 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Tabular Foundation Models Meet Strategic Tabular Data: A Prior Alignment Approach
May 19, 2026Tabular foundation models based on pretrained prior-data fitted networks~(PFNs) have shown strong generalization on diverse tabular tasks, but they are typically designed for \emph{non-strategic} settings where data distributions are independent of deployed classifiers. In many real-world decision scenarios, however, individuals may strategically modify their features after deployment to obtain favorable outcomes, inducing a post-deployment distribution shift. This paper studies whether PFN-style tabular foundation models can generalize to such \emph{strategic} tabular data. We show that strategic manipulation creates a mismatch between the non-strategic prior learned during pretraining and the post-manipulation strategic prior, which leads to systematic prediction bias. To address this issue, we propose \textbf{Strategic Prior-data Fitted Network}~\textit{(SPN)}, an inference-time strategy-aware framework that adapts tabular foundation models to strategic environments without retraining. SPN constructs strategic in-context examples to approximate post-manipulation inputs and aligns PFN predictions with the induced strategic distribution. Experiments on real-world and synthetic tabular datasets show that SPN consistently improves robustness and predictive performance under strategic manipulation compared with both tabular foundation models and classical tabular methods.
Breaking the Gradient Barrier: Unveiling Large Language Models for Strategic Classification
Nov 10, 2025Strategic classification~(SC) explores how individuals or entities modify their features strategically to achieve favorable classification outcomes. However, existing SC methods, which are largely based on linear models or shallow neural networks, face significant limitations in terms of scalability and capacity when applied to real-world datasets with significantly increasing scale, especially in financial services and the internet sector. In this paper, we investigate how to leverage large language models to design a more scalable and efficient SC framework, especially in the case of growing individuals engaged with decision-making processes. Specifically, we introduce GLIM, a gradient-free SC method grounded in in-context learning. During the feed-forward process of self-attention, GLIM implicitly simulates the typical bi-level optimization process of SC, including both the feature manipulation and decision rule optimization. Without fine-tuning the LLMs, our proposed GLIM enjoys the advantage of cost-effective adaptation in dynamic strategic environments. Theoretically, we prove GLIM can support pre-trained LLMs to adapt to a broad range of strategic manipulations. We validate our approach through experiments with a collection of pre-trained LLMs on real-world and synthetic datasets in financial and internet domains, demonstrating that our GLIM exhibits both robustness and efficiency, and offering an effective solution for large-scale SC tasks.
Null-text Guidance in Diffusion Models is Secretly a Cartoon-style Creator
May 11, 2023



Classifier-free guidance is an effective sampling technique in diffusion models that has been widely adopted. The main idea is to extrapolate the model in the direction of text guidance and away from null-text guidance. In this paper, we demonstrate that null-text guidance in diffusion models is secretly a cartoon-style creator, i.e., the generated images can be efficiently transformed into cartoons by simply perturbing the null-text guidance. Specifically, we proposed two disturbance methods, i.e., Rollback disturbance (Back-D) and Image disturbance (Image-D), to construct misalignment between the noisy images used for predicting null-text guidance and text guidance (subsequently referred to as \textbf{null-text noisy image} and \textbf{text noisy image} respectively) in the sampling process. Back-D achieves cartoonization by altering the noise level of null-text noisy image via replacing $x_t$ with $x_{t+\Delta t}$. Image-D, alternatively, produces high-fidelity, diverse cartoons by defining $x_t$ as a clean input image, which further improves the incorporation of finer image details. Through comprehensive experiments, we delved into the principle of noise disturbing for null-text and uncovered that the efficacy of disturbance depends on the correlation between the null-text noisy image and the source image. Moreover, our proposed techniques, which can generate cartoon images and cartoonize specific ones, are training-free and easily integrated as a plug-and-play component in any classifier-free guided diffusion model. Project page is available at \url{https://nulltextforcartoon.github.io/}.
Recent Advances for Quantum Neural Networks in Generative Learning
Jun 07, 2022

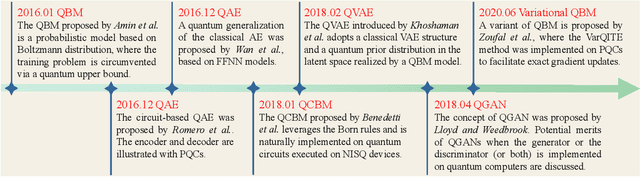
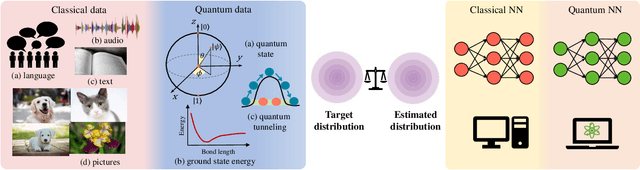
Quantum computers are next-generation devices that hold promise to perform calculations beyond the reach of classical computers. A leading method towards achieving this goal is through quantum machine learning, especially quantum generative learning. Due to the intrinsic probabilistic nature of quantum mechanics, it is reasonable to postulate that quantum generative learning models (QGLMs) may surpass their classical counterparts. As such, QGLMs are receiving growing attention from the quantum physics and computer science communities, where various QGLMs that can be efficiently implemented on near-term quantum machines with potential computational advantages are proposed. In this paper, we review the current progress of QGLMs from the perspective of machine learning. Particularly, we interpret these QGLMs, covering quantum circuit born machines, quantum generative adversarial networks, quantum Boltzmann machines, and quantum autoencoders, as the quantum extension of classical generative learning models. In this context, we explore their intrinsic relation and their fundamental differences. We further summarize the potential applications of QGLMs in both conventional machine learning tasks and quantum physics. Last, we discuss the challenges and further research directions for QGLMs.