 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundations of Spatial Perception for Robotics: Hierarchical Representations and Real-time Systems
May 11, 20233D spatial perception is the problem of building and maintaining an actionable and persistent representation of the environment in real-time using sensor data and prior knowledge. Despite the fast-paced progress in robot perception, most existing methods either build purely geometric maps (as in traditional SLAM) or flat metric-semantic maps that do not scale to large environments or large dictionaries of semantic labels. The first part of this paper is concerned with representations: we show that scalable representations for spatial perception need to be hierarchical in nature. Hierarchical representations are efficient to store, and lead to layered graphs with small treewidth, which enable provably efficient inference. We then introduce an example of hierarchical representation for indoor environments, namely a 3D scene graph, and discuss its structure and properties. The second part of the paper focuses on algorithms to incrementally construct a 3D scene graph as the robot explores the environment. Our algorithms combine 3D geometry, topology (to cluster the places into rooms), and geometric deep learning (e.g., to classify the type of rooms the robot is moving across). The third part of the paper focuses on algorithms to maintain and correct 3D scene graphs during long-term operation. We propose hierarchical descriptors for loop closure detection and describe how to correct a scene graph in response to loop closures, by solving a 3D scene graph optimization problem. We conclude the paper by combining the proposed perception algorithms into Hydra, a real-time spatial perception system that builds a 3D scene graph from visual-inertial data in real-time. We showcase Hydra's performance in photo-realistic simulations and real data collected by a Clearpath Jackal robots and a Unitree A1 robot. We release an open-source implementation of Hydra at https://github.com/MIT-SPARK/Hydra.
Task-Aware Risk Estimation of Perception Failures for Autonomous Vehicles
May 03, 2023



Safety and performance are key enablers for autonomous driving: on the one hand we want our autonomous vehicles (AVs) to be safe, while at the same time their performance (e.g., comfort or progression) is key to adoption. To effectively walk the tight-rope between safety and performance, AVs need to be risk-averse, but not entirely risk-avoidant. To facilitate safe-yet-performant driving, in this paper, we develop a task-aware risk estimator that assesses the risk a perception failure poses to the AV's motion plan. If the failure has no bearing on the safety of the AV's motion plan, then regardless of how egregious the perception failure is, our task-aware risk estimator considers the failure to have a low risk; on the other hand, if a seemingly benign perception failure severely impacts the motion plan, then our estimator considers it to have a high risk. In this paper, we propose a task-aware risk estimator to decide whether a safety maneuver needs to be triggered. To estimate the task-aware risk, first, we leverage the perception failure - detected by a perception monitor - to synthesize an alternative plausible model for the vehicle's surroundings. The risk due to the perception failure is then formalized as the "relative" risk to the AV's motion plan between the perceived and the alternative plausible scenario. We employ a statistical tool called copula, which models tail dependencies between distributions, to estimate this risk. The theoretical properties of the copula allow us to compute probably approximately correct (PAC) estimates of the risk. We evaluate our task-aware risk estimator using NuPlan and compare it with established baselines, showing that the proposed risk estimator achieves the best F1-score (doubling the score of the best baseline) and exhibits a good balance between recall and precision, i.e., a good balance of safety and performance.
Multi-Camera Visual-Inertial Simultaneous Localization and Mapping for Autonomous Valet Parking
Apr 27, 2023



Localization and mapping are key capabilities for self-driving vehicles. This paper describes a visual-inertial SLAM system that estimates an accurate and globally consistent trajectory of the vehicle and reconstructs a dense model of the free space surrounding the car. Towards this goal, we build on Kimera and extend it to use multiple cameras as well as external (e.g. wheel) odometry sensors, to obtain accurate and robust odometry estimates in real-world problems. Additionally, we propose an effective scheme for closing loops that circumvents the drawbacks of common alternatives based on the Perspective-n-Point method and also works with a single monocular camera. Finally, we develop a method for dense 3D mapping of the free space that combines a segmentation network for free-space detection with a homography-based dense mapping technique. We test our system on photo-realistic simulations and on several real datasets collected by a car prototype developed by the Ford Motor Company, spanning both indoor and outdoor parking scenarios. Our multi-camera system is shown to outperform state-of-the art open-source visual-inertial-SLAM pipelines (Vins-Fusion, ORB-SLAM3), and exhibits an average trajectory error under 1% of the trajectory length across more than 8 km of distance traveled (combined across all datasets). A video showcasing the system is available here: youtu.be/H8CpzDpXOI8
Hydra-Multi: Collaborative Online Construction of 3D Scene Graphs with Multi-Robot Teams
Apr 26, 20233D scene graphs have recently emerged as an expressive high-level map representation that describes a 3D environment as a layered graph where nodes represent spatial concepts at multiple levels of abstraction (e.g., objects, rooms, buildings) and edges represent relations between concepts (e.g., inclusion, adjacency). This paper describes Hydra-Multi, the first multi-robot spatial perception system capable of constructing a multi-robot 3D scene graph online from sensor data collected by robots in a team. In particular, we develop a centralized system capable of constructing a joint 3D scene graph by taking incremental inputs from multiple robots, effectively finding the relative transforms between the robots' frames, and incorporating loop closure detections to correctly reconcile the scene graph nodes from different robots. We evaluate Hydra-Multi on simulated and real scenarios and show it is able to reconstruct accurate 3D scene graphs online. We also demonstrate Hydra-Multi's capability of supporting heterogeneous teams by fusing different map representations built by robots with different sensor suites.
Resilient and Distributed Multi-Robot Visual SLAM: Datasets, Experiments, and Lessons Learned
Apr 10, 2023



