 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirtual Cells: Predict, Explain, Discover
May 20, 2025



Drug discovery is fundamentally a process of inferring the effects of treatments on patients, and would therefore benefit immensely from computational models that can reliably simulate patient responses, enabling researchers to generate and test large numbers of therapeutic hypotheses safely and economically before initiating costly clinical trials. Even a more specific model that predicts the functional response of cells to a wide range of perturbations would be tremendously valuable for discovering safe and effective treatments that successfully translate to the clinic. Creating such virtual cells has long been a goal of the computational research community that unfortunately remains unachieved given the daunting complexity and scale of cellular biology. Nevertheless, recent advances in AI, computing power, lab automation, and high-throughput cellular profiling provide new opportunities for reaching this goal. In this perspective, we present a vision for developing and evaluating virtual cells that builds on our experience at Recursion. We argue that in order to be a useful tool to discover novel biology, virtual cells must accurately predict the functional response of a cell to perturbations and explain how the predicted response is a consequence of modifications to key biomolecular interactions. We then introduce key principles for designing therapeutically-relevant virtual cells, describe a lab-in-the-loop approach for generating novel insights with them, and advocate for biologically-grounded benchmarks to guide virtual cell development. Finally, we make the case that our approach to virtual cells provides a useful framework for building other models at higher levels of organization, including virtual patients. We hope that these directions prove useful to the research community in developing virtual models optimized for positive impact on drug discovery outcomes.
Explain then Rank: Scale Calibration of Neural Rankers Using Natural Language Explanations from Large Language Models
Feb 19, 2024



The process of scale calibration in ranking systems involves adjusting the outputs of rankers to correspond with significant qualities like click-through rates or relevance, crucial for mirroring real-world value and thereby boosting the system's effectiveness and reliability. Although there has been research on calibrated ranking losses within learning-to-rank models, the particular issue of adjusting the scale for neural rankers, which excel in handling textual information, has not been thoroughly examined. Neural ranking models are adept at processing text data, yet the application of existing scale calibration techniques to these models poses significant challenges due to their complexity and the intensive training they require, often resulting in suboptimal outcomes. This study delves into the potential of large language models (LLMs) to provide uncertainty measurements for a query and document pair that correlate with the scale-calibrated scores. By employing Monte Carlo sampling to gauge relevance probabilities from LLMs and incorporating natural language explanations (NLEs) to articulate this uncertainty, we carry out comprehensive tests on two major document ranking datasets. Our findings reveal that the approach leveraging NLEs outperforms existing calibration methods under various training scenarios, leading to better calibrated neural rankers.
In-Context Example Ordering Guided by Label Distributions
Feb 18, 2024



By allowing models to predict without task-specific training, in-context learning (ICL) with pretrained LLMs has enormous potential in NLP. However, a number of problems persist in ICL. In particular, its performance is sensitive to the choice and order of in-context examples. Given the same set of in-context examples with different orderings, model performance may vary between near random to near state-of-the-art. In this work, we formulate in-context example ordering as an optimization problem. We examine three problem settings that differ in the assumptions they make about what is known about the task. Inspired by the idea of learning from label proportions, we propose two principles for in-context example ordering guided by model's probability predictions. We apply our proposed principles to thirteen text classification datasets and nine different autoregressive LLMs with 700M to 13B parameters. We demonstrate that our approach outperforms the baselines by improving the classification accuracy, reducing model miscalibration, and also by selecting better in-context examples.
Predictive Uncertainty-based Bias Mitigation in Ranking
Sep 18, 2023



Societal biases that are contained in retrieved documents have received increased interest. Such biases, which are often prevalent in the training data and learned by the model, can cause societal harms, by misrepresenting certain groups, and by enforcing stereotypes. Mitigating such biases demands algorithms that balance the trade-off between maximized utility for the user with fairness objectives, which incentivize unbiased rankings. Prior work on bias mitigation often assumes that ranking scores, which correspond to the utility that a document holds for a user, can be accurately determined. In reality, there is always a degree of uncertainty in the estimate of expected document utility. This uncertainty can be approximated by viewing ranking models through a Bayesian perspective, where the standard deterministic score becomes a distribution. In this work, we investigate whether uncertainty estimates can be used to decrease the amount of bias in the ranked results, while minimizing loss in measured utility. We introduce a simple method that uses the uncertainty of the ranking scores for an uncertainty-aware, post hoc approach to bias mitigation. We compare our proposed method with existing baselines for bias mitigation with respect to the utility-fairness trade-off, the controllability of methods, and computational costs. We show that an uncertainty-based approach can provide an intuitive and flexible trade-off that outperforms all baselines without additional training requirements, allowing for the post hoc use of this approach on top of arbitrary retrieval models.
A Lightweight Constrained Generation Alternative for Query-focused Summarization
Apr 23, 2023


