 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Radiance Fields Approach to Deep Multi-View Photometric Stereo
Oct 11, 2021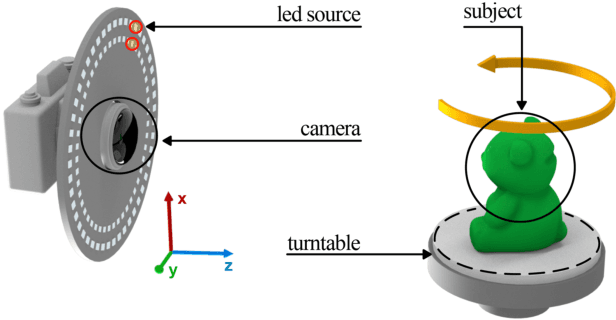

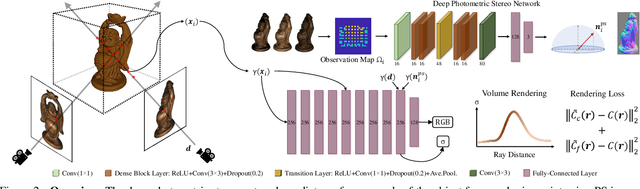
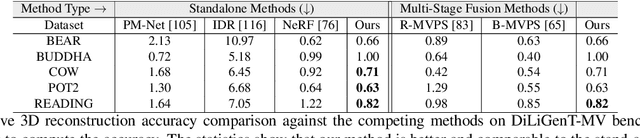
We present a modern solution to the multi-view photometric stereo problem (MVPS). Our work suitably exploits the image formation model in a MVPS experimental setup to recover the dense 3D reconstruction of an object from images. We procure the surface orientation using a photometric stereo (PS) image formation model and blend it with a multi-view neural radiance field representation to recover the object's surface geometry. Contrary to the previous multi-staged framework to MVPS, where the position, iso-depth contours, or orientation measurements are estimated independently and then fused later, our method is simple to implement and realize. Our method performs neural rendering of multi-view images while utilizing surface normals estimated by a deep photometric stereo network. We render the MVPS images by considering the object's surface normals for each 3D sample point along the viewing direction rather than explicitly using the density gradient in the volume space via 3D occupancy information. We optimize the proposed neural radiance field representation for the MVPS setup efficiently using a fully connected deep network to recover the 3D geometry of an object. Extensive evaluation on the DiLiGenT-MV benchmark dataset shows that our method performs better than the approaches that perform only PS or only multi-view stereo (MVS) and provides comparable results against the state-of-the-art multi-stage fusion methods.
Structured Bird's-Eye-View Traffic Scene Understanding from Onboard Images
Oct 05, 2021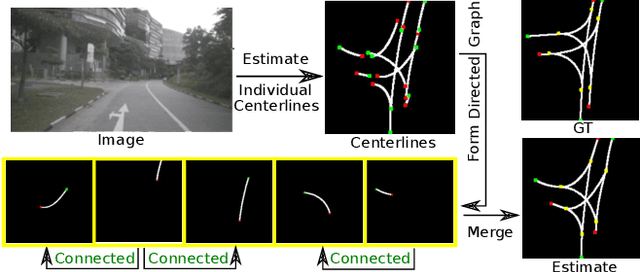
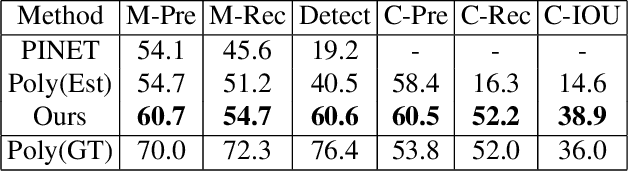
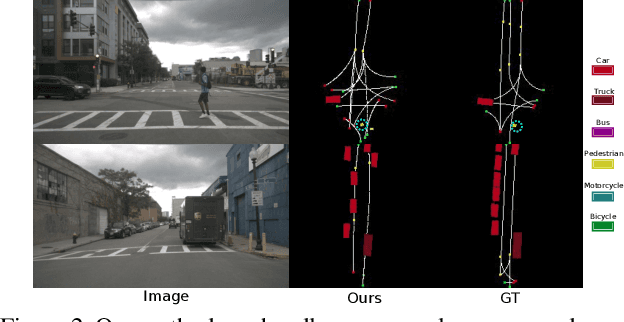
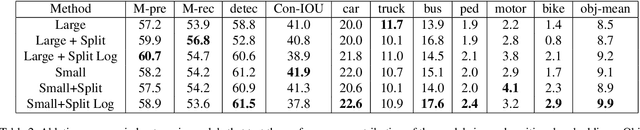
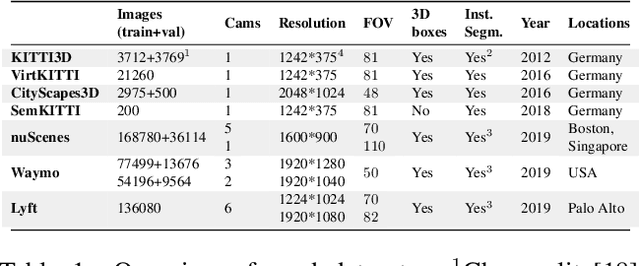
