 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Robust Sequential Recommenders through Confident Soft Labels
Nov 04, 2023Sequential recommenders that are trained on implicit feedback are usually learned as a multi-class classification task through softmax-based loss functions on one-hot class labels. However, one-hot training labels are sparse and may lead to biased training and sub-optimal performance. Dense, soft labels have been shown to help improve recommendation performance. But how to generate high-quality and confident soft labels from noisy sequential interactions between users and items is still an open question. We propose a new learning framework for sequential recommenders, CSRec, which introduces confident soft labels to provide robust guidance when learning from user-item interactions. CSRec contains a teacher module that generates high-quality and confident soft labels and a student module that acts as the target recommender and is trained on the combination of dense, soft labels and sparse, one-hot labels. We propose and compare three approaches to constructing the teacher module: (i) model-level, (ii) data-level, and (iii) training-level. To evaluate the effectiveness and generalization ability of CSRec, we conduct experiments using various state-of-the-art sequential recommendation models as the target student module on four benchmark datasets. Our experimental results demonstrate that CSRec is effective in training better performing sequential recommenders.
From Relevance to Utility: Evidence Retrieval with Feedback for Fact Verification
Oct 20, 2023Retrieval-enhanced methods have become a primary approach in fact verification (FV); it requires reasoning over multiple retrieved pieces of evidence to verify the integrity of a claim. To retrieve evidence, existing work often employs off-the-shelf retrieval models whose design is based on the probability ranking principle. We argue that, rather than relevance, for FV we need to focus on the utility that a claim verifier derives from the retrieved evidence. We introduce the feedback-based evidence retriever(FER) that optimizes the evidence retrieval process by incorporating feedback from the claim verifier. As a feedback signal we use the divergence in utility between how effectively the verifier utilizes the retrieved evidence and the ground-truth evidence to produce the final claim label. Empirical studies demonstrate the superiority of FER over prevailing baselines.
Hierarchical Forecasting at Scale
Oct 19, 2023Existing hierarchical forecasting techniques scale poorly when the number of time series increases. We propose to learn a coherent forecast for millions of time series with a single bottom-level forecast model by using a sparse loss function that directly optimizes the hierarchical product and/or temporal structure. The benefit of our sparse hierarchical loss function is that it provides practitioners a method of producing bottom-level forecasts that are coherent to any chosen cross-sectional or temporal hierarchy. In addition, removing the need for a post-processing step as required in traditional hierarchical forecasting techniques reduces the computational cost of the prediction phase in the forecasting pipeline. On the public M5 dataset, our sparse hierarchical loss function performs up to 10% (RMSE) better compared to the baseline loss function. We implement our sparse hierarchical loss function within an existing forecasting model at bol, a large European e-commerce platform, resulting in an improved forecasting performance of 2% at the product level. Finally, we found an increase in forecasting performance of about 5-10% when evaluating the forecasting performance across the cross-sectional hierarchies that we defined. These results demonstrate the usefulness of our sparse hierarchical loss applied to a production forecasting system at a major e-commerce platform.
Generalizing Few-Shot Named Entity Recognizers to Unseen Domains with Type-Related Features
Oct 15, 2023



Few-shot named entity recognition (NER) has shown remarkable progress in identifying entities in low-resource domains. However, few-shot NER methods still struggle with out-of-domain (OOD) examples due to their reliance on manual labeling for the target domain. To address this limitation, recent studies enable generalization to an unseen target domain with only a few labeled examples using data augmentation techniques. Two important challenges remain: First, augmentation is limited to the training data, resulting in minimal overlap between the generated data and OOD examples. Second, knowledge transfer is implicit and insufficient, severely hindering model generalizability and the integration of knowledge from the source domain. In this paper, we propose a framework, prompt learning with type-related features (PLTR), to address these challenges. To identify useful knowledge in the source domain and enhance knowledge transfer, PLTR automatically extracts entity type-related features (TRFs) based on mutual information criteria. To bridge the gap between training and OOD data, PLTR generates a unique prompt for each unseen example by selecting relevant TRFs. We show that PLTR achieves significant performance improvements on in-domain and cross-domain datasets. The use of PLTR facilitates model adaptation and increases representation similarities between the source and unseen domains.
Predictive Uncertainty-based Bias Mitigation in Ranking
Sep 18, 2023