Query-focused summarization (QFS) aims to provide a summary of a document that satisfies information need of a given query and is useful in various IR applications, such as abstractive snippet generation. Current QFS approaches typically involve injecting additional information, e.g. query-answer relevance or fine-grained token-level interaction between a query and document, into a finetuned large language model. However, these approaches often require extra parameters \& training, and generalize poorly to new dataset distributions. To mitigate this, we propose leveraging a recently developed constrained generation model Neurological Decoding (NLD) as an alternative to current QFS regimes which rely on additional sub-architectures and training. We first construct lexical constraints by identifying important tokens from the document using a lightweight gradient attribution model, then subsequently force the generated summary to satisfy these constraints by directly manipulating the final vocabulary likelihood. This lightweight approach requires no additional parameters or finetuning as it utilizes both an off-the-shelf neural retrieval model to construct the constraints and a standard generative language model to produce the QFS. We demonstrate the efficacy of this approach on two public QFS collections achieving near parity with the state-of-the-art model with substantially reduced complexity.
Parameter-efficient Modularised Bias Mitigation via AdapterFusion
Feb 13, 2023



Large pre-trained language models contain societal biases and carry along these biases to downstream tasks. Current in-processing bias mitigation approaches (like adversarial training) impose debiasing by updating a model's parameters, effectively transferring the model to a new, irreversible debiased state. In this work, we propose a novel approach to develop stand-alone debiasing functionalities separate from the model, which can be integrated into the model on-demand, while keeping the core model untouched. Drawing from the concept of AdapterFusion in multi-task learning, we introduce DAM (Debiasing with Adapter Modules) - a debiasing approach to first encapsulate arbitrary bias mitigation functionalities into separate adapters, and then add them to the model on-demand in order to deliver fairness qualities. We conduct a large set of experiments on three classification tasks with gender, race, and age as protected attributes. Our results show that DAM improves or maintains the effectiveness of bias mitigation, avoids catastrophic forgetting in a multi-attribute scenario, and maintains on-par task performance, while granting parameter-efficiency and easy switching between the original and debiased models.