This paper revisits Kimera-Multi, a distributed multi-robot Simultaneous Localization and Mapping (SLAM) system, towards the goal of deployment in the real world. In particular, this paper has three main contributions. First, we describe improvements to Kimera-Multi to make it resilient to large-scale real-world deployments, with particular emphasis on handling intermittent and unreliable communication. Second, we collect and release challenging multi-robot benchmarking datasets obtained during live experiments conducted on the MIT campus, with accurate reference trajectories and maps for evaluation. The datasets include up to 8 robots traversing long distances (up to 8 km) and feature many challenging elements such as severe visual ambiguities (e.g., in underground tunnels and hallways), mixed indoor and outdoor trajectories with different lighting conditions, and dynamic entities (e.g., pedestrians and cars). Lastly, we evaluate the resilience of Kimera-Multi under different communication scenarios, and provide a quantitative comparison with a centralized baseline system. Based on the results from both live experiments and subsequent analysis, we discuss the strengths and weaknesses of Kimera-Multi, and suggest future directions for both algorithm and system design. We release the source code of Kimera-Multi and all datasets to facilitate further research towards the reliable real-world deployment of multi-robot SLAM systems.
Data-Association-Free Landmark-based SLAM
Mar 07, 2023



We study landmark-based SLAM with unknown data association: our robot navigates in a completely unknown environment and has to simultaneously reason over its own trajectory, the positions of an unknown number of landmarks in the environment, and potential data associations between measurements and landmarks. This setup is interesting since: (i) it arises when recovering from data association failures or from SLAM with information-poor sensors, (ii) it sheds light on fundamental limits (and hardness) of landmark-based SLAM problems irrespective of the front-end data association method, and (iii) it generalizes existing approaches where data association is assumed to be known or partially known. We approach the problem by splitting it into an inner problem of estimating the trajectory, landmark positions and data associations and an outer problem of estimating the number of landmarks. Our approach creates useful and novel connections with existing techniques from discrete-continuous optimization (e.g., k-means clustering), which has the potential to trigger novel research. We demonstrate the proposed approaches in extensive simulations and on real datasets and show that the proposed techniques outperform typical data association baselines and are even competitive against an "oracle" baseline which has access to the number of landmarks and an initial guess for each landmark.
Vision-Based Terrain Relative Navigation on High-Altitude Balloon and Sub-Orbital Rocket
Feb 16, 2023



We present an experimental analysis on the use of a camera-based approach for high-altitude navigation by associating mapped landmarks from a satellite image database to camera images, and by leveraging inertial sensors between camera frames. We evaluate performance of both a sideways-tilted and downward-facing camera on data collected from a World View Enterprises high-altitude balloon with data beginning at an altitude of 33 km and descending to near ground level (4.5 km) with 1.5 hours of flight time. We demonstrate less than 290 meters of average position error over a trajectory of more than 150 kilometers. In addition to showing performance across a range of altitudes, we also demonstrate the robustness of the Terrain Relative Navigation (TRN) method to rapid rotations of the balloon, in some cases exceeding 20 degrees per second, and to camera obstructions caused by both cloud coverage and cords swaying underneath the balloon. Additionally, we evaluate performance on data collected by two cameras inside the capsule of Blue Origin's New Shepard rocket on payload flight NS-23, traveling at speeds up to 880 km/hr, and demonstrate less than 55 meters of average position error.
* Published in 2023 AIAA SciTech
A Correct-and-Certify Approach to Self-Supervise Object Pose Estimators via Ensemble Self-Training
Feb 12, 2023



