 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFocal Self-attention for Local-Global Interactions in Vision Transformers
Jul 01, 2021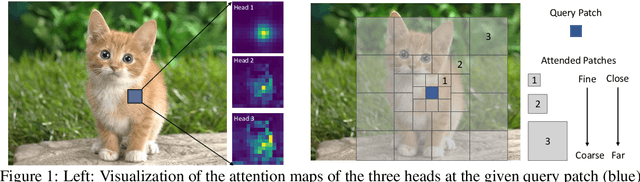
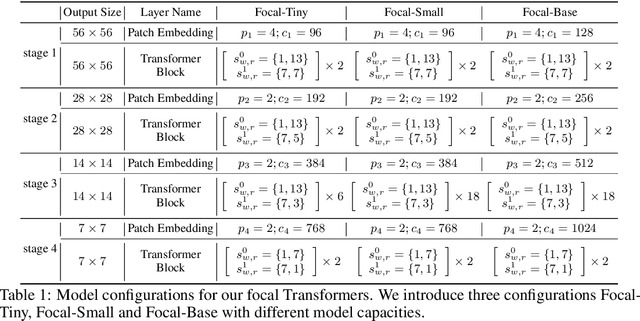
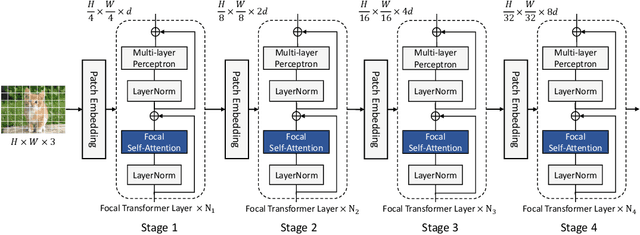
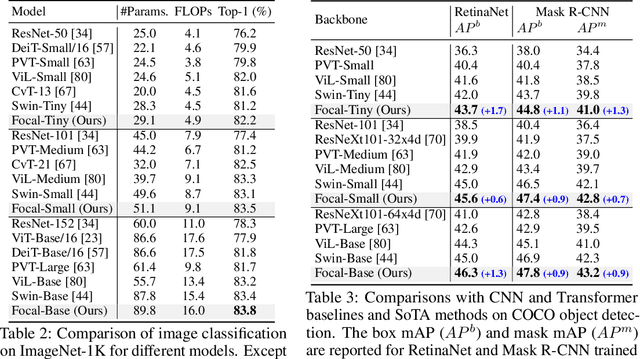
Recently, Vision Transformer and its variants have shown great promise on various computer vision tasks. The ability of capturing short- and long-range visual dependencies through self-attention is arguably the main source for the success. But it also brings challenges due to quadratic computational overhead, especially for the high-resolution vision tasks (e.g., object detection). In this paper, we present focal self-attention, a new mechanism that incorporates both fine-grained local and coarse-grained global interactions. Using this new mechanism, each token attends the closest surrounding tokens at fine granularity but the tokens far away at coarse granularity, and thus can capture both short- and long-range visual dependencies efficiently and effectively. With focal self-attention, we propose a new variant of Vision Transformer models, called Focal Transformer, which achieves superior performance over the state-of-the-art vision Transformers on a range of public image classification and object detection benchmarks. In particular, our Focal Transformer models with a moderate size of 51.1M and a larger size of 89.8M achieve 83.5 and 83.8 Top-1 accuracy, respectively, on ImageNet classification at 224x224 resolution. Using Focal Transformers as the backbones, we obtain consistent and substantial improvements over the current state-of-the-art Swin Transformers for 6 different object detection methods trained with standard 1x and 3x schedules. Our largest Focal Transformer yields 58.7/58.9 box mAPs and 50.9/51.3 mask mAPs on COCO mini-val/test-dev, and 55.4 mIoU on ADE20K for semantic segmentation, creating new SoTA on three of the most challenging computer vision tasks.
