 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthesizing and Identifying Noise Levels in Autonomous Vehicle Camera Radar Datasets
May 01, 2025



Detecting and tracking objects is a crucial component of any autonomous navigation method. For the past decades, object detection has yielded promising results using neural networks on various datasets. While many methods focus on performance metrics, few projects focus on improving the robustness of these detection and tracking pipelines, notably to sensor failures. In this paper we attempt to address this issue by creating a realistic synthetic data augmentation pipeline for camera-radar Autonomous Vehicle (AV) datasets. Our goal is to accurately simulate sensor failures and data deterioration due to real-world interferences. We also present our results of a baseline lightweight Noise Recognition neural network trained and tested on our augmented dataset, reaching an overall recognition accuracy of 54.4\% on 11 categories across 10086 images and 2145 radar point-clouds.
Context-Aware Outlier Rejection for Robust Multi-View 3D Tracking of Similar Small Birds in An Outdoor Aviary
Dec 21, 2024



This paper presents a novel approach for robust 3D tracking of multiple birds in an outdoor aviary using a multi-camera system. Our method addresses the challenges of visually similar birds and their rapid movements by leveraging environmental landmarks for enhanced feature matching and 3D reconstruction. In our approach, outliers are rejected based on their nearest landmark. This enables precise 3D-modeling and simultaneous tracking of multiple birds. By utilizing environmental context, our approach significantly improves the differentiation between visually similar birds, a key obstacle in existing tracking systems. Experimental results demonstrate the effectiveness of our method, showing a $20\%$ elimination of outliers in the 3D reconstruction process, with a $97\%$ accuracy in matching. This remarkable accuracy in 3D modeling translates to robust and reliable tracking of multiple birds, even in challenging outdoor conditions. Our work not only advances the field of computer vision but also provides a valuable tool for studying bird behavior and movement patterns in natural settings. We also provide a large annotated dataset of 80 birds residing in four enclosures for 20 hours of footage which provides a rich testbed for researchers in computer vision, ornithologists, and ecologists. Code and the link to the dataset is available at https://github.com/airou-lab/3D_Multi_Bird_Tracking
Design and Implementation of Smart Infrastructures and Connected Vehicles in A Mini-city Platform
Aug 08, 2024



This paper presents a 1/10th scale mini-city platform used as a testing bed for evaluating autonomous and connected vehicles. Using the mini-city platform, we can evaluate different driving scenarios including human-driven and autonomous driving. We provide a unique, visual feature-rich environment for evaluating computer vision methods. The conducted experiments utilize onboard sensors mounted on a robotic platform we built, allowing them to navigate in a controlled real-world urban environment. The designed city is occupied by cars, stop signs, a variety of residential and business buildings, and complex intersections mimicking an urban area. Furthermore, We have designed an intelligent infrastructure at one of the intersections in the city which helps safer and more efficient navigation in the presence of multiple cars and pedestrians. We have used the mini-city platform for the analysis of three different applications: city mapping, depth estimation in challenging occluded environments, and smart infrastructure for connected vehicles. Our smart infrastructure is among the first to develop and evaluate Vehicle-to-Infrastructure (V2I) communication at intersections. The intersection-related result shows how inaccuracy in perception, including mapping and localization, can affect safety. The proposed mini-city platform can be considered as a baseline environment for developing research and education in intelligent transportation systems.
A Survey on Congestion Control and Scheduling for Multipath TCP: Machine Learning vs Classical Approaches
Sep 17, 2023Multipath TCP (MPTCP) has been widely used as an efficient way for communication in many applications. Data centers, smartphones, and network operators use MPTCP to balance the traffic in a network efficiently. MPTCP is an extension of TCP (Transmission Control Protocol), which provides multiple paths, leading to higher throughput and low latency. Although MPTCP has shown better performance than TCP in many applications, it has its own challenges. The network can become congested due to heavy traffic in the multiple paths (subflows) if the subflow rates are not determined correctly. Moreover, communication latency can occur if the packets are not scheduled correctly between the subflows. This paper reviews techniques to solve the above-mentioned problems based on two main approaches; non data-driven (classical) and data-driven (Machine Learning) approaches. This paper compares these two approaches and highlights their strengths and weaknesses with a view to motivating future researchers in this exciting area of machine learning for communications. This paper also provides details on the simulation of MPTCP and its implementations in real environments.