Autonomous navigation requires structured representation of the road network and instance-wise identification of the other traffic agents. Since the traffic scene is defined on the ground plane, this corresponds to scene understanding in the bird's-eye-view (BEV). However, the onboard cameras of autonomous cars are customarily mounted horizontally for a better view of the surrounding, making this task very challenging. In this work, we study the problem of extracting a directed graph representing the local road network in BEV coordinates, from a single onboard camera image. Moreover, we show that the method can be extended to detect dynamic objects on the BEV plane. The semantics, locations, and orientations of the detected objects together with the road graph facilitates a comprehensive understanding of the scene. Such understanding becomes fundamental for the downstream tasks, such as path planning and navigation. We validate our approach against powerful baselines and show that our network achieves superior performance. We also demonstrate the effects of various design choices through ablation studies. Code: https://github.com/ybarancan/STSU
MonoCInIS: Camera Independent Monocular 3D Object Detection using Instance Segmentation
Oct 01, 2021
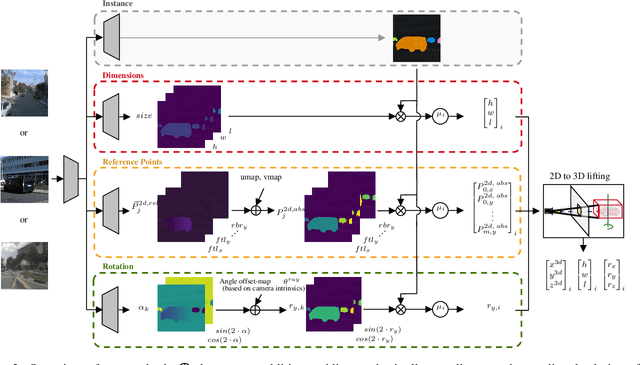
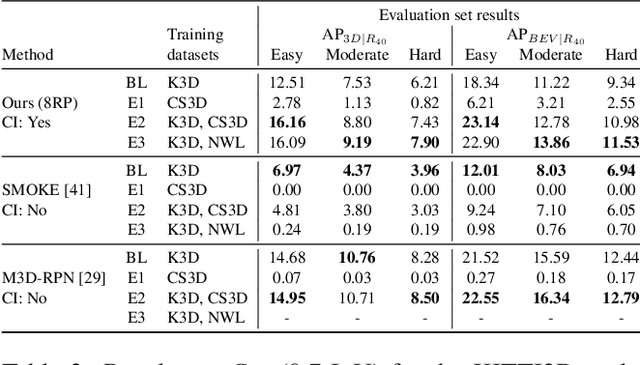
Monocular 3D object detection has recently shown promising results, however there remain challenging problems. One of those is the lack of invariance to different camera intrinsic parameters, which can be observed across different 3D object datasets. Little effort has been made to exploit the combination of heterogeneous 3D object datasets. In contrast to general intuition, we show that more data does not automatically guarantee a better performance, but rather, methods need to have a degree of 'camera independence' in order to benefit from large and heterogeneous training data. In this paper we propose a category-level pose estimation method based on instance segmentation, using camera independent geometric reasoning to cope with the varying camera viewpoints and intrinsics of different datasets. Every pixel of an instance predicts the object dimensions, the 3D object reference points projected in 2D image space and, optionally, the local viewing angle. Camera intrinsics are only used outside of the learned network to lift the predicted 2D reference points to 3D. We surpass camera independent methods on the challenging KITTI3D benchmark and show the key benefits compared to camera dependent methods.