Efficient Self-supervised Vision Transformers for Representation Learning
Jun 17, 2021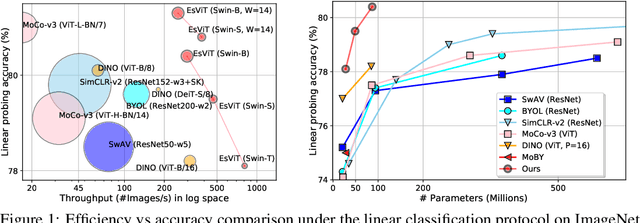
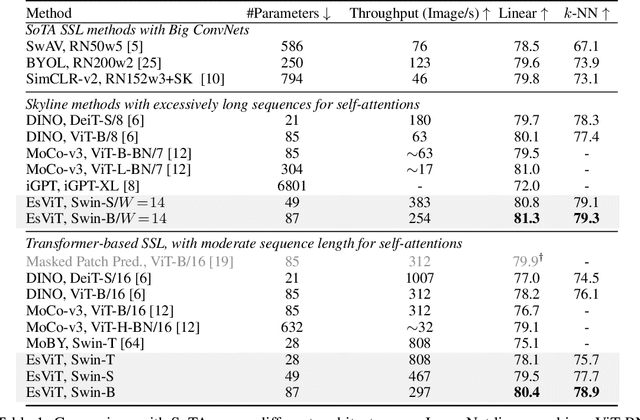
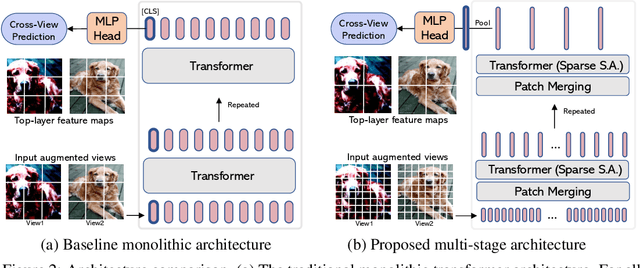

This paper investigates two techniques for developing efficient self-supervised vision transformers (EsViT) for visual representation learning. First, we show through a comprehensive empirical study that multi-stage architectures with sparse self-attentions can significantly reduce modeling complexity but with a cost of losing the ability to capture fine-grained correspondences between image regions. Second, we propose a new pre-training task of region matching which allows the model to capture fine-grained region dependencies and as a result significantly improves the quality of the learned vision representations. Our results show that combining the two techniques, EsViT achieves 81.3% top-1 on the ImageNet linear probe evaluation, outperforming prior arts with around an order magnitude of higher throughput. When transferring to downstream linear classification tasks, EsViT outperforms its supervised counterpart on 17 out of 18 datasets. The code and models will be publicly available.
Dynamic Head: Unifying Object Detection Heads with Attentions
Jun 15, 2021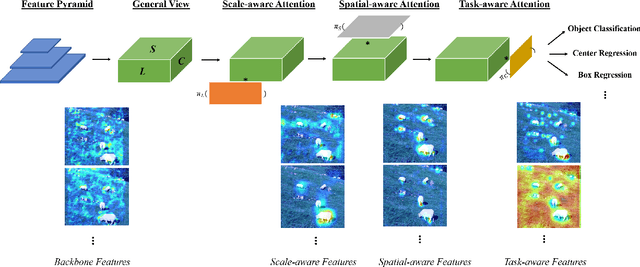
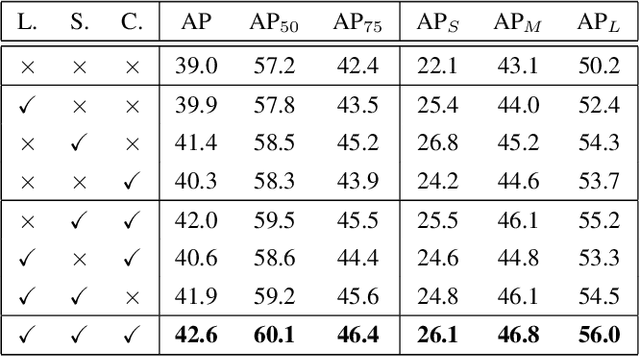
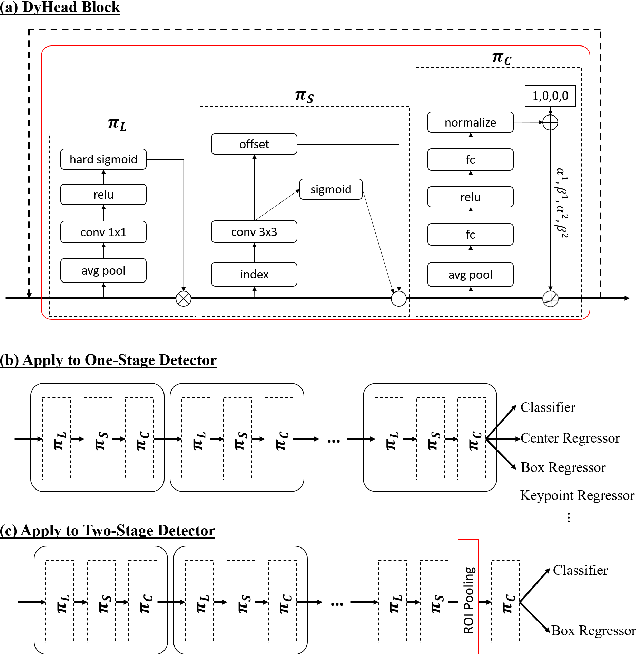
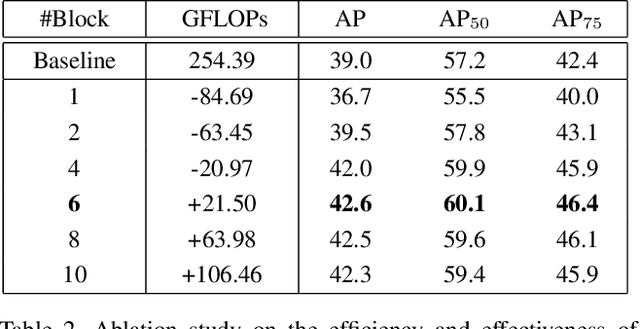
The complex nature of combining localization and classification in object detection has resulted in the flourished development of methods. Previous works tried to improve the performance in various object detection heads but failed to present a unified view. In this paper, we present a novel dynamic head framework to unify object detection heads with attentions. By coherently combining multiple self-attention mechanisms between feature levels for scale-awareness, among spatial locations for spatial-awareness, and within output channels for task-awareness, the proposed approach significantly