CODER: An efficient framework for improving retrieval through COntextualized Document Embedding Reranking
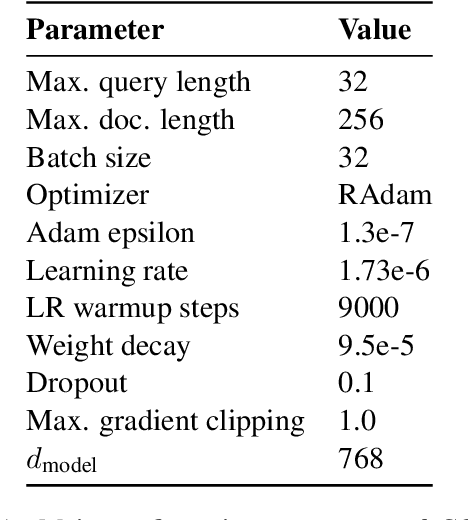
Dec 16, 2021
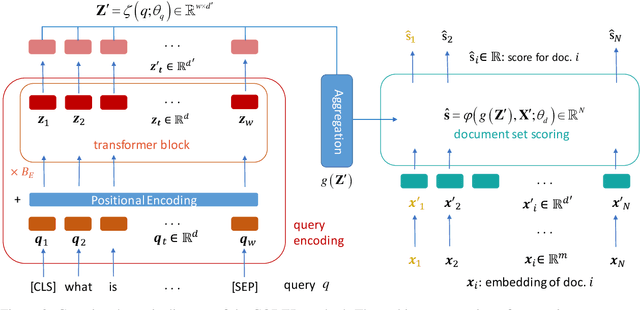
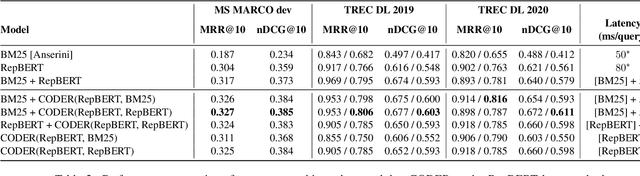
We present a framework for improving the performance of a wide class of retrieval models at minimal computational cost. It utilizes precomputed document representations extracted by a base dense retrieval method and involves training a model to jointly score a large set of retrieved candidate documents for each query, while potentially transforming on the fly the representation of each document in the context of the other candidates as well as the query itself. When scoring a document representation based on its similarity to a query, the model is thus aware of the representation of its "peer" documents. We show that our approach leads to substantial improvement in retrieval performance over the base method and over scoring candidate documents in isolation from one another, as in a pair-wise training setting. Crucially, unlike term-interaction rerankers based on BERT-like encoders, it incurs a negligible computational overhead on top of any first-stage method at run time, allowing it to be easily combined with any state-of-the-art dense retrieval method. Finally, concurrently considering a set of candidate documents for a given query enables additional valuable capabilities in retrieval, such as score calibration and mitigating societal biases in ranking.
Machine Learning for Mechanical Ventilation Control (Extended Abstract)
Nov 23, 2021Mechanical ventilation is one of the most widely used therapies in the ICU. However, despite broad application from anaesthesia to COVID-related life support, many injurious challenges remain. We frame these as a control problem: ventilators must let air in and out of the patient's lungs according to a prescribed trajectory of airway pressure. Industry-standard controllers, based on the PID method, are neither optimal nor robust. Our data-driven approach learns to control an invasive ventilator by training on a simulator itself trained on data collected from the ventilator. This method outperforms popular reinforcement learning algorithms and even controls the physical ventilator more accurately and robustly than PID. These results underscore how effective data-driven methodologies can be for invasive ventilation and suggest that more general forms of ventilation (e.g., non-invasive, adaptive) may also be amenable.
A Modern Perspective on Query Likelihood with Deep Generative Retrieval Models
Jun 25, 2021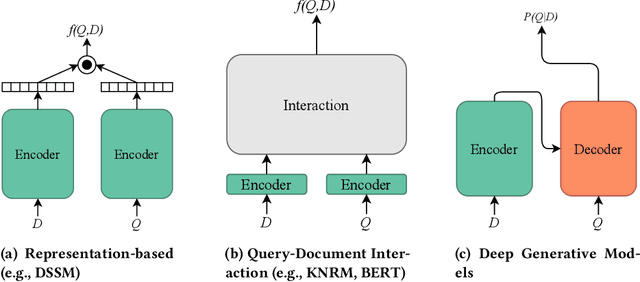
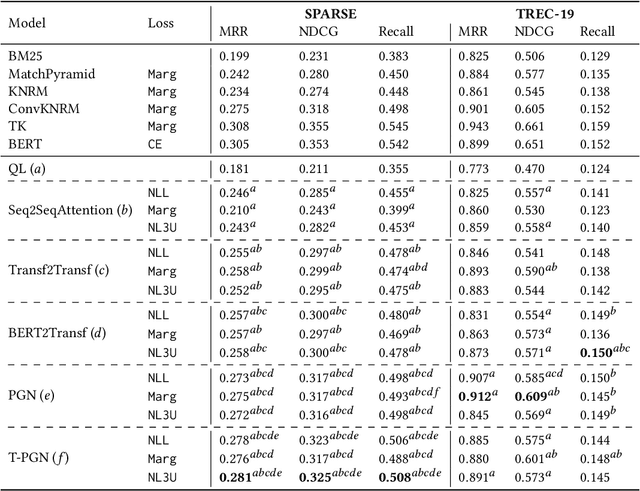
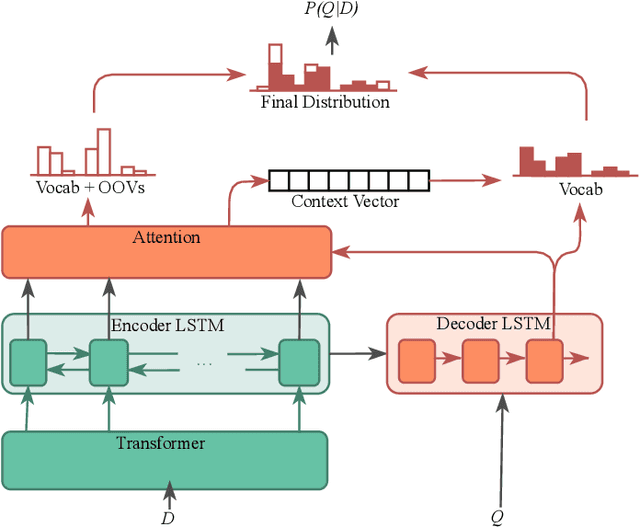

