and orientation, from a given image. Lastly, the third track dealt with any-to-any relighting, thus a generalization of the first track. The target color temperature and orientation, rather than being pre-determined, are instead given by a guide image. Participants were allowed to make use of their track 1 and 2 solutions for track 3. The tracks had 94, 52, and 56 registered participants, respectively, leading to 20 confirmed submissions in the final competition stage.
AIM 2020 Challenge on Efficient Super-Resolution: Methods and Results
Sep 15, 2020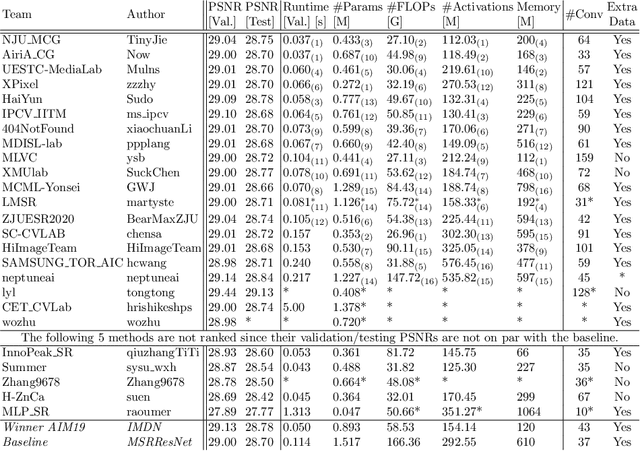
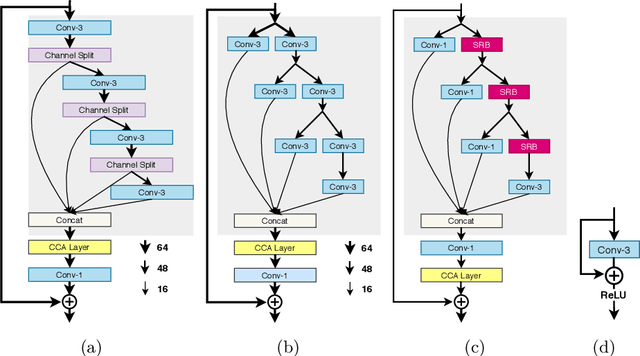
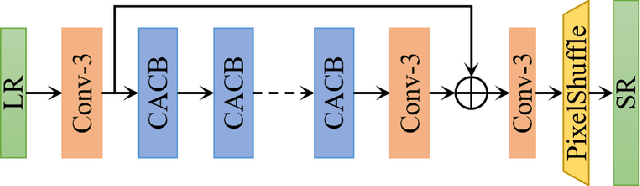
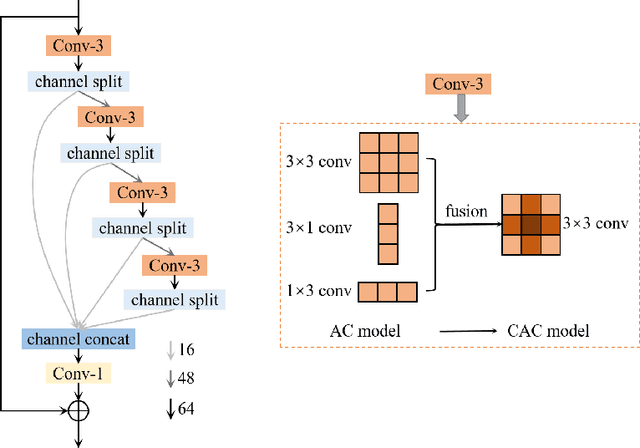
This paper reviews the AIM 2020 challenge on efficient single image super-resolution with focus on the proposed solutions and results. The challenge task was to super-resolve an input image with a magnification factor x4 based on a set of prior examples of low and corresponding high resolution images. The goal is to devise a network that reduces one or several aspects such as runtime, parameter count, FLOPs, activations, and memory consumption while at least maintaining PSNR of MSRResNet. The track had 150 registered participants, and 25 teams submitted the final results. They gauge the state-of-the-art in efficient single image super-resolution.
