 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClaw-Anything: Benchmarking Always-On Personal Assistants with Broader Access to User's Digital World
May 25, 2026Large language model agents are increasingly envisioned as always-on personal assistants with access to anything relevant in the user's digital world. Yet current systems operate over only narrow slices of that world, limiting context-sensitive reasoning and effective assistance. Existing benchmarks similarly provide only partial user state and therefore fail to capture performance in such a broad, always-on setting. To address this gap, we introduce Claw-Anything, a benchmark that expands agent context along three dimensions: long-horizon activity histories, interdependent backend services, and integrated GUI and CLI interaction across multiple devices. To instantiate this setting, we simulate months of user activity through multi-round event injection, producing complex world states and realistic noise, including irrelevant events and conflicting signals. Agents must reason over rich contextual environments while remaining robust to such noise. This expanded scope also enables the evaluation of proactive assistance, requiring agents to anticipate user needs and deliver timely recommendations. Experiments show that GPT-5.5 achieves only 34.5% pass@1, substantially below prior benchmarks, underscoring a gap between current agent capabilities and the demands of always-on personal assistance. Alongside the benchmark, we release an automated data-generation pipeline that yields 2,000 training environments and improves the base model by 23.7%, demonstrating its utility of scalable data infrastructure.
CorpusBrain++: A Continual Generative Pre-Training Framework for Knowledge-Intensive Language Tasks
Feb 26, 2024



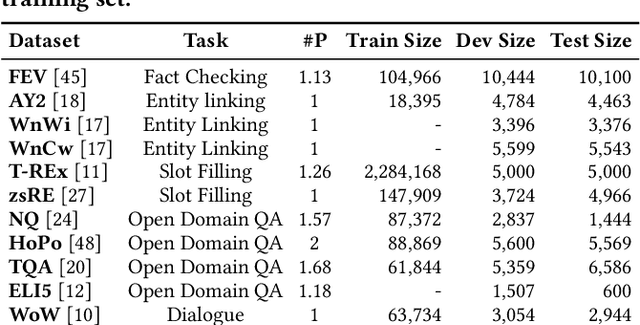
Knowledge-intensive language tasks (KILTs) typically require retrieving relevant documents from trustworthy corpora, e.g., Wikipedia, to produce specific answers. Very recently, a pre-trained generative retrieval model for KILTs, named CorpusBrain, was proposed and reached new state-of-the-art retrieval performance. However, most existing research on KILTs, including CorpusBrain, has predominantly focused on a static document collection, overlooking the dynamic nature of real-world scenarios, where new documents are continuously being incorporated into the source corpus. To address this gap, it is crucial to explore the capability of retrieval models to effectively handle the dynamic retrieval scenario inherent in KILTs. In this work, we first introduce the continual document learning (CDL) task for KILTs and build a novel benchmark dataset named KILT++ based on the original KILT dataset for evaluation. Then, we conduct a comprehensive study over the use of pre-trained CorpusBrain on KILT++. Unlike the promising results in the stationary scenario, CorpusBrain is prone to catastrophic forgetting in the dynamic scenario, hence hampering the retrieval performance. To alleviate this issue, we propose CorpusBrain++, a continual generative pre-training framework. Empirical results demonstrate the significant effectiveness and remarkable efficiency of CorpusBrain++ in comparison to both traditional and generative IR methods.
RIGHT: Retrieval-augmented Generation for Mainstream Hashtag Recommendation
Dec 16, 2023



Automatic mainstream hashtag recommendation aims to accurately provide users with concise and popular topical hashtags before publication. Generally, mainstream hashtag recommendation faces challenges in the comprehensive difficulty of newly posted tweets in response to new topics, and the accurate identification of mainstream hashtags beyond semantic correctness. However, previous retrieval-based methods based on a fixed predefined mainstream hashtag list excel in producing mainstream hashtags, but fail to understand the constant flow of up-to-date information. Conversely, generation-based methods demonstrate a superior ability to comprehend newly posted tweets, but their capacity is constrained to identifying mainstream hashtags without additional features. Inspired by the recent success of the retrieval-augmented technique, in this work, we attempt to adopt this framework to combine the advantages of both approaches. Meantime, with the help of the generator component, we could rethink how to further improve the quality of the retriever component at a low cost. Therefore, we propose RetrIeval-augmented Generative Mainstream HashTag Recommender (RIGHT), which consists of three components: 1) a retriever seeks relevant hashtags from the entire tweet-hashtags set; 2) a selector enhances mainstream identification by introducing global signals; and 3) a generator incorporates input tweets and selected hashtags to directly generate the desired hashtags. The experimental results show that our method achieves significant improvements over state-of-the-art baselines. Moreover, RIGHT can be easily integrated into large language models, improving the performance of ChatGPT by more than 10%.