improves the representation ability of object detection heads without any computational overhead. Further experiments demonstrate that the effectiveness and efficiency of the proposed dynamic head on the COCO benchmark. With a standard ResNeXt-101-DCN backbone, we largely improve the performance over popular object detectors and achieve a new state-of-the-art at 54.0 AP. Furthermore, with latest transformer backbone and extra data, we can push current best COCO result to a new record at 60.6 AP. The code will be released at https://github.com/microsoft/DynamicHead.
Chasing Sparsity in Vision Transformers: An End-to-End Exploration
Jun 09, 2021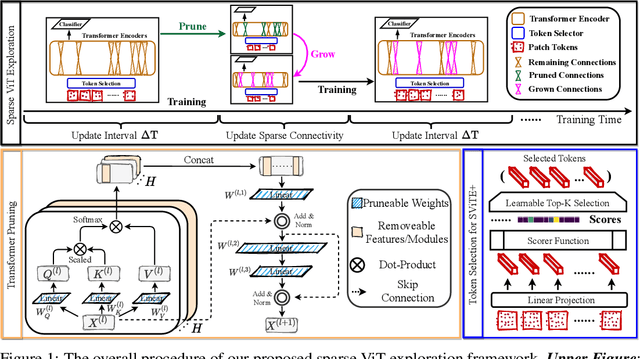

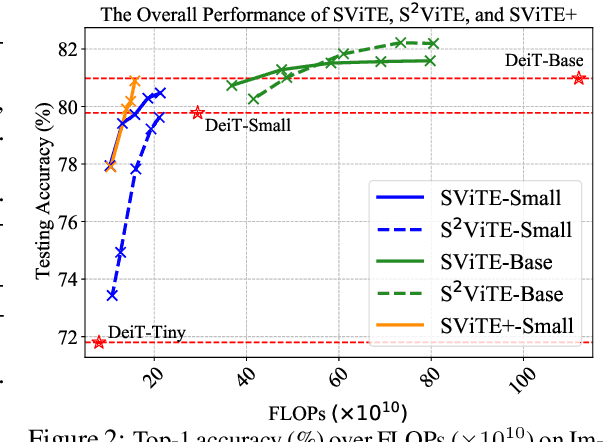
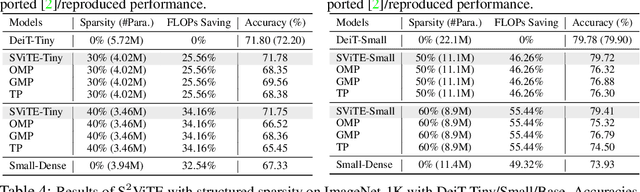
Vision transformers (ViTs) have recently received explosive popularity, but their enormous model sizes and training costs remain daunting. Conventional post-training pruning often incurs higher training budgets. In contrast, this paper aims to trim down both the training memory overhead and the inference complexity, without sacrificing the achievable accuracy. We launch and report the first-of-its-kind comprehensive exploration, on taking a unified approach of integrating sparsity in ViTs "from end to end". Specifically, instead of training full ViTs, we dynamically extract and train sparse subnetworks, while sticking to a fixed small parameter budget. Our approach jointly optimizes model parameters and explores connectivity throughout training, ending up with one sparse network as the final output. The approach is seamlessly extended from unstructured to structured sparsity, the latter by considering to guide the prune-and-grow of self-attention heads inside ViTs. For additional efficiency gains, we further co-explore data and architecture sparsity, by plugging in a novel learnable token selector to adaptively determine the currently most vital patches. Extensive results on ImageNet with diverse ViT backbones validate the effectiveness of our