Spatially-Attentive Patch-Hierarchical Network for Adaptive Motion Deblurring
Apr 11, 2020
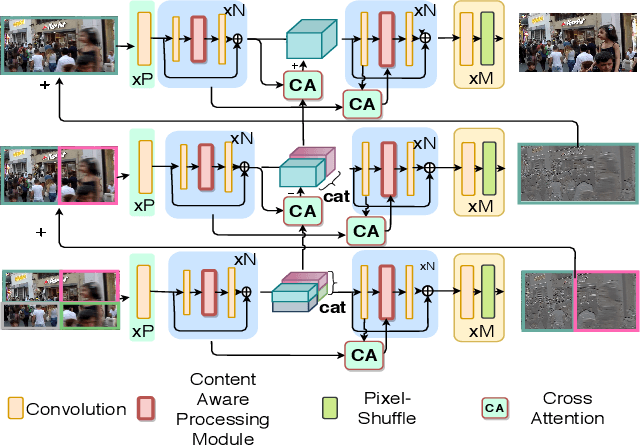

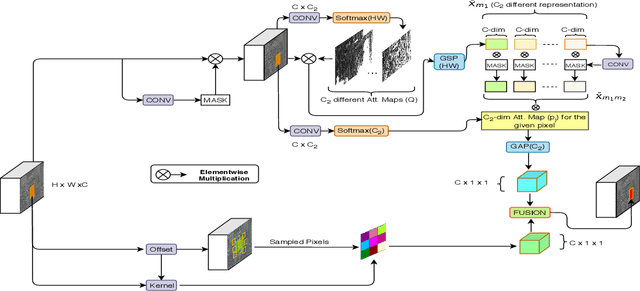
This paper tackles the problem of motion deblurring of dynamic scenes. Although end-to-end fully convolutional designs have recently advanced the state-of-the-art in non-uniform motion deblurring, their performance-complexity trade-off is still sub-optimal. Existing approaches achieve a large receptive field by increasing the number of generic convolution layers and kernel-size, but this comes at the expense of of the increase in model size and inference speed. In this work, we propose an efficient pixel adaptive and feature attentive design for handling large blur variations across different spatial locations and process each test image adaptively. We also propose an effective content-aware global-local filtering module that significantly improves performance by considering not only global dependencies but also by dynamically exploiting neighbouring pixel information. We use a patch-hierarchical attentive architecture composed of the above module that implicitly discovers the spatial variations in the blur present in the input image and in turn, performs local and global modulation of intermediate features. Extensive qualitative and quantitative comparisons with prior art on deblurring benchmarks demonstrate that our design offers significant improvements over the state-of-the-art in accuracy as well as speed.
