 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Context Adjustment Loss for Learned Image Compression
Oct 07, 2024



In recent years, learned image compression (LIC) technologies have surpassed conventional methods notably in terms of rate-distortion (RD) performance. Most present learned techniques are VAE-based with an autoregressive entropy model, which obviously promotes the RD performance by utilizing the decoded causal context. However, extant methods are highly dependent on the fixed hand-crafted causal context. The question of how to guide the auto-encoder to generate a more effective causal context benefit for the autoregressive entropy models is worth exploring. In this paper, we make the first attempt in investigating the way to explicitly adjust the causal context with our proposed Causal Context Adjustment loss (CCA-loss). By imposing the CCA-loss, we enable the neural network to spontaneously adjust important information into the early stage of the autoregressive entropy model. Furthermore, as transformer technology develops remarkably, variants of which have been adopted by many state-of-the-art (SOTA) LIC techniques. The existing computing devices have not adapted the calculation of the attention mechanism well, which leads to a burden on computation quantity and inference latency. To overcome it, we establish a convolutional neural network (CNN) image compression model and adopt the unevenly channel-wise grouped strategy for high efficiency. Ultimately, the proposed CNN-based LIC network trained with our Causal Context Adjustment loss attains a great trade-off between inference latency and rate-distortion performance.
NTIRE 2024 Challenge on Short-form UGC Video Quality Assessment: Methods and Results
Apr 17, 2024



This paper reviews the NTIRE 2024 Challenge on Shortform UGC Video Quality Assessment (S-UGC VQA), where various excellent solutions are submitted and evaluated on the collected dataset KVQ from popular short-form video platform, i.e., Kuaishou/Kwai Platform. The KVQ database is divided into three parts, including 2926 videos for training, 420 videos for validation, and 854 videos for testing. The purpose is to build new benchmarks and advance the development of S-UGC VQA. The competition had 200 participants and 13 teams submitted valid solutions for the final testing phase. The proposed solutions achieved state-of-the-art performances for S-UGC VQA. The project can be found at https://github.com/lixinustc/KVQChallenge-CVPR-NTIRE2024.
MarsQE: Semantic-Informed Quality Enhancement for Compressed Martian Image
Apr 15, 2024Lossy image compression is essential for Mars exploration missions, due to the limited bandwidth between Earth and Mars. However, the compression may introduce visual artifacts that complicate the geological analysis of the Martian surface. Existing quality enhancement approaches, primarily designed for Earth images, fall short for Martian images due to a lack of consideration for the unique Martian semantics. In response to this challenge, we conduct an in-depth analysis of Martian images, yielding two key insights based on semantics: the presence of texture similarities and the compact nature of texture representations in Martian images. Inspired by these findings, we introduce MarsQE, an innovative, semantic-informed, two-phase quality enhancement approach specifically designed for Martian images. The first phase involves the semantic-based matching of texture-similar reference images, and the second phase enhances image quality by transferring texture patterns from these reference images to the compressed image. We also develop a post-enhancement network to further reduce compression artifacts and achieve superior compression quality. Our extensive experiments demonstrate that MarsQE significantly outperforms existing approaches for Earth images, establishing a new benchmark for the quality enhancement on Martian images.
Enhancing Quality of Compressed Images by Mitigating Enhancement Bias Towards Compression Domain
Mar 10, 2024Existing quality enhancement methods for compressed images focus on aligning the enhancement domain with the raw domain to yield realistic images. However, these methods exhibit a pervasive enhancement bias towards the compression domain, inadvertently regarding it as more realistic than the raw domain. This bias makes enhanced images closely resemble their compressed counterparts, thus degrading their perceptual quality. In this paper, we propose a simple yet effective method to mitigate this bias and enhance the quality of compressed images. Our method employs a conditional discriminator with the compressed image as a key condition, and then incorporates a domain-divergence regularization to actively distance the enhancement domain from the compression domain. Through this dual strategy, our method enables the discrimination against the compression domain, and brings the enhancement domain closer to the raw domain. Comprehensive quality evaluations confirm the superiority of our method over other state-of-the-art methods without incurring inference overheads.