proposals which obtain significantly reduced computational cost and almost unimpaired generalization. Perhaps most surprisingly, we find that the proposed sparse (co-)training can even improve the ViT accuracy rather than compromising it, making sparsity a tantalizing "free lunch". For example, our sparsified DeiT-Small at (5%, 50%) sparsity for (data, architecture), improves 0.28% top-1 accuracy, and meanwhile enjoys 49.32% FLOPs and 4.40% running time savings. Our codes are available at https://github.com/VITA-Group/SViTE.
A Simple Baseline for StyleGAN Inversion
Apr 15, 2021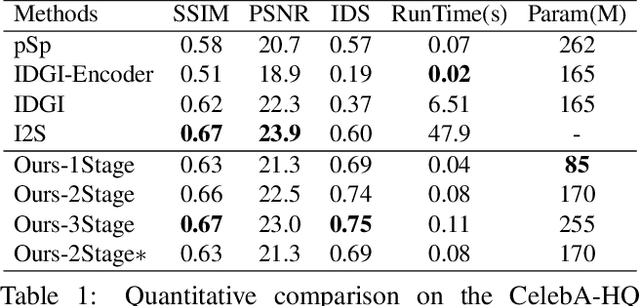
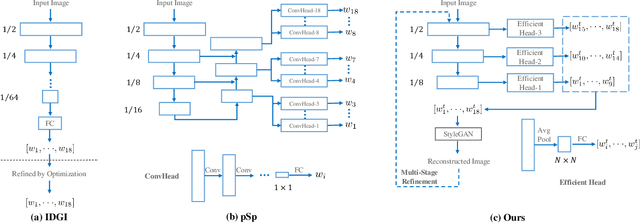

This paper studies the problem of StyleGAN inversion, which plays an essential role in enabling the pretrained StyleGAN to be used for real facial image editing tasks. This problem has the high demand for quality and efficiency. Existing optimization-based methods can produce high quality results, but the optimization often takes a long time. On the contrary, forward-based methods are usually faster but the quality of their results is inferior. In this paper, we present a new feed-forward network for StyleGAN inversion, with significant improvement in terms of efficiency and quality. In our inversion network, we introduce: 1) a shallower backbone with multiple efficient heads across scales; 2) multi-layer identity loss and multi-layer face parsing loss to the loss function; and 3) multi-stage refinement. Combining these designs together forms a simple and efficient baseline method which exploits all benefits of optimization-based and forward-based methods. Quantitative and qualitative results show that our method performs better than existing forward-based methods and comparably to state-of-the-art optimization-based methods, while maintaining the high efficiency as well as forward-based methods. Moreover, a number of real image editing applications demonstrate the efficacy of our method. Our project page is ~\url{https://wty-ustc.github.io/inversion}.