PDC-Net+: Enhanced Probabilistic Dense Correspondence Network
Sep 29, 2021
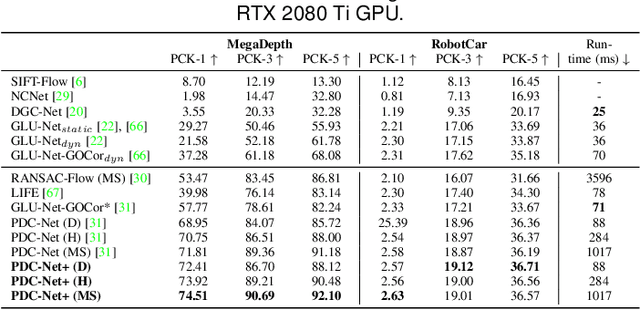
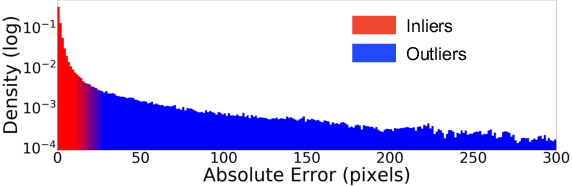
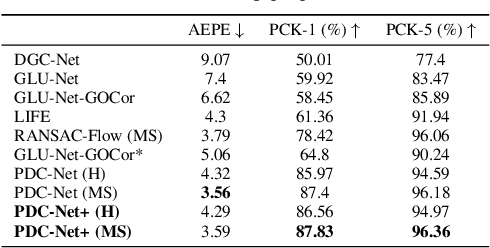
Establishing robust and accurate correspondences between a pair of images is a long-standing computer vision problem with numerous applications. While classically dominated by sparse methods, emerging dense approaches offer a compelling alternative paradigm that avoids the keypoint detection step. However, dense flow estimation is often inaccurate in the case of large displacements, occlusions, or homogeneous regions. In order to apply dense methods to real-world applications, such as pose estimation, image manipulation, or 3D reconstruction, it is therefore crucial to estimate the confidence of the predicted matches. We propose the Enhanced Probabilistic Dense Correspondence Network, PDC-Net+, capable of estimating accurate dense correspondences along with a reliable confidence map. We develop a flexible probabilistic approach that jointly learns the flow prediction and its uncertainty. In particular, we parametrize the predictive distribution as a constrained mixture model, ensuring better modelling of both accurate flow predictions and outliers. Moreover, we develop an architecture and an enhanced training strategy tailored for robust and generalizable uncertainty prediction in the context of self-supervised training. Our approach obtains state-of-the-art results on multiple challenging geometric matching and optical flow datasets. We further validate the usefulness of our probabilistic confidence estimation for the tasks of pose estimation, 3D reconstruction, image-based localization, and image retrieval. Code and models are available at https://github.com/PruneTruong/DenseMatching.