Existing neural ranking models follow the text matching paradigm, where document-to-query relevance is estimated through predicting the matching score. Drawing from the rich literature of classical generative retrieval models, we introduce and formalize the paradigm of deep generative retrieval models defined via the cumulative probabilities of generating query terms. This paradigm offers a grounded probabilistic view on relevance estimation while still enabling the use of modern neural architectures. In contrast to the matching paradigm, the probabilistic nature of generative rankers readily offers a fine-grained measure of uncertainty. We adopt several current neural generative models in our framework and introduce a novel generative ranker (T-PGN), which combines the encoding capacity of Transformers with the Pointer Generator Network model. We conduct an extensive set of evaluation experiments on passage retrieval, leveraging the MS MARCO Passage Re-ranking and TREC Deep Learning 2019 Passage Re-ranking collections. Our results show the significantly higher performance of the T-PGN model when compared with other generative models. Lastly, we demonstrate that exploiting the uncertainty information of deep generative rankers opens new perspectives to query/collection understanding, and significantly improves the cut-off prediction task.
Not All Relevance Scores are Equal: Efficient Uncertainty and Calibration Modeling for Deep Retrieval Models
May 10, 2021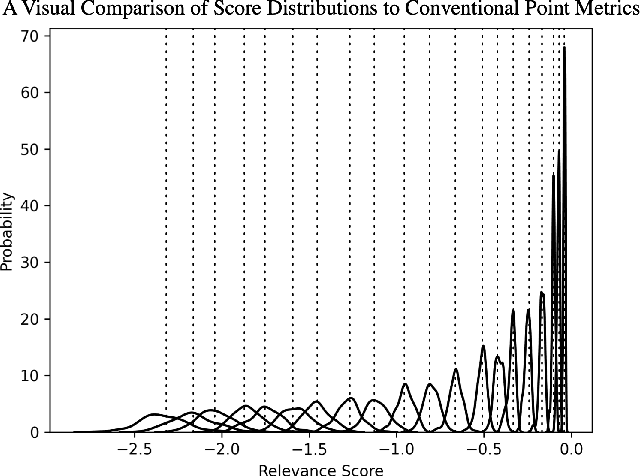
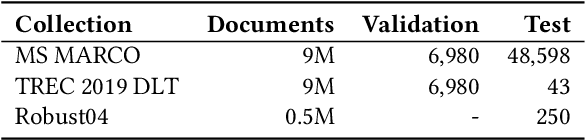
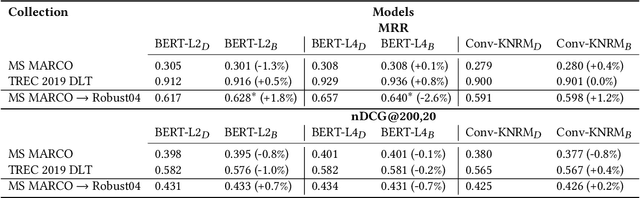
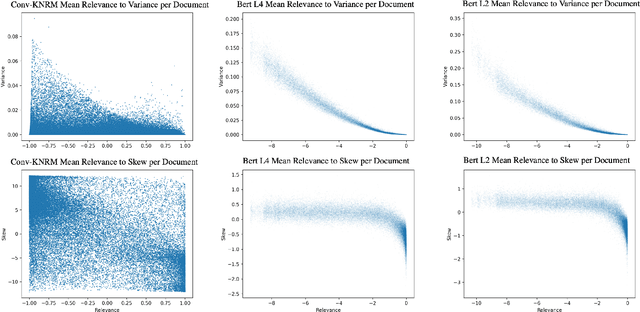
In any ranking system, the retrieval model outputs a single score for a document based on its belief on how relevant it is to a given search query. While retrieval models have continued to improve with the introduction of increasingly complex architectures, few works have investigated a retrieval model's belief in the score beyond the scope of a single value. We argue that capturing the model's uncertainty with respect to its own scoring of a document is a critical aspect of retrieval that allows for greater use of current models across new document distributions, collections, or even improving effectiveness for down-stream tasks. In this paper, we address this problem via an efficient Bayesian framework for retrieval models which captures the model's belief in the relevance score through a stochastic process while adding only negligible computational overhead. We evaluate this belief via a ranking based calibration metric showing that our approximate Bayesian framework significantly improves a retrieval model's ranking effectiveness through a risk aware reranking as well as its confidence calibration. Lastly, we demonstrate that this additional uncertainty information is actionable and reliable on down-stream tasks represented via cutoff prediction.