Continual Learning for Generative Retrieval over Dynamic Corpora
Aug 29, 2023



Generative retrieval (GR) directly predicts the identifiers of relevant documents (i.e., docids) based on a parametric model. It has achieved solid performance on many ad-hoc retrieval tasks. So far, these tasks have assumed a static document collection. In many practical scenarios, however, document collections are dynamic, where new documents are continuously added to the corpus. The ability to incrementally index new documents while preserving the ability to answer queries with both previously and newly indexed relevant documents is vital to applying GR models. In this paper, we address this practical continual learning problem for GR. We put forward a novel Continual-LEarner for generatiVE Retrieval (CLEVER) model and make two major contributions to continual learning for GR: (i) To encode new documents into docids with low computational cost, we present Incremental Product Quantization, which updates a partial quantization codebook according to two adaptive thresholds; and (ii) To memorize new documents for querying without forgetting previous knowledge, we propose a memory-augmented learning mechanism, to form meaningful connections between old and new documents. Empirical results demonstrate the effectiveness and efficiency of the proposed model.
Semantic-Enhanced Differentiable Search Index Inspired by Learning Strategies
May 24, 2023



Recently, a new paradigm called Differentiable Search Index (DSI) has been proposed for document retrieval, wherein a sequence-to-sequence model is learned to directly map queries to relevant document identifiers. The key idea behind DSI is to fully parameterize traditional ``index-retrieve'' pipelines within a single neural model, by encoding all documents in the corpus into the model parameters. In essence, DSI needs to resolve two major questions: (1) how to assign an identifier to each document, and (2) how to learn the associations between a document and its identifier. In this work, we propose a Semantic-Enhanced DSI model (SE-DSI) motivated by Learning Strategies in the area of Cognitive Psychology. Our approach advances original DSI in two ways: (1) For the document identifier, we take inspiration from Elaboration Strategies in human learning. Specifically, we assign each document an Elaborative Description based on the query generation technique, which is more meaningful than a string of integers in the original DSI; and (2) For the associations between a document and its identifier, we take inspiration from Rehearsal Strategies in human learning. Specifically, we select fine-grained semantic features from a document as Rehearsal Contents to improve document memorization. Both the offline and online experiments show improved retrieval performance over prevailing baselines.
A Unified Generative Retriever for Knowledge-Intensive Language Tasks via Prompt Learning
Apr 28, 2023



Knowledge-intensive language tasks (KILTs) benefit from retrieving high-quality relevant contexts from large external knowledge corpora. Learning task-specific retrievers that return relevant contexts at an appropriate level of semantic granularity, such as a document retriever, passage retriever, sentence retriever, and entity retriever, may help to achieve better performance on the end-to-end task. But a task-specific retriever usually has poor generalization ability to new domains and tasks, and it may be costly to deploy a variety of specialised retrievers in practice. We propose a unified generative retriever (UGR) that combines task-specific effectiveness with robust performance over different retrieval tasks in KILTs. To achieve this goal, we make two major contributions: (i) To unify different retrieval tasks into a single generative form, we introduce an n-gram-based identifier for relevant contexts at different levels of granularity in KILTs. And (ii) to address different retrieval tasks with a single model, we employ a prompt learning strategy and investigate three methods to design prompt tokens for each task. In this way, the proposed UGR model can not only share common knowledge across tasks for better generalization, but also perform different retrieval tasks effectively by distinguishing task-specific characteristics. We train UGR on a heterogeneous set of retrieval corpora with well-designed prompts in a supervised and multi-task fashion. Experimental results on the KILT benchmark demonstrate the effectiveness of UGR on in-domain datasets, out-of-domain datasets, and unseen tasks.