Lite-HRNet: A Lightweight High-Resolution Network
Apr 13, 2021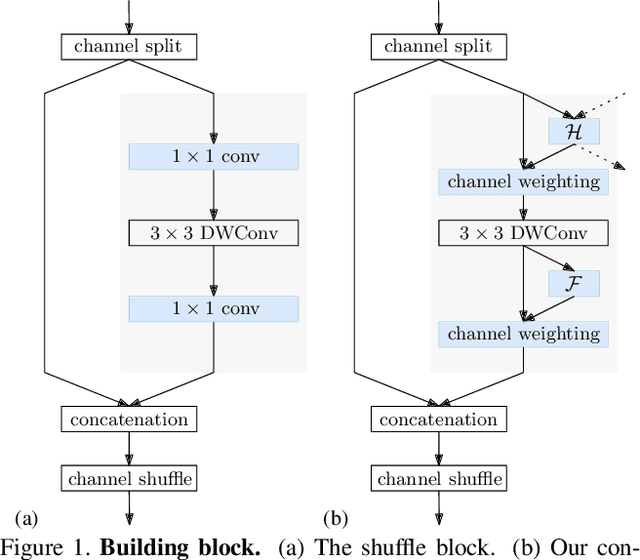
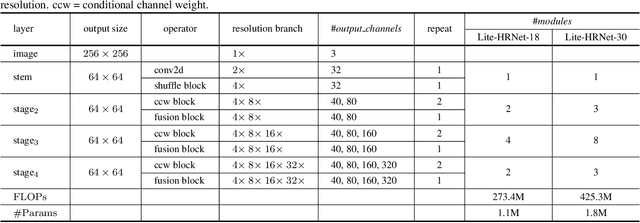
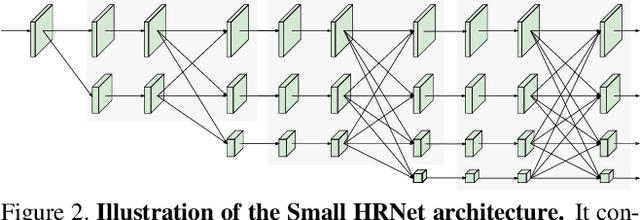

We present an efficient high-resolution network, Lite-HRNet, for human pose estimation. We start by simply applying the efficient shuffle block in ShuffleNet to HRNet (high-resolution network), yielding stronger performance over popular lightweight networks, such as MobileNet, ShuffleNet, and Small HRNet. We find that the heavily-used pointwise (1x1) convolutions in shuffle blocks become the computational bottleneck. We introduce a lightweight unit, conditional channel weighting, to replace costly pointwise (1x1) convolutions in shuffle blocks. The complexity of channel weighting is linear w.r.t the number of channels and lower than the quadratic time complexity for pointwise convolutions. Our solution learns the weights from all the channels and over multiple resolutions that are readily available in the parallel branches in HRNet. It uses the weights as the bridge to exchange information across channels and resolutions, compensating the role played by the pointwise (1x1) convolution. Lite-HRNet demonstrates superior results on human pose estimation over popular lightweight networks. Moreover, Lite-HRNet can be easily applied to semantic segmentation task in the same lightweight manner. The code and models have been publicly available at https://github.com/HRNet/Lite-HRNet.
CvT: Introducing Convolutions to Vision Transformers
Mar 29, 2021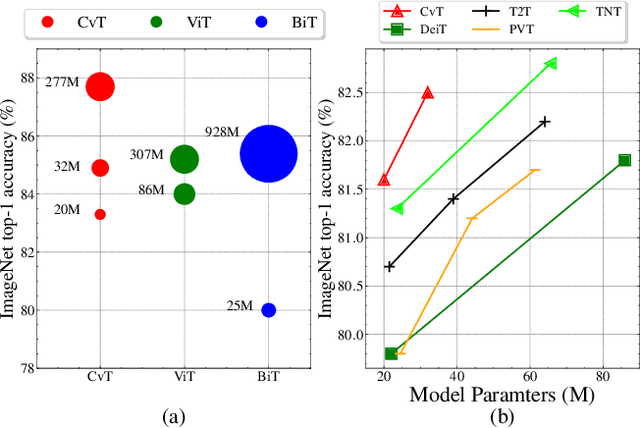

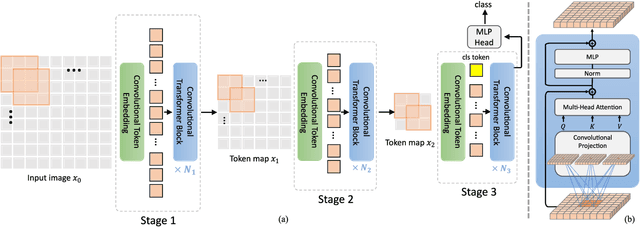

We present in this paper a new architecture, named Convolutional vision Transformer (CvT), that improves Vision Transformer (ViT) in performance and efficiency by introducing convolutions into ViT to yield the best of both designs. This is accomplished through two primary modifications: a hierarchy of Transformers containing a new convolutional token embedding, and a convolutional Transformer block leveraging a convolutional projection. These changes introduce desirable properties of convolutional neural networks (CNNs) to the ViT architecture (\ie shift, scale, and distortion invariance) while maintaining the merits of Transformers (\ie dynamic attention, global context, and better generalization). We validate CvT by conducting extensive experiments, showing that this approach achieves state-of-the-art performance over other Vision Transformers and ResNets on ImageNet-1k, with fewer parameters and lower FLOPs. In addition, performance gains are maintained when pretrained on larger datasets (\eg ImageNet-22k) and fine-tuned to downstream tasks. Pre-trained on ImageNet-22k, our CvT-W24 obtains a top-1 accuracy of 87.7\% on the ImageNet-1k val set. Finally, our results show that the positional encoding, a crucial component in existing Vision Transformers, can be safely removed in our model, simplifying the design for higher resolution vision tasks. Code will be released at \url{https://github.com/leoxiaobin/CvT}.
