 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracing Facts or just Copies? A critical investigation of the Competitions of Mechanisms in Large Language Models
Jul 16, 2025



This paper presents a reproducibility study examining how Large Language Models (LLMs) manage competing factual and counterfactual information, focusing on the role of attention heads in this process. We attempt to reproduce and reconcile findings from three recent studies by Ortu et al., Yu, Merullo, and Pavlick and McDougall et al. that investigate the competition between model-learned facts and contradictory context information through Mechanistic Interpretability tools. Our study specifically examines the relationship between attention head strength and factual output ratios, evaluates competing hypotheses about attention heads' suppression mechanisms, and investigates the domain specificity of these attention patterns. Our findings suggest that attention heads promoting factual output do so via general copy suppression rather than selective counterfactual suppression, as strengthening them can also inhibit correct facts. Additionally, we show that attention head behavior is domain-dependent, with larger models exhibiting more specialized and category-sensitive patterns.
* 18 Pages, 13 figures
Information Retrieval for Climate Impact
Apr 01, 2025The purpose of the MANILA24 Workshop on information retrieval for climate impact was to bring together researchers from academia, industry, governments, and NGOs to identify and discuss core research problems in information retrieval to assess climate change impacts. The workshop aimed to foster collaboration by bringing communities together that have so far not been very well connected -- information retrieval, natural language processing, systematic reviews, impact assessments, and climate science. The workshop brought together a diverse set of researchers and practitioners interested in contributing to the development of a technical research agenda for information retrieval to assess climate change impacts.
Correctness is not Faithfulness in RAG Attributions
Dec 23, 2024Retrieving relevant context is a common approach to reduce hallucinations and enhance answer reliability. Explicitly citing source documents allows users to verify generated responses and increases trust. Prior work largely evaluates citation correctness - whether cited documents support the corresponding statements. But citation correctness alone is insufficient. To establish trust in attributed answers, we must examine both citation correctness and citation faithfulness. In this work, we first disentangle the notions of citation correctness and faithfulness, which have been applied inconsistently in previous studies. Faithfulness ensures that the model's reliance on cited documents is genuine, reflecting actual reference use rather than superficial alignment with prior beliefs, which we call post-rationalization. We design an experiment that reveals the prevalent issue of post-rationalization, which undermines reliable attribution and may result in misplaced trust. Our findings suggest that current attributed answers often lack citation faithfulness (up to 57 percent of the citations), highlighting the need to evaluate correctness and faithfulness for trustworthy attribution in language models.
RankingSHAP -- Listwise Feature Attribution Explanations for Ranking Models
Mar 24, 2024Feature attributions are a commonly used explanation type, when we want to posthoc explain the prediction of a trained model. Yet, they are not very well explored in IR. Importantly, feature attribution has rarely been rigorously defined, beyond attributing the most important feature the highest value. What it means for a feature to be more important than others is often left vague. Consequently, most approaches focus on just selecting the most important features and under utilize or even ignore the relative importance within features. In this work, we rigorously define the notion of feature attribution for ranking models, and list essential properties that a valid attribution should have. We then propose RankingSHAP as a concrete instantiation of a list-wise ranking attribution method. Contrary to current explanation evaluation schemes that focus on selections, we propose two novel evaluation paradigms for evaluating attributions over learning-to-rank models. We evaluate RankingSHAP for commonly used learning-to-rank datasets to showcase the more nuanced use of an attribution method while highlighting the limitations of selection-based explanations. In a simulated experiment we design an interpretable model to demonstrate how list-wise ranking attributes can be used to investigate model decisions and evaluate the explanations qualitatively. Because of the contrastive nature of the ranking task, our understanding of ranking model decisions can substantially benefit from feature attribution explanations like RankingSHAP.