Uncertainty Guided Adaptive Warping for Robust and Efficient Stereo Matching
Jul 26, 2023Correlation based stereo matching has achieved outstanding performance, which pursues cost volume between two feature maps. Unfortunately, current methods with a fixed model do not work uniformly well across various datasets, greatly limiting their real-world applicability. To tackle this issue, this paper proposes a new perspective to dynamically calculate correlation for robust stereo matching. A novel Uncertainty Guided Adaptive Correlation (UGAC) module is introduced to robustly adapt the same model for different scenarios. Specifically, a variance-based uncertainty estimation is employed to adaptively adjust the sampling area during warping operation. Additionally, we improve the traditional non-parametric warping with learnable parameters, such that the position-specific weights can be learned. We show that by empowering the recurrent network with the UGAC module, stereo matching can be exploited more robustly and effectively. Extensive experiments demonstrate that our method achieves state-of-the-art performance over the ETH3D, KITTI, and Middlebury datasets when employing the same fixed model over these datasets without any retraining procedure. To target real-time applications, we further design a lightweight model based on UGAC, which also outperforms other methods over KITTI benchmarks with only 0.6 M parameters.
Blind Multimodal Quality Assessment: A Brief Survey and A Case Study of Low-light Images
Mar 18, 2023Blind image quality assessment (BIQA) aims at automatically and accurately forecasting objective scores for visual signals, which has been widely used to monitor product and service quality in low-light applications, covering smartphone photography, video surveillance, autonomous driving, etc. Recent developments in this field are dominated by unimodal solutions inconsistent with human subjective rating patterns, where human visual perception is simultaneously reflected by multiple sensory information (e.g., sight and hearing). In this article, we present a unique blind multimodal quality assessment (BMQA) of low-light images from subjective evaluation to objective score. To investigate the multimodal mechanism, we first establish a multimodal low-light image quality (MLIQ) database with authentic low-light distortions, containing image and audio modality pairs. Further, we specially design the key modules of BMQA, considering multimodal quality representation, latent feature alignment and fusion, and hybrid self-supervised and supervised learning. Extensive experiments show that our BMQA yields state-of-the-art accuracy on the proposed MLIQ benchmark database. In particular, we also build an independent single-image modality Dark-4K database, which is used to verify its applicability and generalization performance in mainstream unimodal applications. Qualitative and quantitative results on Dark-4K show that BMQA achieves superior performance to existing BIQA approaches as long as a pre-trained quality semantic description model is provided. The proposed framework and two databases as well as the collected BIQA methods and evaluation metrics are made publicly available.
DAQE: Enhancing the Quality of Compressed Images by Finding the Secret of Defocus
Nov 20, 2022



Image defocus is inherent in the physics of image formation caused by the optical aberration of lenses, providing plentiful information on image quality. Unfortunately, the existing quality enhancement approaches for compressed images neglect the inherent characteristic of defocus, resulting in inferior performance. This paper finds that in compressed images, the significantly defocused regions are with better compression quality and two regions with different defocus values possess diverse texture patterns. These findings motivate our defocus-aware quality enhancement (DAQE) approach. Specifically, we propose a novel dynamic region-based deep learning architecture of the DAQE approach, which considers the region-wise defocus difference of compressed images in two aspects. (1) The DAQE approach employs fewer computational resources to enhance the quality of significantly defocused regions, while more resources on enhancing the quality of other regions; (2) The DAQE approach learns to separately enhance diverse texture patterns for the regions with different defocus values, such that texture-wise one-on-one enhancement can be achieved. Extensive experiments validate the superiority of our DAQE approach in terms of quality enhancement and resource-saving, compared with other state-of-the-art approaches.