Context-aware Padding for Semantic Segmentation
Sep 16, 2021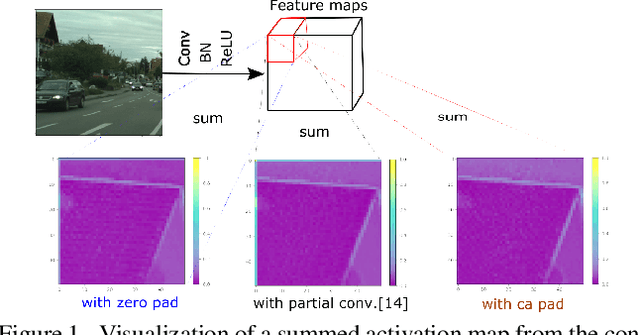

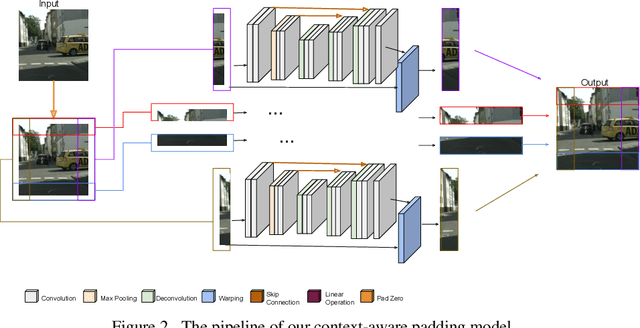

Zero padding is widely used in convolutional neural networks to prevent the size of feature maps diminishing too fast. However, it has been claimed to disturb the statistics at the border. As an alternative, we propose a context-aware (CA) padding approach to extend the image. We reformulate the padding problem as an image extrapolation problem and illustrate the effects on the semantic segmentation task. Using context-aware padding, the ResNet-based segmentation model achieves higher mean Intersection-Over-Union than the traditional zero padding on the Cityscapes and the dataset of DeepGlobe satellite imaging challenge. Furthermore, our padding does not bring noticeable overhead during training and testing.
Perceptual Learned Video Compression with Recurrent Conditional GAN
Sep 13, 2021

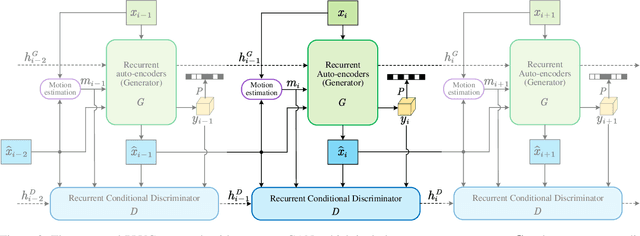
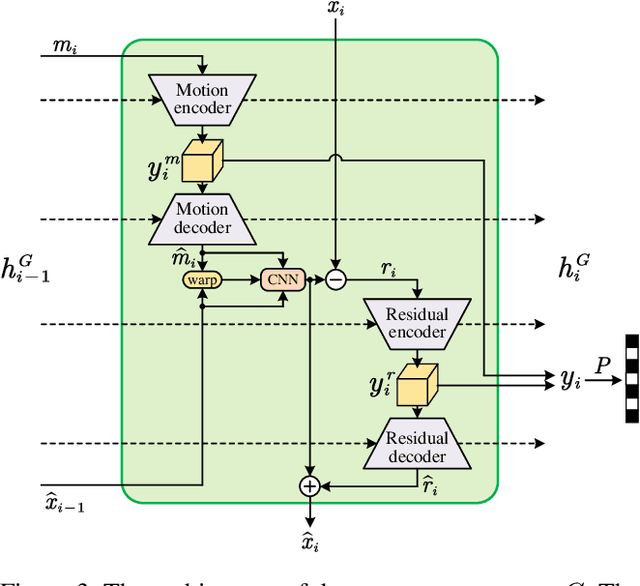
This paper proposes a Perceptual Learned Video Compression (PLVC) approach with recurrent conditional generative adversarial network. In our approach, the recurrent auto-encoder-based generator learns to fully explore the temporal correlation for compressing video. More importantly, we propose a recurrent conditional discriminator, which judges raw and compressed video conditioned on both spatial and temporal information, including the latent representation, temporal motion and hidden states in recurrent cells. This way, in the adversarial training, it pushes the generated video to be not only spatially photo-realistic but also temporally consistent with groundtruth and coherent among video frames. The experimental results show that the proposed PLVC model learns to compress video towards good perceptual quality at low bit-rate, and outperforms the previous traditional and learned approaches on several perceptual quality metrics. The user study further validates the outstanding perceptual performance of PLVC in comparison with the latest learned video compression approaches and the official HEVC test model (HM 16.20). The codes will be released at https://github.com/RenYang-home/PLVC.