Societal biases that are contained in retrieved documents have received increased interest. Such biases, which are often prevalent in the training data and learned by the model, can cause societal harms, by misrepresenting certain groups, and by enforcing stereotypes. Mitigating such biases demands algorithms that balance the trade-off between maximized utility for the user with fairness objectives, which incentivize unbiased rankings. Prior work on bias mitigation often assumes that ranking scores, which correspond to the utility that a document holds for a user, can be accurately determined. In reality, there is always a degree of uncertainty in the estimate of expected document utility. This uncertainty can be approximated by viewing ranking models through a Bayesian perspective, where the standard deterministic score becomes a distribution. In this work, we investigate whether uncertainty estimates can be used to decrease the amount of bias in the ranked results, while minimizing loss in measured utility. We introduce a simple method that uses the uncertainty of the ranking scores for an uncertainty-aware, post hoc approach to bias mitigation. We compare our proposed method with existing baselines for bias mitigation with respect to the utility-fairness trade-off, the controllability of methods, and computational costs. We show that an uncertainty-based approach can provide an intuitive and flexible trade-off that outperforms all baselines without additional training requirements, allowing for the post hoc use of this approach on top of arbitrary retrieval models.
Continual Learning for Generative Retrieval over Dynamic Corpora
Aug 29, 2023



Generative retrieval (GR) directly predicts the identifiers of relevant documents (i.e., docids) based on a parametric model. It has achieved solid performance on many ad-hoc retrieval tasks. So far, these tasks have assumed a static document collection. In many practical scenarios, however, document collections are dynamic, where new documents are continuously added to the corpus. The ability to incrementally index new documents while preserving the ability to answer queries with both previously and newly indexed relevant documents is vital to applying GR models. In this paper, we address this practical continual learning problem for GR. We put forward a novel Continual-LEarner for generatiVE Retrieval (CLEVER) model and make two major contributions to continual learning for GR: (i) To encode new documents into docids with low computational cost, we present Incremental Product Quantization, which updates a partial quantization codebook according to two adaptive thresholds; and (ii) To memorize new documents for querying without forgetting previous knowledge, we propose a memory-augmented learning mechanism, to form meaningful connections between old and new documents. Empirical results demonstrate the effectiveness and efficiency of the proposed model.
Black-box Adversarial Attacks against Dense Retrieval Models: A Multi-view Contrastive Learning Method
Aug 19, 2023Neural ranking models (NRMs) and dense retrieval (DR) models have given rise to substantial improvements in overall retrieval performance. In addition to their effectiveness, and motivated by the proven lack of robustness of deep learning-based approaches in other areas, there is growing interest in the robustness of deep learning-based approaches to the core retrieval problem. Adversarial attack methods that have so far been developed mainly focus on attacking NRMs, with very little attention being paid to the robustness of DR models. In this paper, we introduce the adversarial retrieval attack (AREA) task. The AREA task is meant to trick DR models into retrieving a target document that is outside the initial set of candidate documents retrieved by the DR model in response to a query. We consider the decision-based black-box adversarial setting, which is realistic in real-world search engines. To address the AREA task, we first employ existing adversarial attack methods designed for NRMs. We find that the promising results that have previously been reported on attacking NRMs, do not generalize to DR models: these methods underperform a simple term spamming method. We attribute the observed lack of generalizability to the interaction-focused architecture of NRMs, which emphasizes fine-grained relevance matching. DR models follow a different representation-focused architecture that prioritizes coarse-grained representations. We propose to formalize attacks on DR models as a contrastive learning problem in a multi-view representation space. The core idea is to encourage the consistency between each view representation of the target document and its corresponding viewer via view-wise supervision signals. Experimental results demonstrate that the proposed method can significantly outperform existing attack strategies in misleading the DR model with small indiscernible text perturbations.
Group Membership Bias
Aug 05, 2023