Predictive Uncertainty-based Bias Mitigation in Ranking
Sep 18, 2023



Societal biases that are contained in retrieved documents have received increased interest. Such biases, which are often prevalent in the training data and learned by the model, can cause societal harms, by misrepresenting certain groups, and by enforcing stereotypes. Mitigating such biases demands algorithms that balance the trade-off between maximized utility for the user with fairness objectives, which incentivize unbiased rankings. Prior work on bias mitigation often assumes that ranking scores, which correspond to the utility that a document holds for a user, can be accurately determined. In reality, there is always a degree of uncertainty in the estimate of expected document utility. This uncertainty can be approximated by viewing ranking models through a Bayesian perspective, where the standard deterministic score becomes a distribution. In this work, we investigate whether uncertainty estimates can be used to decrease the amount of bias in the ranked results, while minimizing loss in measured utility. We introduce a simple method that uses the uncertainty of the ranking scores for an uncertainty-aware, post hoc approach to bias mitigation. We compare our proposed method with existing baselines for bias mitigation with respect to the utility-fairness trade-off, the controllability of methods, and computational costs. We show that an uncertainty-based approach can provide an intuitive and flexible trade-off that outperforms all baselines without additional training requirements, allowing for the post hoc use of this approach on top of arbitrary retrieval models.
Fairness of Exposure in Light of Incomplete Exposure Estimation
May 25, 2022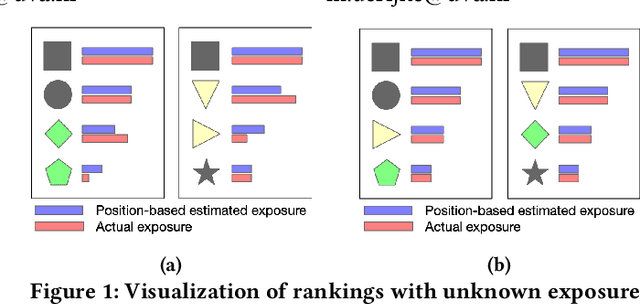
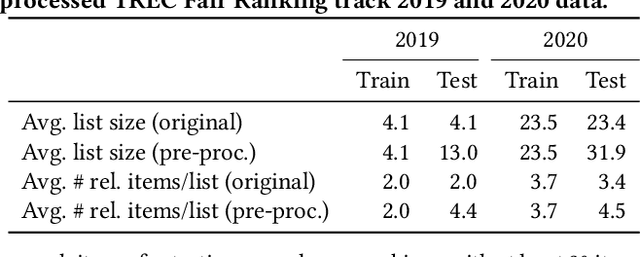
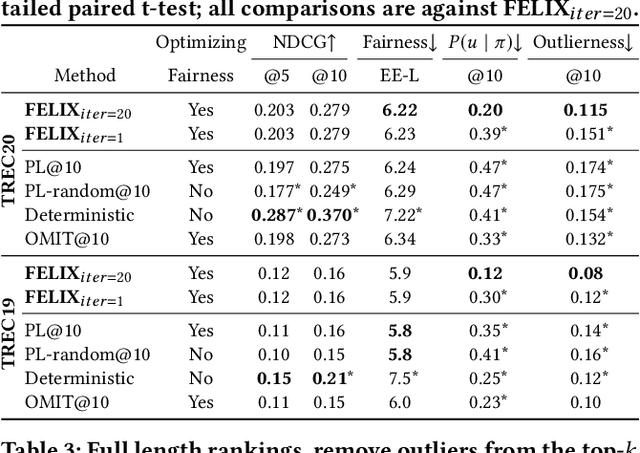
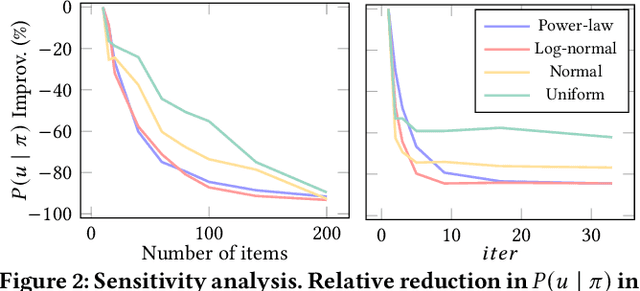
Fairness of exposure is a commonly used notion of fairness for ranking systems. It is based on the idea that all items or item groups should get exposure proportional to the merit of the item or the collective merit of the items in the group. Often, stochastic ranking policies are used to ensure fairness of exposure. Previous work unrealistically assumes that we can reliably estimate the expected exposure for all items in each ranking produced by the stochastic policy. In this work, we discuss how to approach fairness of exposure in cases where the policy contains rankings of which, due to inter-item dependencies, we cannot reliably estimate the exposure distribution. In such cases, we cannot determine whether the policy can be considered fair. Our contributions in this paper are twofold. First, we define a method called FELIX for finding stochastic policies that avoid showing rankings with unknown exposure distribution to the user without having to compromise user utility or item fairness. Second, we extend the study of fairness of exposure to the top-k setting and also assess FELIX in this setting. We find that FELIX can significantly reduce the number of rankings with unknown exposure distribution without a drop in user utility or fairness compared to existing fair ranking methods, both for full-length and top-k rankings. This is an important first step in developing fair ranking methods for cases where we have incomplete knowledge about the user's behaviour.