NTIRE 2022 Challenge on Super-Resolution and Quality Enhancement of Compressed Video: Dataset, Methods and Results
Apr 25, 2022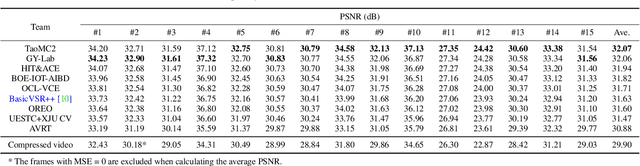
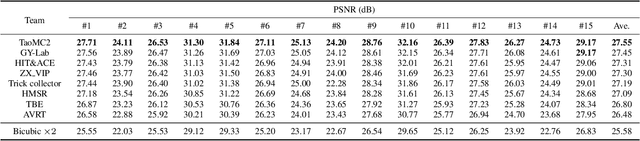

This paper reviews the NTIRE 2022 Challenge on Super-Resolution and Quality Enhancement of Compressed Video. In this challenge, we proposed the LDV 2.0 dataset, which includes the LDV dataset (240 videos) and 95 additional videos. This challenge includes three tracks. Track 1 aims at enhancing the videos compressed by HEVC at a fixed QP. Track 2 and Track 3 target both the super-resolution and quality enhancement of HEVC compressed video. They require x2 and x4 super-resolution, respectively. The three tracks totally attract more than 600 registrations. In the test phase, 8 teams, 8 teams and 12 teams submitted the final results to Tracks 1, 2 and 3, respectively. The proposed methods and solutions gauge the state-of-the-art of super-resolution and quality enhancement of compressed video. The proposed LDV 2.0 dataset is available at https://github.com/RenYang-home/LDV_dataset. The homepage of this challenge (including open-sourced codes) is at https://github.com/RenYang-home/NTIRE22_VEnh_SR.
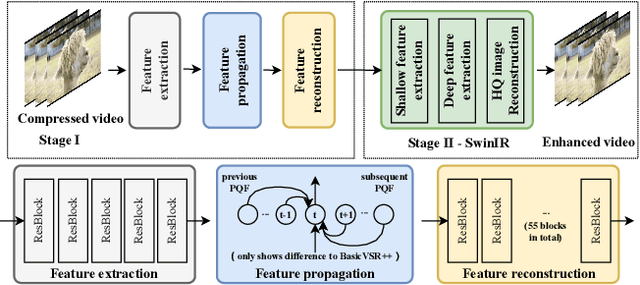
Progressive Training of A Two-Stage Framework for Video Restoration
Apr 21, 2022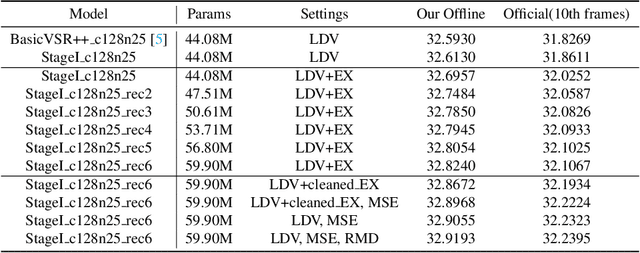
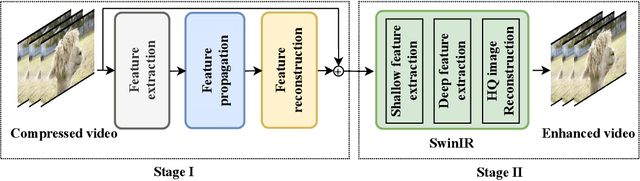
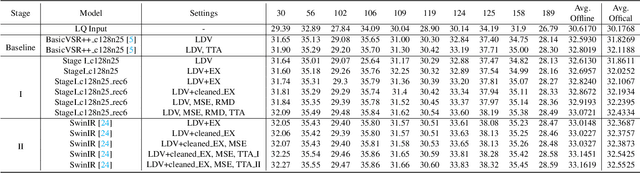
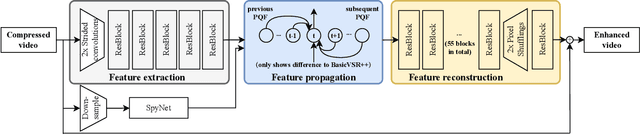
As a widely studied task, video restoration aims to enhance the quality of the videos with multiple potential degradations, such as noises, blurs and compression artifacts. Among video restorations, compressed video quality enhancement and video super-resolution are two of the main tacks with significant values in practical scenarios. Recently, recurrent neural networks and transformers attract increasing research interests in this field, due to their impressive capability in sequence-to-sequence modeling. However, the training of these models is not only costly but also relatively hard to converge, with gradient exploding and vanishing problems. To cope with these problems, we proposed a two-stage framework including a multi-frame recurrent network and a single-frame transformer. Besides, multiple training strategies, such as transfer learning and progressive training, are developed to shorten the training time and improve the model performance. Benefiting from the above technical contributions, our solution wins two champions and a runner-up in the NTIRE 2022 super-resolution and quality enhancement of compressed video challenges.