Visual Navigation for Autonomous Vehicles: An Open-source Hands-on Robotics Course at MIT
Jun 01, 2022
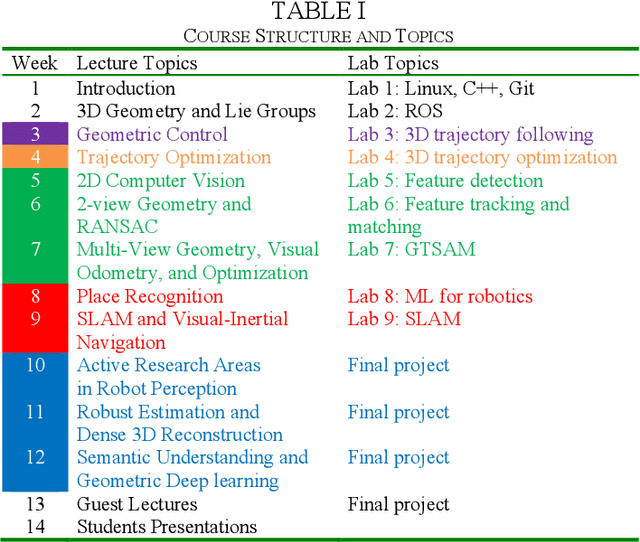
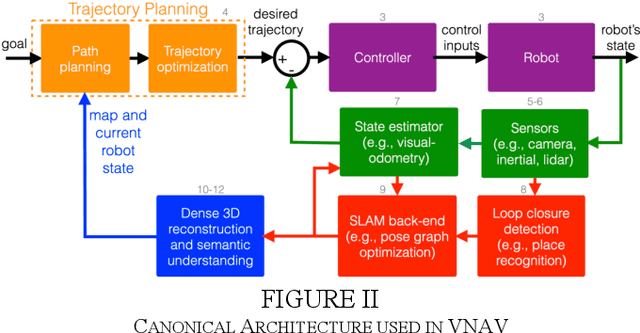
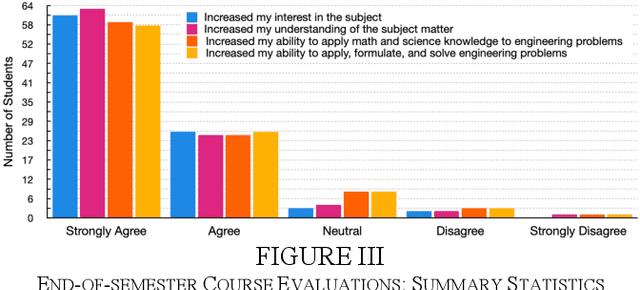
This paper reports on the development, execution, and open-sourcing of a new robotics course at MIT. The course is a modern take on "Visual Navigation for Autonomous Vehicles" (VNAV) and targets first-year graduate students and senior undergraduates with prior exposure to robotics. VNAV has the goal of preparing the students to perform research in robotics and vision-based navigation, with emphasis on drones and self-driving cars. The course spans the entire autonomous navigation pipeline; as such, it covers a broad set of topics, including geometric control and trajectory optimization, 2D and 3D computer vision, visual and visual-inertial odometry, place recognition, simultaneous localization and mapping, and geometric deep learning for perception. VNAV has three key features. First, it bridges traditional computer vision and robotics courses by exposing the challenges that are specific to embodied intelligence, e.g., limited computation and need for just-in-time and robust perception to close the loop over control and decision making. Second, it strikes a balance between depth and breadth by combining rigorous technical notes (including topics that are less explored in typical robotics courses, e.g., on-manifold optimization) with slides and videos showcasing the latest research results. Third, it provides a compelling approach to hands-on robotics education by leveraging a physical drone platform (mostly suitable for small residential courses) and a photo-realistic Unity-based simulator (open-source and scalable to large online courses). VNAV has been offered at MIT in the Falls of 2018-2021 and is now publicly available on MIT OpenCourseWare (OCW).