CorpusBrain: Pre-train a Generative Retrieval Model for Knowledge-Intensive Language Tasks
Aug 16, 2022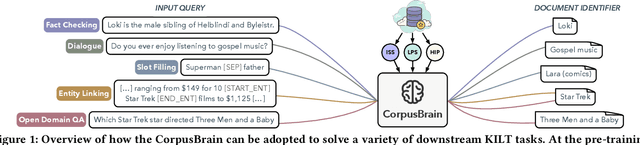

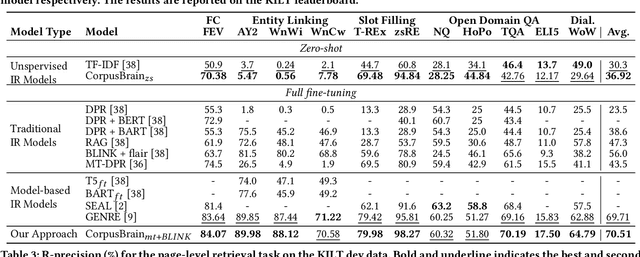
Knowledge-intensive language tasks (KILT) usually require a large body of information to provide correct answers. A popular paradigm to solve this problem is to combine a search system with a machine reader, where the former retrieves supporting evidences and the latter examines them to produce answers. Recently, the reader component has witnessed significant advances with the help of large-scale pre-trained generative models. Meanwhile most existing solutions in the search component rely on the traditional ``index-retrieve-then-rank'' pipeline, which suffers from large memory footprint and difficulty in end-to-end optimization. Inspired by recent efforts in constructing model-based IR models, we propose to replace the traditional multi-step search pipeline with a novel single-step generative model, which can dramatically simplify the search process and be optimized in an end-to-end manner. We show that a strong generative retrieval model can be learned with a set of adequately designed pre-training tasks, and be adopted to improve a variety of downstream KILT tasks with further fine-tuning. We name the pre-trained generative retrieval model as CorpusBrain as all information about the corpus is encoded in its parameters without the need of constructing additional index. Empirical results show that CorpusBrain can significantly outperform strong baselines for the retrieval task on the KILT benchmark and establish new state-of-the-art downstream performances. We also show that CorpusBrain works well under zero- and low-resource settings.
GERE: Generative Evidence Retrieval for Fact Verification
Apr 22, 2022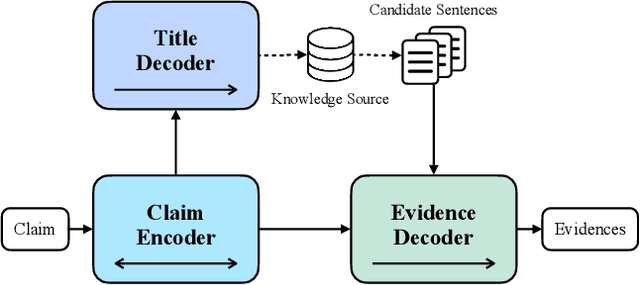
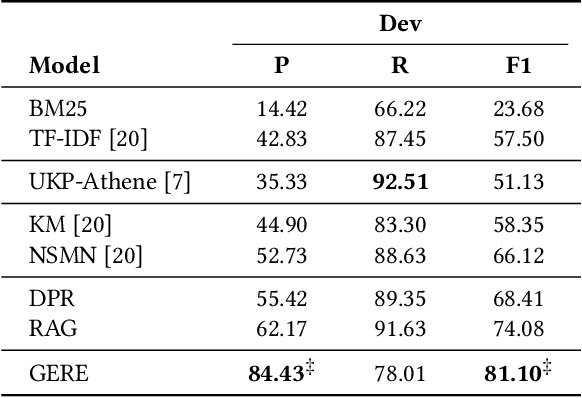
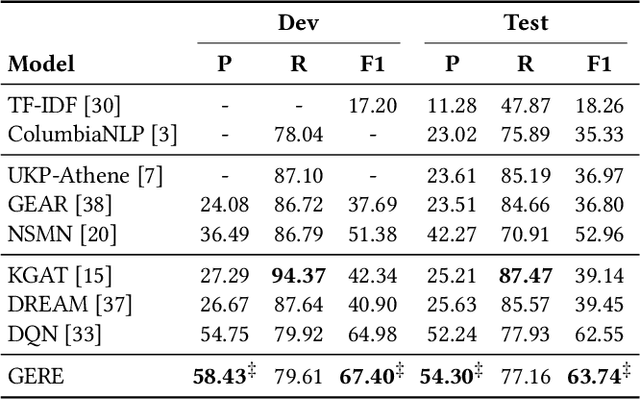
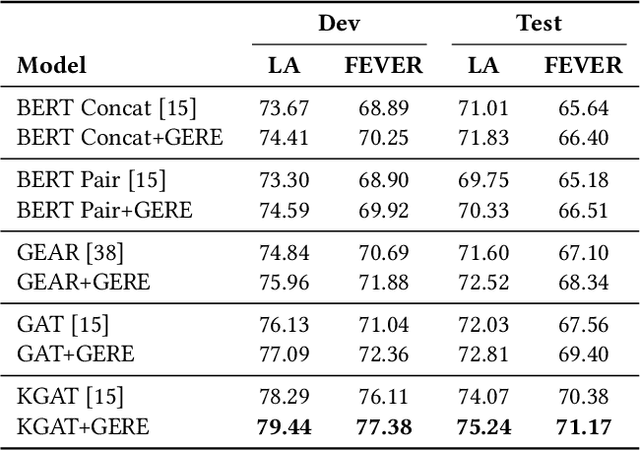
Fact verification (FV) is a challenging task which aims to verify a claim using multiple evidential sentences from trustworthy corpora, e.g., Wikipedia. Most existing approaches follow a three-step pipeline framework, including document retrieval, sentence retrieval and claim verification. High-quality evidences provided by the first two steps are the foundation of the effective reasoning in the last step. Despite being important, high-quality evidences are rarely studied by existing works for FV, which often adopt the off-the-shelf models to retrieve relevant documents and sentences in an "index-retrieve-then-rank" fashion. This classical approach has clear drawbacks as follows: i) a large document index as well as a complicated search process is required, leading to considerable memory and computational overhead; ii) independent scoring paradigms fail to capture the interactions among documents and sentences in ranking; iii) a fixed number of sentences are selected to form