 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSA-VIS: Sparse frame Annotations for training Video Instance Segmentation
Jun 18, 2026Recent online video instance segmentation (VIS) methods have achieved impressive results, thus becoming the preferred approach to segment instances in videos. Despite the resurgence of impressive single image models, the online (or semi-online) VIS approaches outperform single-image models (e.g., based on SAM) by using long sequences of densely annotated frames during training. However,such a training setup of VIS is expensive in the sense of compute as well as dense annotations required. In order to solve these major flaws, we argue that the effective modeling of the instances and their evolution in videos do not require densely annotated frames. To that end, we propose a simple and effective module, called Past-frames Feature Propagation (PFP) which aggregates low-dimensional features from the image encoder of multiple frames. This simple low-compute module provides tremendous learning capability in using sparse video frame labels for end-to-end training. Combined with a light-weight frame-specific Instance Queries, our Sparse frame Annotation VIS (SA-VIS) significantly improves performance over its baseline. Most interestingly, our simple design that avoids complexities effectively bridges the gap in accuracy between training on sparsely and densely annotated video sequences. This translates to a mere 0.4% drop in performance of SA-VIS when using annotations for only 1/5 of the images in the dataset. Empirically, SA-VIS shows strong improvements over the baseline on YouTube-VIS 2019/2021/2022 and Occluded VIS (OVIS) and an over 1% improvement in AP on the state-of-the-art in a limited annotations scenario.
Scaling Semantic Segmentation Beyond 1K Classes on a Single GPU
Dec 14, 2020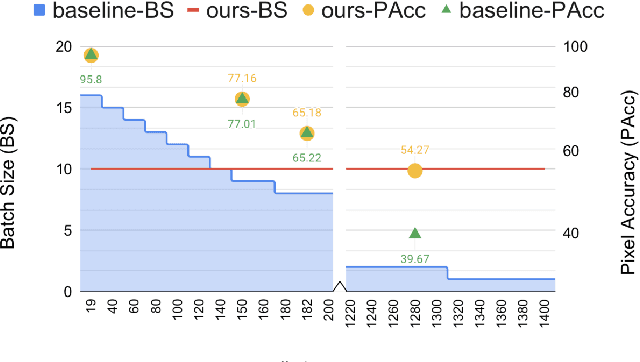
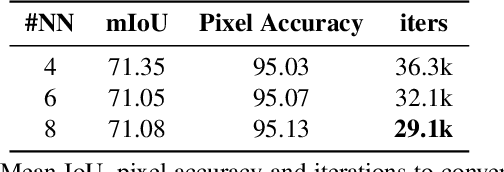
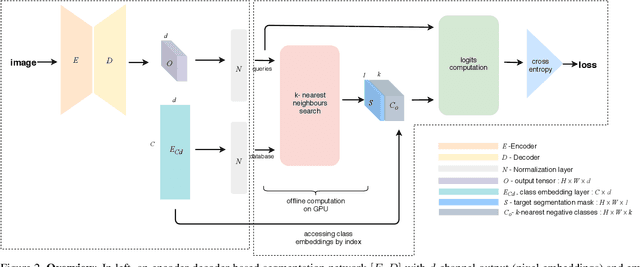

The state-of-the-art object detection and image classification methods can perform impressively on more than 9k and 10k classes, respectively. In contrast, the number of classes in semantic segmentation datasets is relatively limited. This is not surprising when the restrictions caused by the lack of labeled data and high computation demand for segmentation are considered. In this paper, we propose a novel training methodology to train and scale the existing semantic segmentation models for a large number of semantic classes without increasing the memory overhead. In our embedding-based scalable segmentation approach, we reduce the space complexity of the segmentation model's output from O(C) to O(1), propose an approximation method for ground-truth class probability, and use it to compute cross-entropy loss. The proposed approach is general and can be adopted by any state-of-the-art segmentation model to gracefully scale it for any number of semantic classes with only one GPU. Our approach achieves similar, and in some cases, even better mIoU for Cityscapes, Pascal VOC, ADE20k, COCO-Stuff10k datasets when adopted to DeeplabV3+ model with different backbones. We demonstrate a clear benefit of our approach on a dataset with 1284 classes, bootstrapped from LVIS and COCO annotations, with three times better mIoU than the DeeplabV3+ model.