Multi-Scale Vision Longformer: A New Vision Transformer for High-Resolution Image Encoding
Mar 29, 2021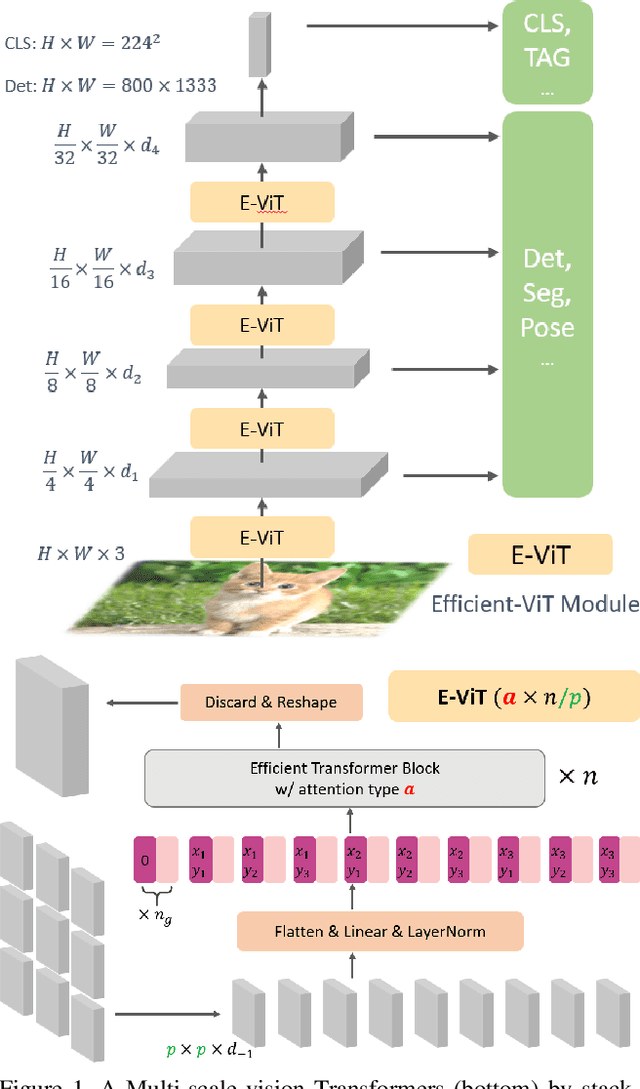
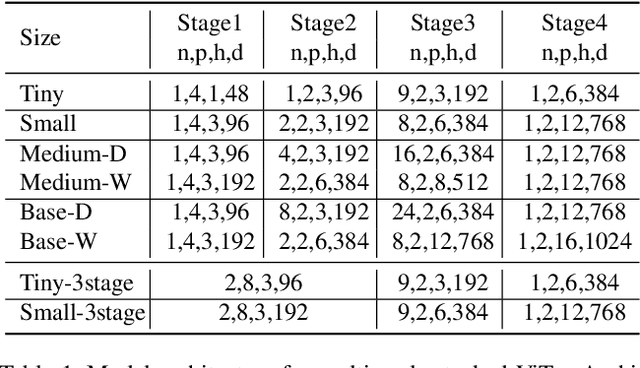
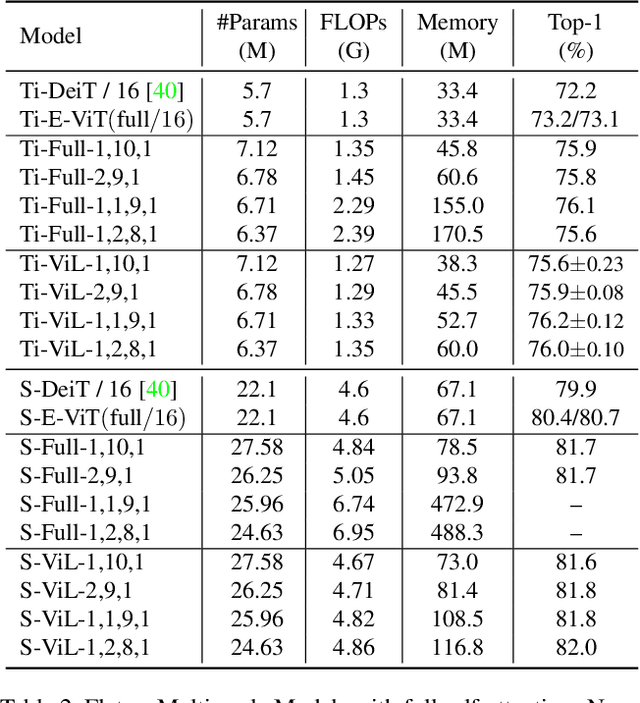
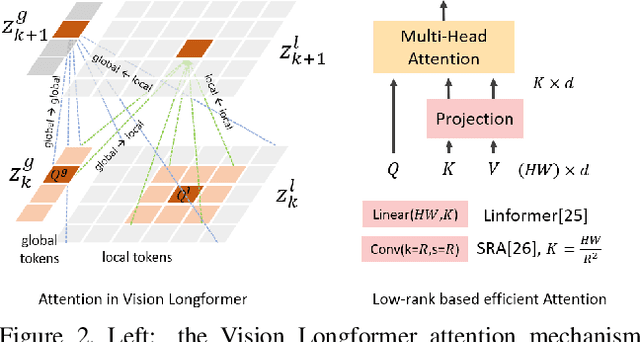
This paper presents a new Vision Transformer (ViT) architecture Multi-Scale Vision Longformer, which significantly enhances the ViT of \cite{dosovitskiy2020image} for encoding high-resolution images using two techniques. The first is the multi-scale model structure, which provides image encodings at multiple scales with manageable computational cost. The second is the attention mechanism of vision Longformer, which is a variant of Longformer \cite{beltagy2020longformer}, originally developed for natural language processing, and achieves a linear complexity w.r.t. the number of input tokens. A comprehensive empirical study shows that the new ViT significantly outperforms several strong baselines, including the existing ViT models and their ResNet counterparts, and the Pyramid Vision Transformer from a concurrent work \cite{wang2021pyramid}, on a range of vision tasks, including image classification, object detection, and segmentation. The models and source code used in this study will be released to public soon.
