 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforce to Learn, Elect to Reason: A Dual Paradigm for Video Reasoning
Apr 06, 2026Video reasoning has advanced with large multimodal models (LMMs), yet their inference is often a single pass that returns an answer without verifying whether the reasoning is evidence-aligned. We introduce Reinforce to Learn, Elect to Reason (RLER), a dual paradigm that decouples learning to produce evidence from obtaining a reliable answer. In RLER-Training, we optimize the policy with group-relative reinforcement learning (RL) and 3 novel task-driven rewards: Frame-sensitive reward grounds reasoning on explicit key frames, Think-transparency reward shapes readable and parsable reasoning traces, and Anti-repetition reward boosts information density. These signals teach the model to emit structured, machine-checkable evidence and potentiate reasoning capabilities. In RLER-Inference, we apply a train-free orchestrator that generates a small set of diverse candidates, parses their answers and cited frames, scores them by evidence consistency, confidence, transparency, and non-redundancy, and then performs a robust evidence-weighted election. This closes the loop between producing and using evidence, improving reliability and interpretability without enlarging the model. We comprehensively evaluate RLER against various open-source and RL-based LMMs on 8 representative benchmarks. RLER achieves state of the art across all benchmarks and delivers an average improvement of 6.3\% over base models, while using on average 3.1 candidates per question, indicating a favorable balance between compute and quality. The results support a simple thesis: making evidence explicit during learning and electing by evidence during inference is a robust path to trustworthy video reasoning.
Graph-to-Frame RAG: Visual-Space Knowledge Fusion for Training-Free and Auditable Video Reasoning
Apr 06, 2026When video reasoning requires external knowledge, many systems with large multimodal models (LMMs) adopt retrieval augmentation to supply the missing context. Appending textual or multi-clip evidence, however, forces heterogeneous signals into a single attention space. We observe diluted attention and higher cognitive load even on non-long videos. The bottleneck is not only what to retrieve but how to represent and fuse external knowledge with the video backbone.We present Graph-to-Frame RAG (G2F-RAG), a training free and auditable paradigm that delivers knowledge in the visual space. On the offline stage, an agent builds a problem-agnostic video knowledge graph that integrates entities, events, spatial relations, and linked world knowledge. On the online stage, a hierarchical multi-agent controller decides whether external knowledge is needed, retrieves a minimal sufficient subgraph, and renders it as a single reasoning frame appended to the video. LMMs then perform joint reasoning in a unified visual domain. This design reduces cognitive load and leaves an explicit, inspectable evidence trail.G2F-RAG is plug-and-play across backbones and scales. It yields consistent gains on diverse public benchmarks, with larger improvements in knowledge-intensive settings. Ablations further confirm that knowledge representation and delivery matter. G2F-RAG reframes retrieval as visual space knowledge fusion for robust and interpretable video reasoning.
AnyUser: Translating Sketched User Intent into Domestic Robots
Apr 06, 2026We introduce AnyUser, a unified robotic instruction system for intuitive domestic task instruction via free-form sketches on camera images, optionally with language. AnyUser interprets multimodal inputs (sketch, vision, language) as spatial-semantic primitives to generate executable robot actions requiring no prior maps or models. Novel components include multimodal fusion for understanding and a hierarchical policy for robust action generation. Efficacy is shown via extensive evaluations: (1) Quantitative benchmarks on the large-scale dataset showing high accuracy in interpreting diverse sketch-based commands across various simulated domestic scenes. (2) Real-world validation on two distinct robotic platforms, a statically mounted 7-DoF assistive arm (KUKA LBR iiwa) and a dual-arm mobile manipulator (Realman RMC-AIDAL), performing representative tasks like targeted wiping and area cleaning, confirming the system's ability to ground instructions and execute them reliably in physical environments. (3) A comprehensive user study involving diverse demographics (elderly, simulated non-verbal, low technical literacy) demonstrating significant improvements in usability and task specification efficiency, achieving high task completion rates (85.7%-96.4%) and user satisfaction. AnyUser bridges the gap between advanced robotic capabilities and the need for accessible non-expert interaction, laying the foundation for practical assistive robots adaptable to real-world human environments.