TADA: Taxonomy Adaptive Domain Adaptation
Sep 10, 2021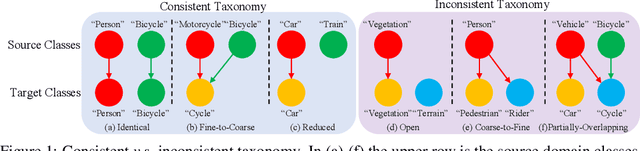
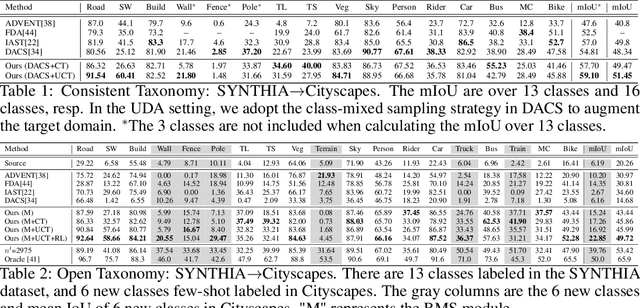
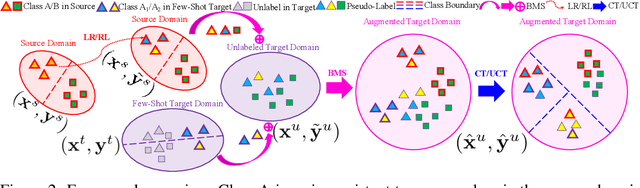
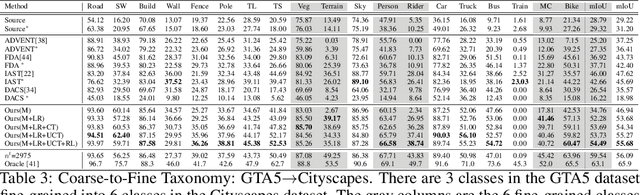
Traditional domain adaptation addresses the task of adapting a model to a novel target domain under limited or no additional supervision. While tackling the input domain gap, the standard domain adaptation settings assume no domain change in the output space. In semantic prediction tasks, different datasets are often labeled according to different semantic taxonomies. In many real-world settings, the target domain task requires a different taxonomy than the one imposed by the source domain. We therefore introduce the more general taxonomy adaptive domain adaptation (TADA) problem, allowing for inconsistent taxonomies between the two domains. We further propose an approach that jointly addresses the image-level and label-level domain adaptation. On the label-level, we employ a bilateral mixed sampling strategy to augment the target domain, and a relabelling method to unify and align the label spaces. We address the image-level domain gap by proposing an uncertainty-rectified contrastive learning method, leading to more domain-invariant and class discriminative features. We extensively evaluate the effectiveness of our framework under different TADA settings: open taxonomy, coarse-to-fine taxonomy, and partially-overlapping taxonomy. Our framework outperforms previous state-of-the-art by a large margin, while capable of adapting to new target domain taxonomies.