Dynamic Transfer for Multi-Source Domain Adaptation
Mar 19, 2021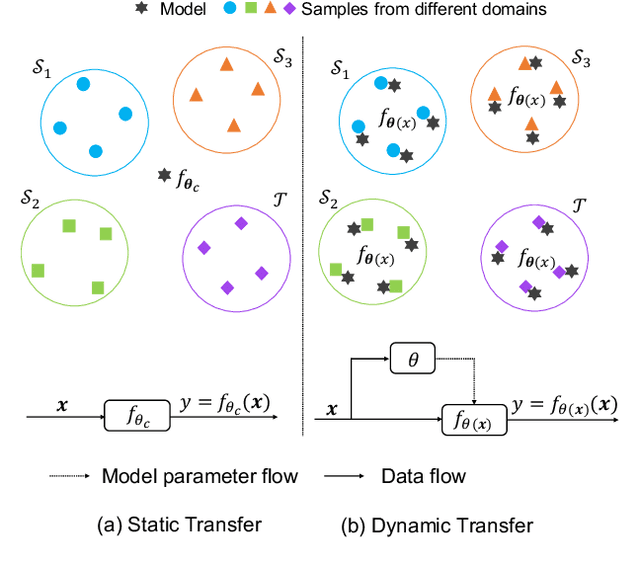

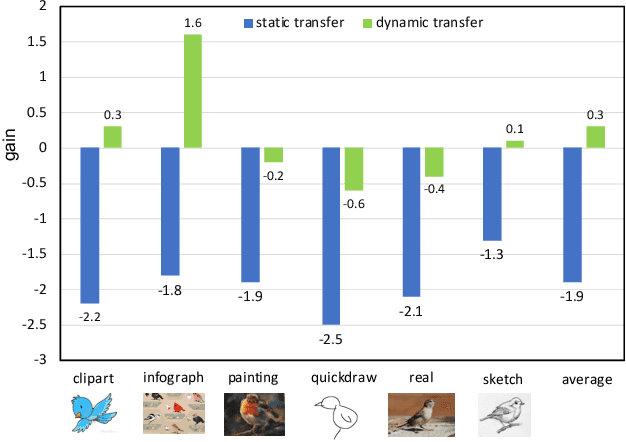
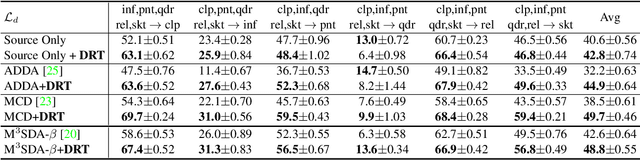
Recent works of multi-source domain adaptation focus on learning a domain-agnostic model, of which the parameters are static. However, such a static model is difficult to handle conflicts across multiple domains, and suffers from a performance degradation in both source domains and target domain. In this paper, we present dynamic transfer to address domain conflicts, where the model parameters are adapted to samples. The key insight is that adapting model across domains is achieved via adapting model across samples. Thus, it breaks down source domain barriers and turns multi-source domains into a single-source domain. This also simplifies the alignment between source and target domains, as it only requires the target domain to be aligned with any part of the union of source domains. Furthermore, we find dynamic transfer can be simply modeled by aggregating residual matrices and a static convolution matrix. Experimental results show that, without using domain labels, our dynamic transfer outperforms the state-of-the-art method by more than 3% on the large multi-source domain adaptation datasets -- DomainNet. Source code is at https://github.com/liyunsheng13/DRT.
Revisiting Dynamic Convolution via Matrix Decomposition
Mar 15, 2021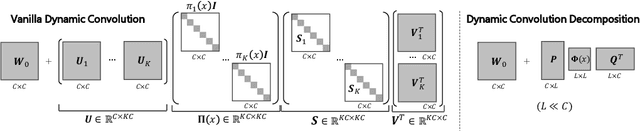

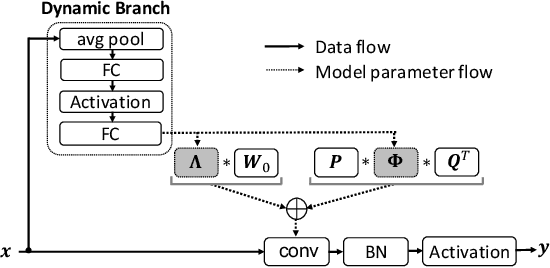
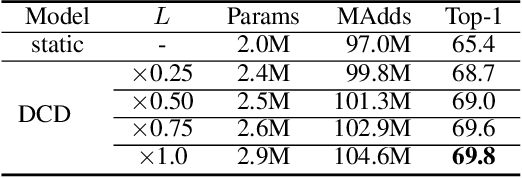
Recent research in dynamic convolution shows substantial performance boost for efficient CNNs, due to the adaptive aggregation of K static convolution kernels. It has two limitations: (a) it increases the number of convolutional weights by K-times, and (b) the joint optimization of dynamic attention and static convolution kernels is challenging. In this paper, we revisit it from a new perspective of matrix decomposition and reveal the key issue is that dynamic convolution applies dynamic attention over channel groups after projecting into a higher dimensional latent space. To address this issue, we propose dynamic channel fusion to replace dynamic attention over channel groups. Dynamic channel fusion not only enables significant dimension reduction of the latent space, but also mitigates the joint optimization difficulty. As a result, our method is easier to train and requires significantly fewer parameters without sacrificing accuracy. Source code is at https://github.com/liyunsheng13/dcd.