Blind VQA on 360° Video via Progressively Learning from Pixels, Frames and Video
Nov 18, 2021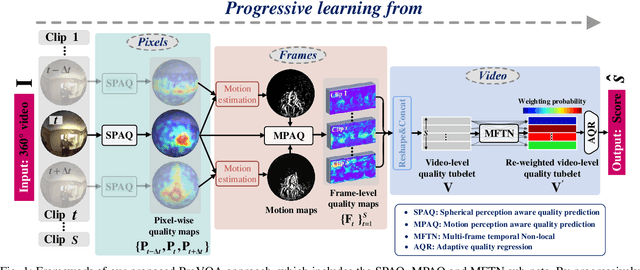
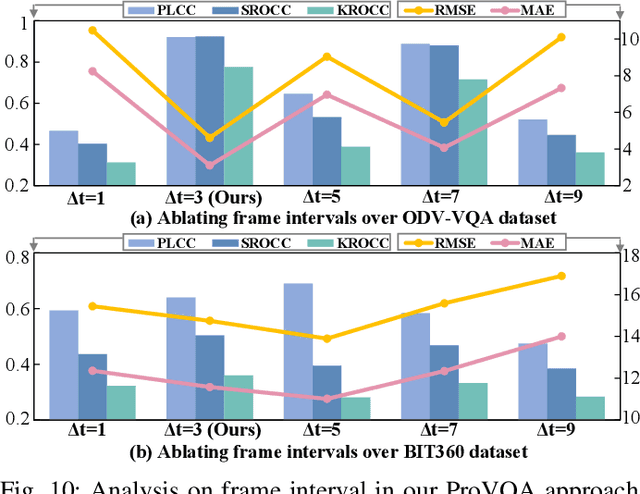
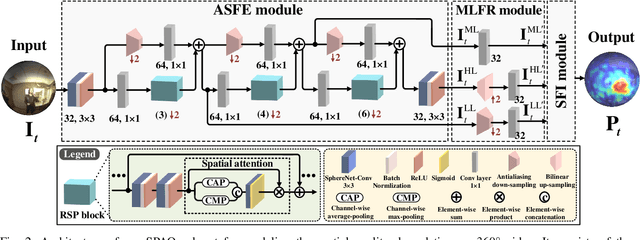
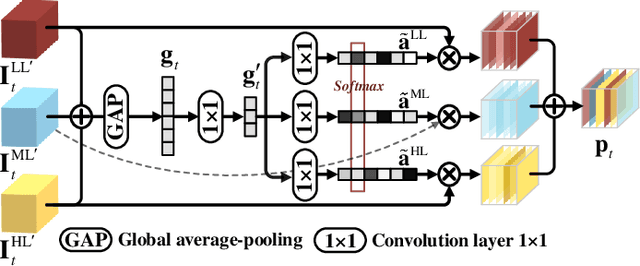
Blind visual quality assessment (BVQA) on 360{\textdegree} video plays a key role in optimizing immersive multimedia systems. When assessing the quality of 360{\textdegree} video, human tends to perceive its quality degradation from the viewport-based spatial distortion of each spherical frame to motion artifact across adjacent frames, ending with the video-level quality score, i.e., a progressive quality assessment paradigm. However, the existing BVQA approaches for 360{\textdegree} video neglect this paradigm. In this paper, we take into account the progressive paradigm of human perception towards spherical video quality, and thus propose a novel BVQA approach (namely ProVQA) for 360{\textdegree} video via progressively learning from pixels, frames and video. Corresponding to the progressive learning of pixels, frames and video, three sub-nets are designed in our ProVQA approach, i.e., the spherical perception aware quality prediction (SPAQ), motion perception aware quality prediction (MPAQ) and multi-frame temporal non-local (MFTN) sub-nets. The SPAQ sub-net first models the spatial quality degradation based on spherical perception mechanism of human. Then, by exploiting motion cues across adjacent frames, the MPAQ sub-net properly incorporates motion contextual information for quality assessment on 360{\textdegree} video. Finally, the MFTN sub-net aggregates multi-frame quality degradation to yield the final quality score, via exploring long-term quality correlation from multiple frames. The experiments validate that our approach significantly advances the state-of-the-art BVQA performance on 360{\textdegree} video over two datasets, the code of which has been public in \url{https://github.com/yanglixiaoshen/ProVQA.}