Binaural SoundNet: Predicting Semantics, Depth and Motion with Binaural Sounds
Sep 06, 2021
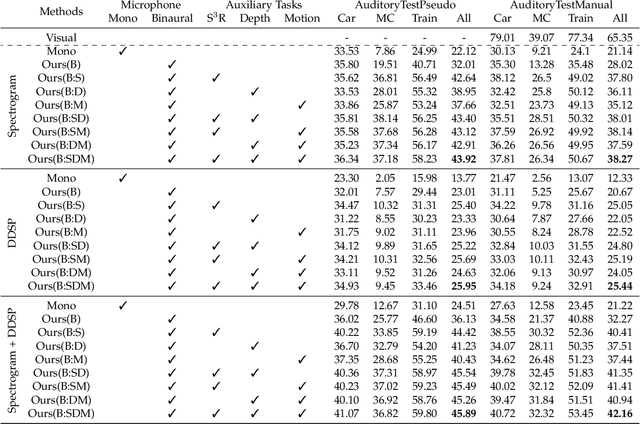
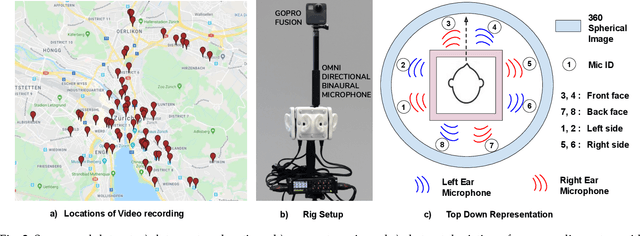
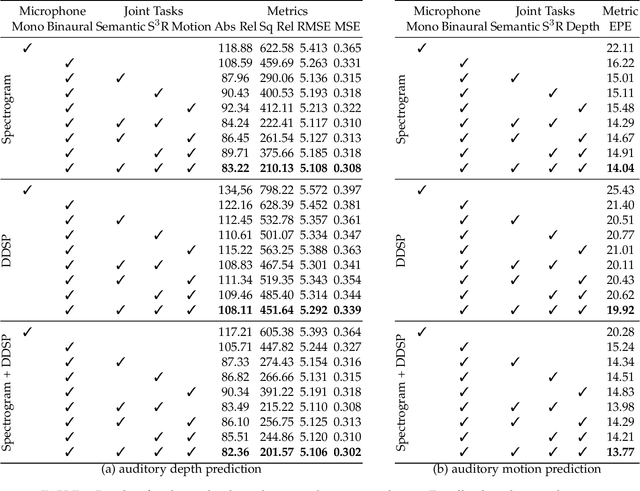
Humans can robustly recognize and localize objects by using visual and/or auditory cues. While machines are able to do the same with visual data already, less work has been done with sounds. This work develops an approach for scene understanding purely based on binaural sounds. The considered tasks include predicting the semantic masks of sound-making objects, the motion of sound-making objects, and the depth map of the scene. To this aim, we propose a novel sensor setup and record a new audio-visual dataset of street scenes with eight professional binaural microphones and a 360-degree camera. The co-existence of visual and audio cues is leveraged for supervision transfer. In particular, we employ a cross-modal distillation framework that consists of multiple vision teacher methods and a sound student method -- the student method is trained to generate the same results as the teacher methods do. This way, the auditory system can be trained without using human annotations. To further boost the performance, we propose another novel auxiliary task, coined Spatial Sound Super-Resolution, to increase the directional resolution of sounds. We then formulate the four tasks into one end-to-end trainable multi-tasking network aiming to boost the overall performance. Experimental results show that 1) our method achieves good results for all four tasks, 2) the four tasks are mutually beneficial -- training them together achieves the best performance, 3) the number and orientation of microphones are both important, and 4) features learned from the standard spectrogram and features obtained by the classic signal processing pipeline are complementary for auditory perception tasks. The data and code are released.