Motivating Physical Activity via Competitive Human-Robot Interaction
Feb 14, 2022
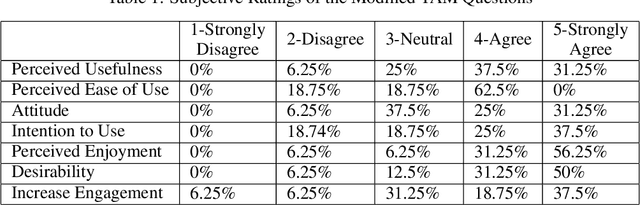
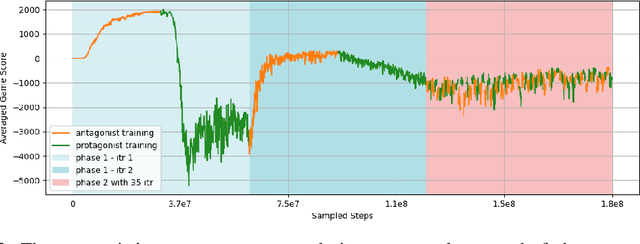
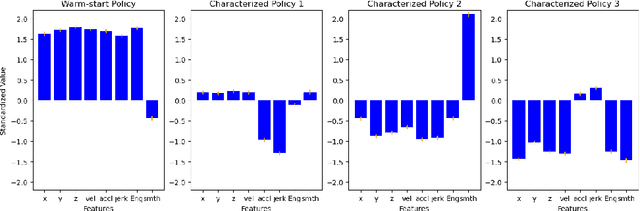
This project aims to motivate research in competitive human-robot interaction by creating a robot competitor that can challenge human users in certain scenarios such as physical exercise and games. With this goal in mind, we introduce the Fencing Game, a human-robot competition used to evaluate both the capabilities of the robot competitor and user experience. We develop the robot competitor through iterative multi-agent reinforcement learning and show that it can perform well against human competitors. Our user study additionally found that our system was able to continuously create challenging and enjoyable interactions that significantly increased human subjects' heart rates. The majority of human subjects considered the system to be entertaining and desirable for improving the quality of their exercise.
Reachability Analysis of Neural Feedback Loops
Aug 09, 2021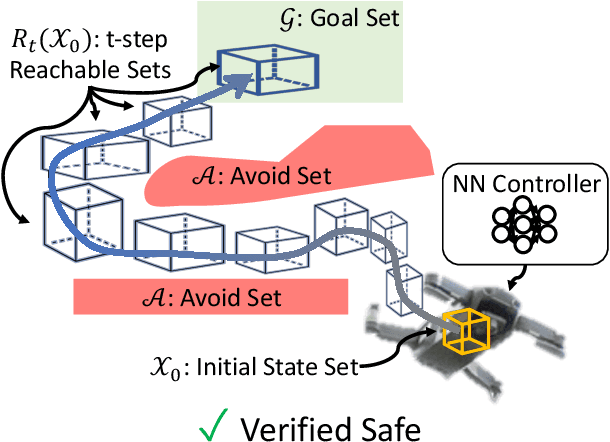
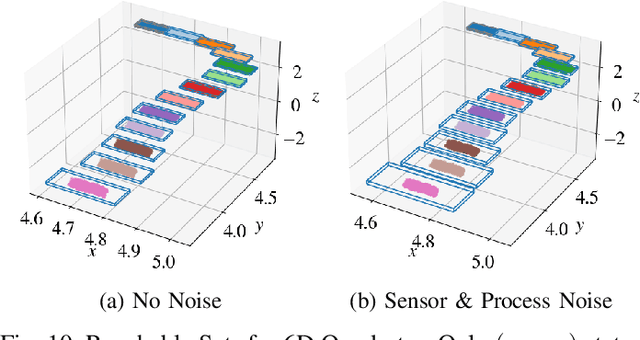
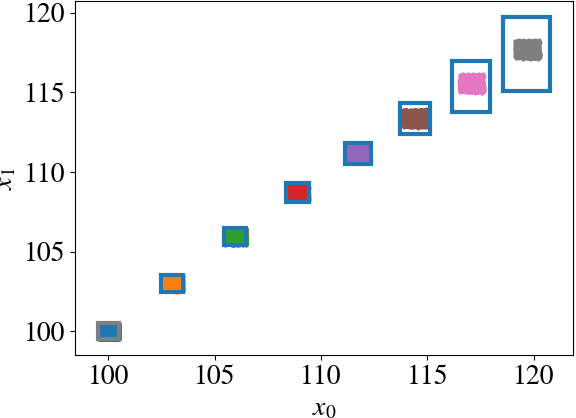
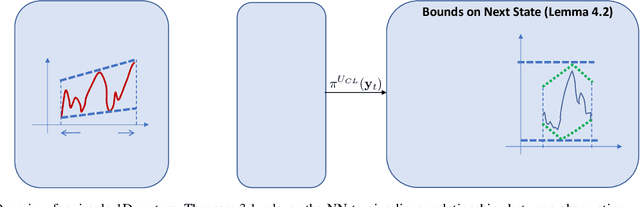
Neural Networks (NNs) can provide major empirical performance improvements for closed-loop systems, but they also introduce challenges in formally analyzing those systems' safety properties. In particular, this work focuses on estimating the forward reachable set of \textit{neural feedback loops} (closed-loop systems with NN controllers). Recent work provides bounds on these reachable sets, but the computationally tractable approaches yield overly conservative bounds (thus cannot be used to verify useful properties), and the methods that yield tighter bounds are too intensive for online computation. This work bridges the gap by formulating a convex optimization problem for the reachability analysis of closed-loop systems with NN controllers. While the solutions are less tight than previous (semidefinite program-based) methods, they