When learning to rank from user interactions, search and recommendation systems must address biases in user behavior to provide a high-quality ranking. One type of bias that has recently been studied in the ranking literature is when sensitive attributes, such as gender, have an impact on a user's judgment about an item's utility. For example, in a search for an expertise area, some users may be biased towards clicking on male candidates over female candidates. We call this type of bias group membership bias or group bias for short. Increasingly, we seek rankings that not only have high utility but are also fair to individuals and sensitive groups. Merit-based fairness measures rely on the estimated merit or utility of the items. With group bias, the utility of the sensitive groups is under-estimated, hence, without correcting for this bias, a supposedly fair ranking is not truly fair. In this paper, first, we analyze the impact of group bias on ranking quality as well as two well-known merit-based fairness metrics and show that group bias can hurt both ranking and fairness. Then, we provide a correction method for group bias that is based on the assumption that the utility score of items in different groups comes from the same distribution. This assumption has two potential issues of sparsity and equality-instead-of-equity, which we use an amortized approach to solve. We show that our correction method can consistently compensate for the negative impact of group bias on ranking quality and fairness metrics.
Masked and Swapped Sequence Modeling for Next Novel Basket Recommendation in Grocery Shopping
Aug 02, 2023



Next basket recommendation (NBR) is the task of predicting the next set of items based on a sequence of already purchased baskets. It is a recommendation task that has been widely studied, especially in the context of grocery shopping. In next basket recommendation (NBR), it is useful to distinguish between repeat items, i.e., items that a user has consumed before, and explore items, i.e., items that a user has not consumed before. Most NBR work either ignores this distinction or focuses on repeat items. We formulate the next novel basket recommendation (NNBR) task, i.e., the task of recommending a basket that only consists of novel items, which is valuable for both real-world application and NBR evaluation. We evaluate how existing NBR methods perform on the NNBR task and find that, so far, limited progress has been made w.r.t. the NNBR task. To address the NNBR task, we propose a simple bi-directional transformer basket recommendation model (BTBR), which is focused on directly modeling item-to-item correlations within and across baskets instead of learning complex basket representations. To properly train BTBR, we propose and investigate several masking strategies and training objectives: (i) item-level random masking, (ii) item-level select masking, (iii) basket-level all masking, (iv) basket-level explore masking, and (v) joint masking. In addition, an item-basket swapping strategy is proposed to enrich the item interactions within the same baskets. We conduct extensive experiments on three open datasets with various characteristics. The results demonstrate the effectiveness of BTBR and our masking and swapping strategies for the NNBR task. BTBR with a properly selected masking and swapping strategy can substantially improve NNBR performance.
Answering Ambiguous Questions via Iterative Prompting
Jul 08, 2023

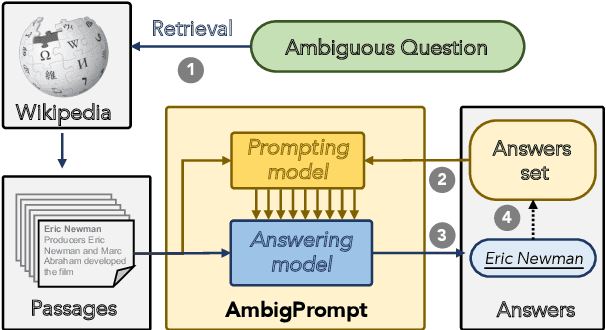

In open-domain question answering, due to the ambiguity of questions, multiple plausible answers may exist. To provide feasible answers to an ambiguous question, one approach is to directly predict all valid answers, but this can struggle with balancing relevance and diversity. An alternative is to gather candidate answers and aggregate them, but this method can be computationally costly and may neglect dependencies among answers. In this paper, we present AmbigPrompt to address the imperfections of existing approaches to answering ambiguous questions. Specifically, we integrate an answering model with a prompting model in an iterative manner. The prompting model adaptively tracks the reading process and progressively triggers the answering model to compose distinct and relevant answers. Additionally, we develop a task-specific post-pretraining approach for both the answering model and the prompting model, which greatly improves the performance of our framework. Empirical studies on two commonly-used open benchmarks show that AmbigPrompt achieves state-of-the-art or competitive results while using less memory and having a lower inference latency than competing approaches. Additionally, AmbigPrompt also performs well in low-resource settings. The code are available at: https://github.com/sunnweiwei/AmbigPrompt.