the final evidence set. In this work, we propose GERE, the first system that retrieves evidences in a generative fashion, i.e., generating the document titles as well as evidence sentence identifiers. This enables us to mitigate the aforementioned technical issues since: i) the memory and computational cost is greatly reduced because the document index is eliminated and the heavy ranking process is replaced by a light generative process; ii) the dependency between documents and that between sentences could be captured via sequential generation process; iii) the generative formulation allows us to dynamically select a precise set of relevant evidences for each claim. The experimental results on the FEVER dataset show that GERE achieves significant improvements over the state-of-the-art baselines, with both time-efficiency and memory-efficiency.
FedMatch: Federated Learning Over Heterogeneous Question Answering Data
Sep 06, 2021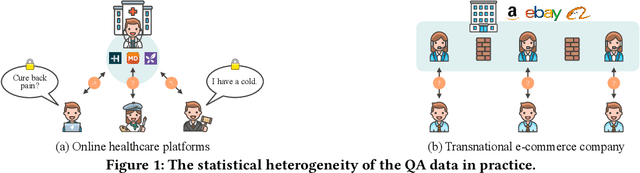
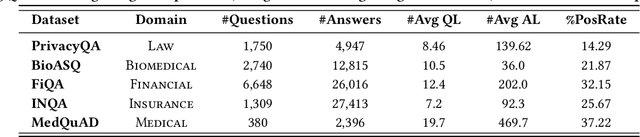
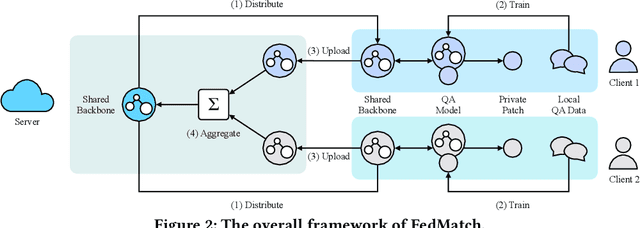
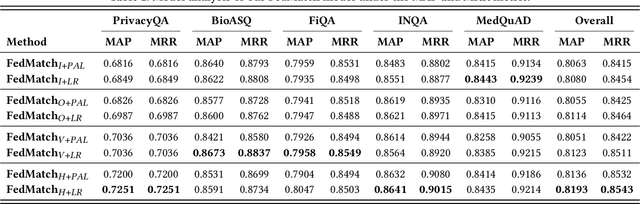
Question Answering (QA), a popular and promising technique for intelligent information access, faces a dilemma about data as most other AI techniques. On one hand, modern QA methods rely on deep learning models which are typically data-hungry. Therefore, it is expected to collect and fuse all the available QA datasets together in a common site for developing a powerful QA model. On the other hand, real-world QA datasets are typically distributed in the form of isolated islands belonging to different parties. Due to the increasing awareness of privacy security, it is almost impossible to integrate the data scattered around, or the cost is prohibited. A possible solution to this dilemma is a new approach known as federated learning, which is a privacy-preserving machine learning technique over distributed datasets. In this work, we propose to adopt federated learning for QA with the special concern on the statistical heterogeneity of the QA data. Here the heterogeneity refers to the fact that annotated QA data are typically with non-identical and independent distribution (non-IID) and unbalanced sizes in practice. Traditional federated learning methods may sacrifice the accuracy of individual models under the heterogeneous situation. To tackle this problem, we propose a novel Federated Matching framework for QA, named FedMatch, with a backbone-patch architecture. The shared backbone is to distill the common knowledge of all the participants while the private patch is a compact and efficient module to retain the domain information for each participant. To facilitate the evaluation, we build a benchmark collection based on several QA datasets from different domains to simulate the heterogeneous situation in practice. Empirical studies demonstrate that our model can achieve significant improvements against the baselines over all the datasets.