Understanding and Mitigating the Effect of Outliers in Fair Ranking
Jan 03, 2022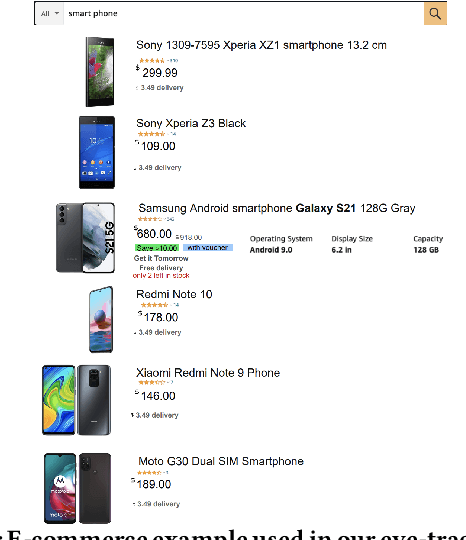

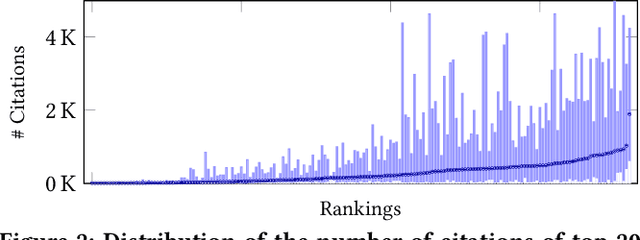
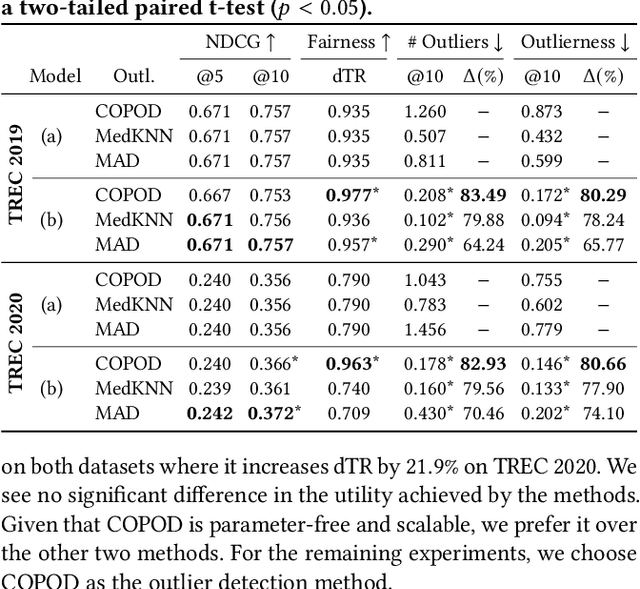
Traditional ranking systems are expected to sort items in the order of their relevance and thereby maximize their utility. In fair ranking, utility is complemented with fairness as an optimization goal. Recent work on fair ranking focuses on developing algorithms to optimize for fairness, given position-based exposure. In contrast, we identify the potential of outliers in a ranking to influence exposure and thereby negatively impact fairness. An outlier in a list of items can alter the examination probabilities, which can lead to different distributions of attention, compared to position-based exposure. We formalize outlierness in a ranking, show that outliers are present in realistic datasets, and present the results of an eye-tracking study, showing that users scanning order and the exposure of items are influenced by the presence of outliers. We then introduce OMIT, a method for fair ranking in the presence of outliers. Given an outlier detection method, OMIT improves fair allocation of exposure by suppressing outliers in the top-k ranking. Using an academic search dataset, we show that outlierness optimization leads to a fairer policy that displays fewer outliers in the top-k, while maintaining a reasonable trade-off between fairness and utility.