Improving Semi-Supervised and Domain-Adaptive Semantic Segmentation with Self-Supervised Depth Estimation
Aug 28, 2021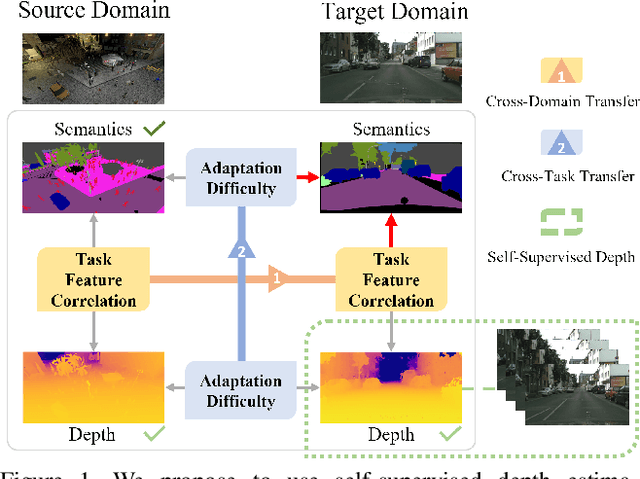

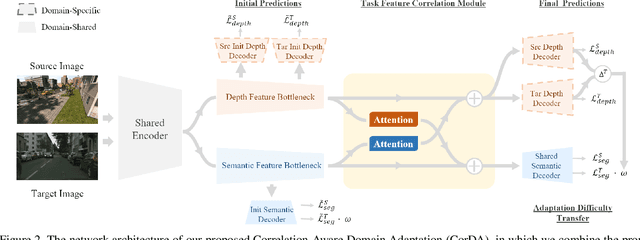
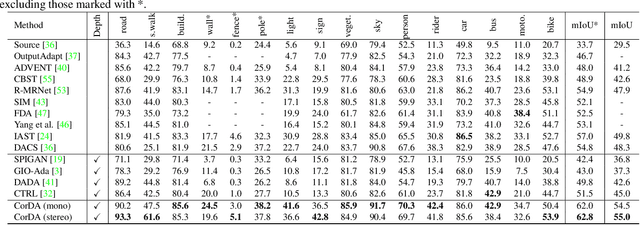
Training deep networks for semantic segmentation requires large amounts of labeled training data, which presents a major challenge in practice, as labeling segmentation masks is a highly labor-intensive process. To address this issue, we present a framework for semi-supervised and domain-adaptive semantic segmentation, which is enhanced by self-supervised monocular depth estimation (SDE) trained only on unlabeled image sequences. In particular, we utilize SDE as an auxiliary task comprehensively across the entire learning framework: First, we automatically select the most useful samples to be annotated for semantic segmentation based on the correlation of sample diversity and difficulty between SDE and semantic segmentation. Second, we implement a strong data augmentation by mixing images and labels using the geometry of the scene. Third, we transfer knowledge from features learned during SDE to semantic segmentation by means of transfer and multi-task learning. And fourth, we exploit additional labeled synthetic data with Cross-Domain DepthMix and Matching Geometry Sampling to align synthetic and real data. We validate the proposed model on the Cityscapes dataset, where all four contributions demonstrate significant performance gains, and achieve state-of-the-art results for semi-supervised semantic segmentation as well as for semi-supervised domain adaptation. In particular, with only 1/30 of the Cityscapes labels, our method achieves 92% of the fully-supervised baseline performance and even 97% when exploiting additional data from GTA. The source code is available at https://github.com/lhoyer/improving_segmentation_with_selfsupervised_depth.
End-to-End Urban Driving by Imitating a Reinforcement Learning Coach
Aug 26, 2021End-to-end approaches to autonomous driving commonly rely on expert demonstrations. Although humans are good drivers, they are not good coaches for end-to-end algorithms that demand dense on-policy supervision. On the contrary, automated experts that leverage privileged information can efficiently generate large scale on-policy and off-policy demonstrations. However, existing automated experts for urban driving make heavy use of hand-crafted rules and perform suboptimally even on driving simulators, where ground-truth information is available. To address these issues, we train a reinforcement learning expert that maps bird's-eye view images to continuous low-level actions. While setting a new performance upper-bound on CARLA, our expert is also a better coach that provides informative supervision signals for imitation learning agents to learn from. Supervised by our reinforcement learning coach, a baseline end-to-end agent with monocular camera-input achieves expert-level performance. Our end-to-end agent achieves a 78% success rate while generalizing to a new town and new weather on the NoCrash-dense benchmark and state-of-the-art performance on the more challenging CARLA LeaderBoard.