AIM 2019 Challenge on Real-World Image Super-Resolution: Methods and Results
Nov 19, 2019
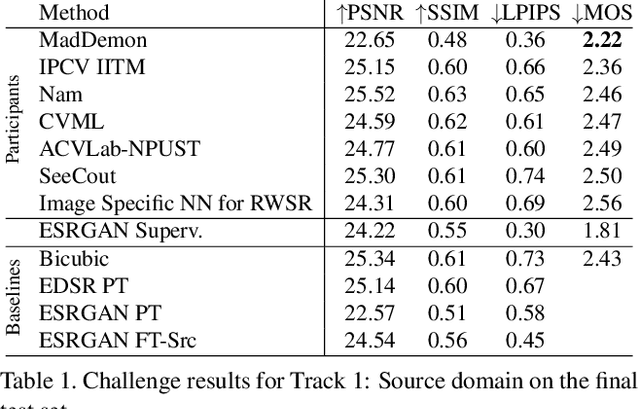
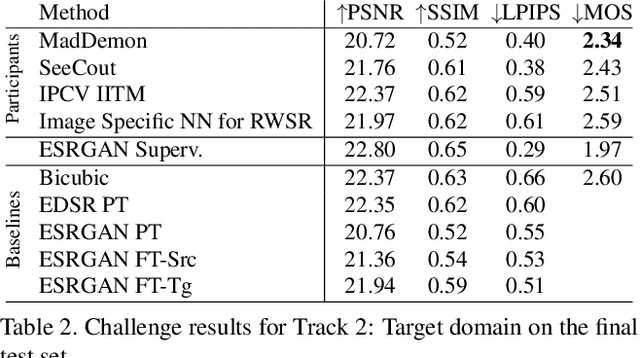

This paper reviews the AIM 2019 challenge on real world super-resolution. It focuses on the participating methods and final results. The challenge addresses the real world setting, where paired true high and low-resolution images are unavailable. For training, only one set of source input images is therefore provided in the challenge. In Track 1: Source Domain the aim is to super-resolve such images while preserving the low level image characteristics of the source input domain. In Track 2: Target Domain a set of high-quality images is also provided for training, that defines the output domain and desired quality of the super-resolved images. To allow for quantitative evaluation, the source input images in both tracks are constructed using artificial, but realistic, image degradations. The challenge is the first of its kind, aiming to advance the state-of-the-art and provide a standard benchmark for this newly emerging task. In total 7 teams competed in the final testing phase, demonstrating new and innovative solutions to the problem.
AIM 2019 Challenge on Image Demoireing: Methods and Results
Nov 08, 2019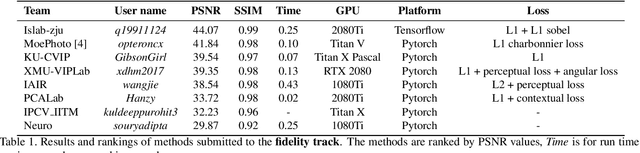
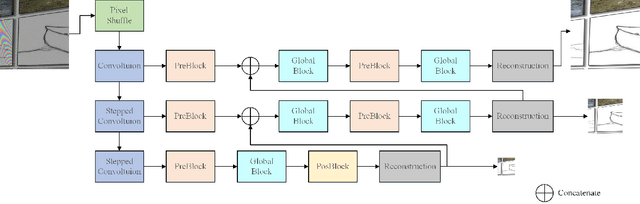
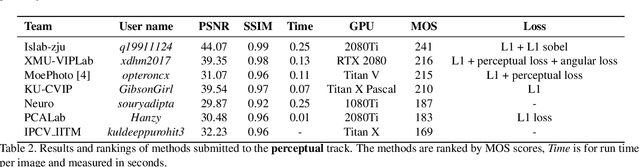
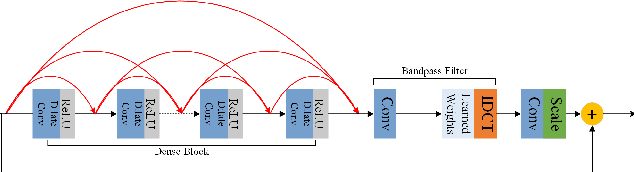
This paper reviews the first-ever image demoireing challenge that was part of the Advances in Image Manipulation (AIM) workshop, held in conjunction with ICCV 2019. This paper describes the challenge, and focuses on the proposed solutions and their results. Demoireing is a difficult task of removing moire patterns from an image to reveal an underlying clean image. A new dataset, called LCDMoire was created for this challenge, and consists of 10,200 synthetically generated image pairs (moire and clean ground truth). The challenge was divided into 2 tracks. Track 1 targeted fidelity, measuring the ability of demoire methods to obtain a moire-free image compared with the ground truth, while Track 2 examined the perceptual quality of demoire methods. The tracks had 60 and 39 registered participants, respectively. A total of eight teams competed in the final testing phase. The entries span the current the state-of-the-art in the image demoireing problem.