Real-world robotics applications demand object pose estimation methods that work reliably across a variety of scenarios. Modern learning-based approaches require large labeled datasets and tend to perform poorly outside the training domain. Our first contribution is to develop a robust corrector module that corrects pose estimates using depth information, thus enabling existing methods to better generalize to new test domains; the corrector operates on semantic keypoints (but is also applicable to other pose estimators) and is fully differentiable. Our second contribution is an ensemble self-training approach that simultaneously trains multiple pose estimators in a self-supervised manner. Our ensemble self-training architecture uses the robust corrector to refine the output of each pose estimator; then, it evaluates the quality of the outputs using observable correctness certificates; finally, it uses the observably correct outputs for further training, without requiring external supervision. As an additional contribution, we propose small improvements to a regression-based keypoint detection architecture, to enhance its robustness to outliers; these improvements include a robust pooling scheme and a robust centroid computation. Experiments on the YCBV and TLESS datasets show the proposed ensemble self-training outperforms fully supervised baselines while not requiring 3D annotations on real data.
NeRF-SLAM: Real-Time Dense Monocular SLAM with Neural Radiance Fields
Oct 24, 2022



We propose a novel geometric and photometric 3D mapping pipeline for accurate and real-time scene reconstruction from monocular images. To achieve this, we leverage recent advances in dense monocular SLAM and real-time hierarchical volumetric neural radiance fields. Our insight is that dense monocular SLAM provides the right information to fit a neural radiance field of the scene in real-time, by providing accurate pose estimates and depth-maps with associated uncertainty. With our proposed uncertainty-based depth loss, we achieve not only good photometric accuracy, but also great geometric accuracy. In fact, our proposed pipeline achieves better geometric and photometric accuracy than competing approaches (up to 179% better PSNR and 86% better L1 depth), while working in real-time and using only monocular images.
Probabilistic Volumetric Fusion for Dense Monocular SLAM
Oct 03, 2022
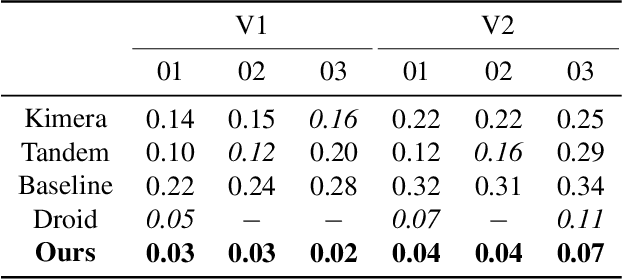
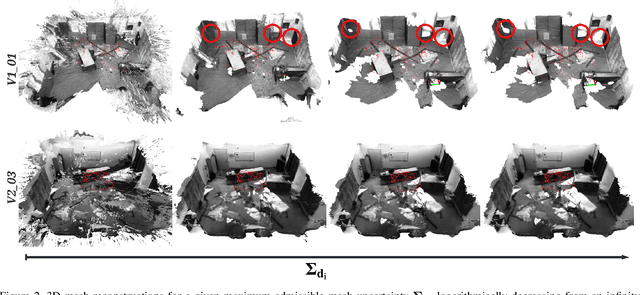
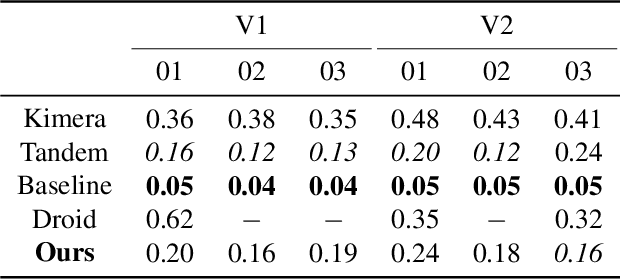
We present a novel method to reconstruct 3D scenes from images by leveraging deep dense monocular SLAM and fast uncertainty propagation. The proposed approach is able to 3D reconstruct scenes densely, accurately, and in real-time while being robust to extremely noisy depth estimates coming from dense monocular SLAM. Differently from previous approaches, that either use ad-hoc depth filters, or that estimate the depth uncertainty from RGB-D cameras' sensor models, our probabilistic depth uncertainty derives directly from the information matrix of the underlying bundle adjustment problem in SLAM. We show that the resulting depth uncertainty provides an excellent signal to weight the depth-maps for volumetric fusion. Without our depth uncertainty, the resulting mesh is noisy and with artifacts, while our approach generates an accurate 3D mesh with significantly fewer artifacts. We provide results on the challenging Euroc dataset, and show that our approach achieves 92% better accuracy than directly fusing depths from monocular SLAM, and up to 90% improvements compared to the best competing approach.