are substantially faster to compute, and some of those computational time savings can be used to refine the bounds through new input set partitioning techniques, which is shown to dramatically reduce the tightness gap. The new framework is developed for systems with uncertainty (e.g., measurement and process noise) and nonlinearities (e.g., polynomial dynamics), and thus is shown to be applicable to real-world systems. To inform the design of an initial state set when only the target state set is known/specified, a novel algorithm for backward reachability analysis is also provided, which computes the set of states that are guaranteed to lead to the target set. The numerical experiments show that our approach (based on linear relaxations and partitioning) gives a $5\times$ reduction in conservatism in $150\times$ less computation time compared to the state-of-the-art. Furthermore, experiments on quadrotor, 270-state, and polynomial systems demonstrate the method's ability to handle uncertainty sources, high dimensionality, and nonlinear dynamics, respectively.
Efficient Reachability Analysis of Closed-Loop Systems with Neural Network Controllers
Jan 05, 2021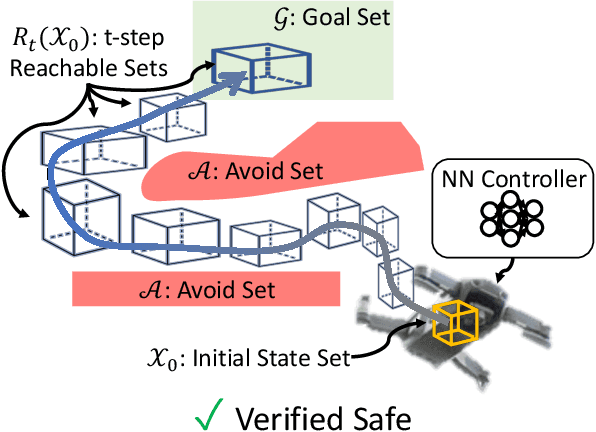
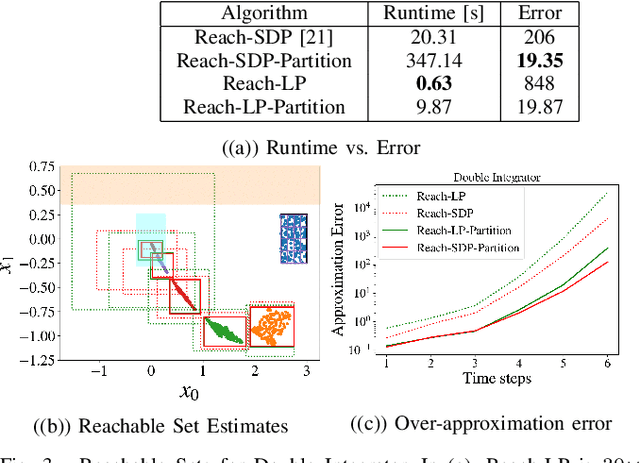
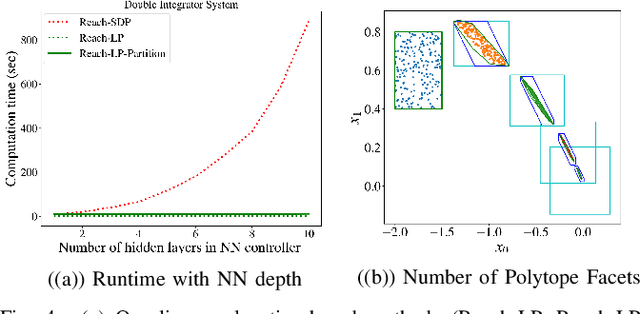
Neural Networks (NNs) can provide major empirical performance improvements for robotic systems, but they also introduce challenges in formally analyzing those systems' safety properties. In particular, this work focuses on estimating the forward reachable set of closed-loop systems with NN controllers. Recent work provides bounds on these reachable sets, yet the computationally efficient approaches provide overly conservative bounds (thus cannot be used to verify useful properties), whereas tighter methods are too intensive for online computation. This work bridges the gap by formulating a convex optimization problem for reachability analysis for closed-loop systems with NN controllers. While the solutions are less tight than prior semidefinite program-based methods, they