TransMedSeg: A Transferable Semantic Framework for Semi-Supervised Medical Image Segmentation
May 20, 2025Semi-supervised learning (SSL) has achieved significant progress in medical image segmentation (SSMIS) through effective utilization of limited labeled data. While current SSL methods for medical images predominantly rely on consistency regularization and pseudo-labeling, they often overlook transferable semantic relationships across different clinical domains and imaging modalities. To address this, we propose TransMedSeg, a novel transferable semantic framework for semi-supervised medical image segmentation. Our approach introduces a Transferable Semantic Augmentation (TSA) module, which implicitly enhances feature representations by aligning domain-invariant semantics through cross-domain distribution matching and intra-domain structural preservation. Specifically, TransMedSeg constructs a unified feature space where teacher network features are adaptively augmented towards student network semantics via a lightweight memory module, enabling implicit semantic transformation without explicit data generation. Interestingly, this augmentation is implicitly realized through an expected transferable cross-entropy loss computed over the augmented teacher distribution. An upper bound of the expected loss is theoretically derived and minimized during training, incurring negligible computational overhead. Extensive experiments on medical image datasets demonstrate that TransMedSeg outperforms existing semi-supervised methods, establishing a new direction for transferable representation learning in medical image analysis.
Dual-stream Feature Augmentation for Domain Generalization
Sep 07, 2024



Domain generalization (DG) task aims to learn a robust model from source domains that could handle the out-of-distribution (OOD) issue. In order to improve the generalization ability of the model in unseen domains, increasing the diversity of training samples is an effective solution. However, existing augmentation approaches always have some limitations. On the one hand, the augmentation manner in most DG methods is not enough as the model may not see the perturbed features in approximate the worst case due to the randomness, thus the transferability in features could not be fully explored. On the other hand, the causality in discriminative features is not involved in these methods, which harms the generalization ability of model due to the spurious correlations. To address these issues, we propose a Dual-stream Feature Augmentation~(DFA) method by constructing some hard features from two perspectives. Firstly, to improve the transferability, we construct some targeted features with domain related augmentation manner. Through the guidance of uncertainty, some hard cross-domain fictitious features are generated to simulate domain shift. Secondly, to take the causality into consideration, the spurious correlated non-causal information is disentangled by an adversarial mask, then the more discriminative features can be extracted through these hard causal related information. Different from previous fixed synthesizing strategy, the two augmentations are integrated into a unified learnable feature disentangle model. Based on these hard features, contrastive learning is employed to keep the semantic consistency and improve the robustness of the model. Extensive experiments on several datasets demonstrated that our approach could achieve state-of-the-art performance for domain generalization. Our code is available at: https://github.com/alusi123/DFA.
Improving Unsupervised Domain Adaptation by Reducing Bi-level Feature Redundancy
Dec 28, 2020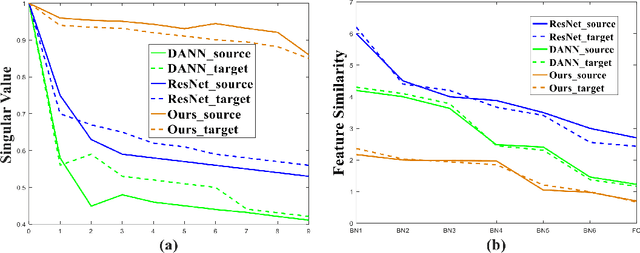
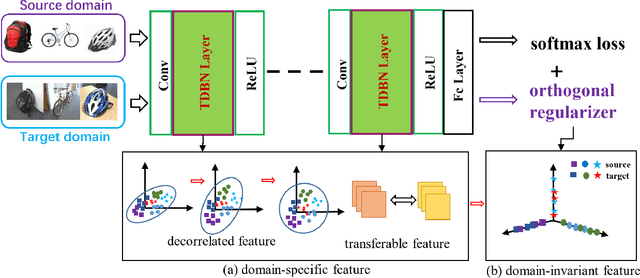

Reducing feature redundancy has shown beneficial effects for improving the accuracy of deep learning models, thus it is also indispensable for the models of unsupervised domain adaptation (UDA). Nevertheless, most recent efforts in the field of UDA ignores this point. Moreover, main schemes realizing this in general independent of UDA purely involve a single domain, thus might not be effective for cross-domain tasks. In this paper, we emphasize the significance of reducing feature redundancy for improving UDA in a bi-level way. For the first level, we try to ensure compact domain-specific features with a transferable decorrelated normalization module, which preserves specific domain information whilst easing the side effect of feature redundancy on the sequel domain-invariance. In the second level, domain-invariant feature redundancy caused by domain-shared representation is further mitigated via an alternative brand orthogonality for better generalization. These two novel aspects can be easily plugged into any BN-based backbone neural networks. Specifically, simply applying them to ResNet50 has achieved competitive performance to the state-of-the-arts on five popular benchmarks. Our code will be available at https://github.com/dreamkily/gUDA.