are substantially faster to compute, and some of the available computation time can be used to refine the bounds through input set partitioning, which more than overcomes the tightness gap. The proposed framework further considers systems with measurement and process noise, thus being applicable to realistic systems with uncertainty. Finally, numerical comparisons show $10\times$ reduction in conservatism in $\frac{1}{2}$ of the computation time compared to the state-of-the-art, and the ability to handle various sources of uncertainty is highlighted on a quadrotor model.
A Policy Gradient Algorithm for Learning to Learn in Multiagent Reinforcement Learning
Oct 31, 2020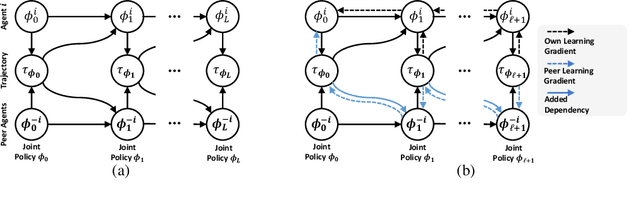
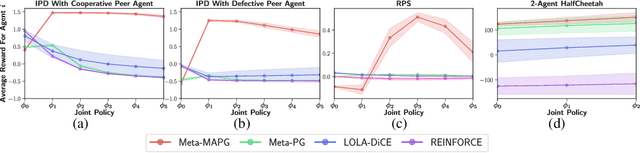

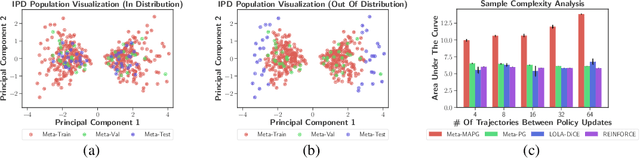
A fundamental challenge in multiagent reinforcement learning is to learn beneficial behaviors in a shared environment with other agents that are also simultaneously learning. In particular, each agent perceives the environment as effectively non-stationary due to the changing policies of other agents. Moreover, each agent is itself constantly learning, leading to natural nonstationarity in the distribution of experiences encountered. In this paper, we propose a novel meta-multiagent policy gradient theorem that directly accommodates for the non-stationary policy dynamics inherent to these multiagent settings. This is achieved by modeling our gradient updates to directly consider both an agent's own non-stationary policy dynamics and the non-stationary policy dynamics of other agents interacting with it in the environment. We find that our theoretically grounded approach provides a general solution to the multiagent learning problem, which inherently combines key aspects of previous state of the art approaches on this topic. We test our method on several multiagent benchmarks and demonstrate a more efficient ability to adapt to new agents as they learn than previous related approaches across the spectrum of mixed incentive, competitive, and cooperative environments.
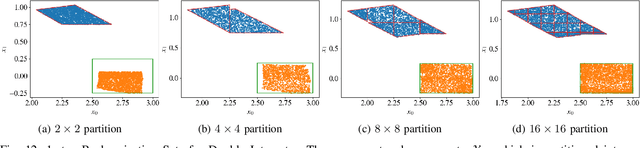
Robustness Analysis of Neural Networks via Efficient Partitioning: Theory and Applications in Control Systems
Oct 01, 2020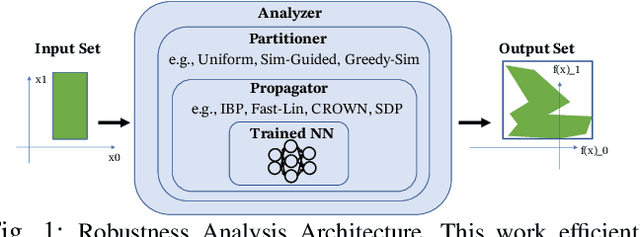
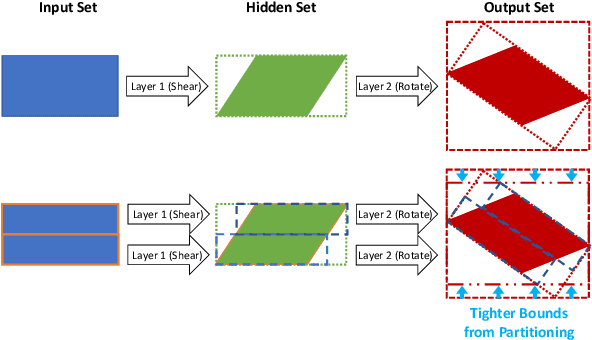
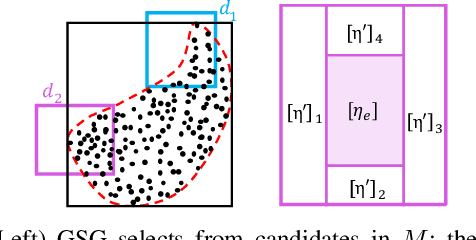
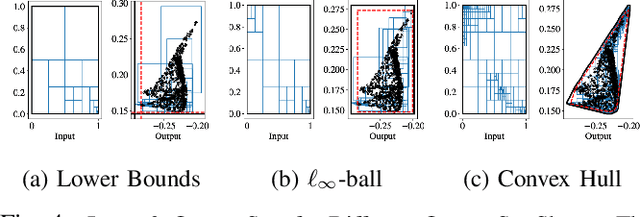
Neural networks (NNs) are now routinely implemented on systems that must operate in uncertain environments, but the tools for formally analyzing how this uncertainty propagates to NN outputs are not yet commonplace. Computing tight bounds on NN output sets (given an input set) provides a measure of confidence associated with the NN decisions and is essential to deploy NNs on safety-critical systems. Recent works approximate the propagation of sets through nonlinear activations or partition the uncertainty set to provide a guaranteed outer bound on the set of possible NN outputs. However, the bound looseness causes excessive conservatism and/or the computation is too slow for online analysis. This paper unifies propagation and partition approaches to provide a family of robustness analysis algorithms that give tighter bounds than existing works for the same amount of computation time (or reduced computational effort for a desired accuracy level). Moreover, we provide new partitioning techniques that are aware of their current bound estimates and desired boundary shape (e.g., lower bounds, weighted $\ell_\infty$-ball, convex hull), leading to further improvements in the computation-tightness tradeoff. The paper demonstrates the tighter bounds and reduced conservatism of the proposed robustness analysis framework with examples from model-free RL and forward kinematics learning.