 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject Counting and Instance Segmentation with Image-level Supervision
Mar 06, 2019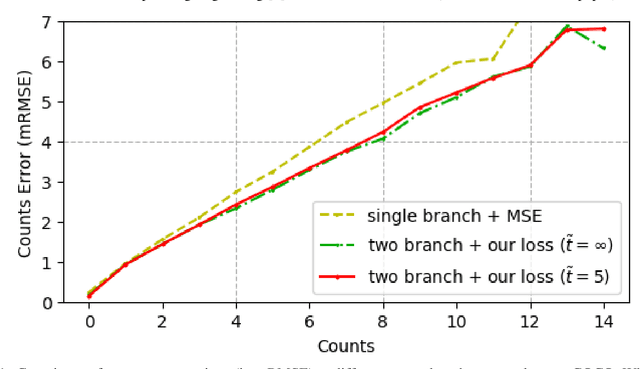



Common object counting in a natural scene is a challenging problem in computer vision with numerous real-world applications. Existing image-level supervised common object counting approaches only predict the global object count and rely on additional instance-level supervision to also determine object locations. We propose an image-level supervised approach that provides both the global object count and the spatial distribution of object instances by constructing an object category density map. Motivated by psychological studies, we further reduce image-level supervision using a limited object count information (up to four). To the best of our knowledge, we are the first to propose image-level supervised density map estimation for common object counting and demonstrate its effectiveness in image-level supervised instance segmentation. Comprehensive experiments are performed on the PASCAL VOC and COCO datasets. Our approach outperforms existing methods, including those using instance-level supervision, on both datasets for common object counting. Moreover, our approach improves state-of-the-art image-level supervised instance segmentation with a relative gain of 17.8% in terms of average best overlap, on the PASCAL VOC 2012 dataset.
Crowd Counting and Density Estimation by Trellis Encoder-Decoder Network
Mar 03, 2019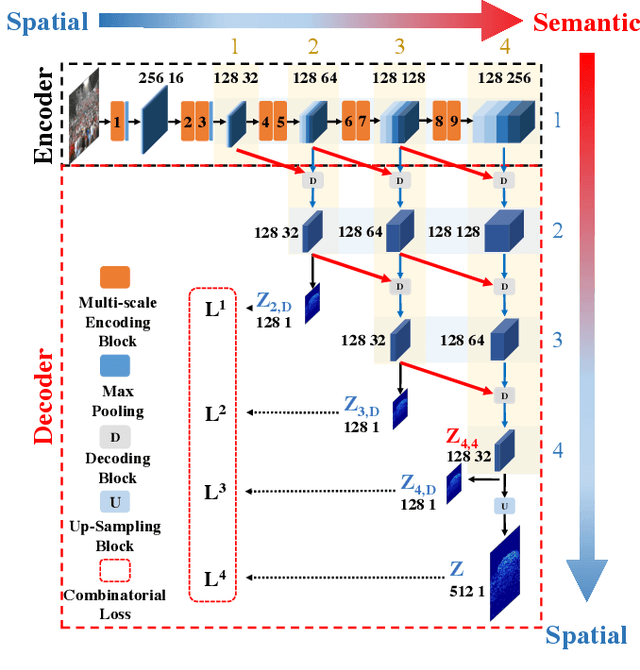
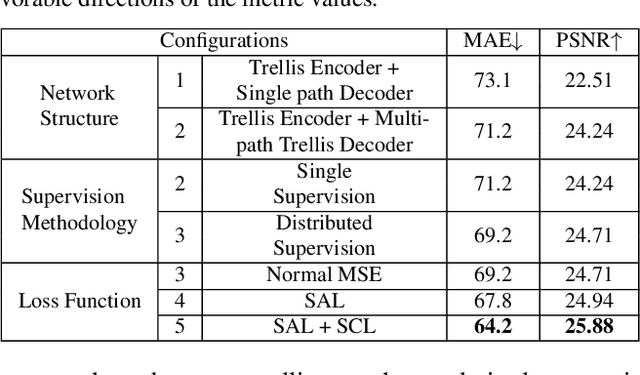
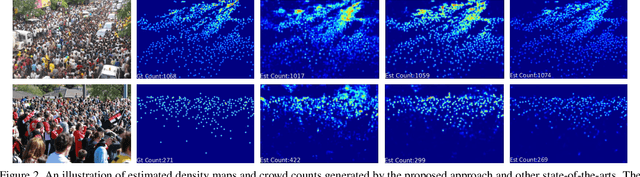
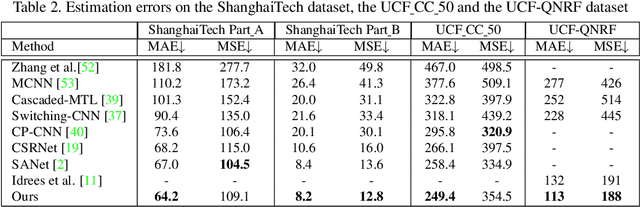
Crowd counting has recently attracted increasing interest in computer vision but remains a challenging problem. In this paper, we propose a trellis encoder-decoder network (TEDnet) for crowd counting, which focuses on generating high-quality density estimation maps. The major contributions are four-fold. First, we develop a new trellis architecture that incorporates multiple decoding paths to hierarchically aggregate features at different encoding stages, which can handle large variations of objects. Second, we design dense skip connections interleaved across paths to facilitate sufficient multi-scale feature fusions and to absorb the supervision information. Third, we propose a new combinatorial loss to enforce local coherence and spatial correlation in density maps. By distributedly imposing this combinatorial loss on intermediate outputs, gradient vanishing can be largely alleviated for better back-propagation and faster convergence. Finally, our TEDnet achieves new state-of-the art performance on four benchmarks, with an improvement up to 14% in terms of MAE.
Pixelated Semantic Colorization
Feb 07, 2019
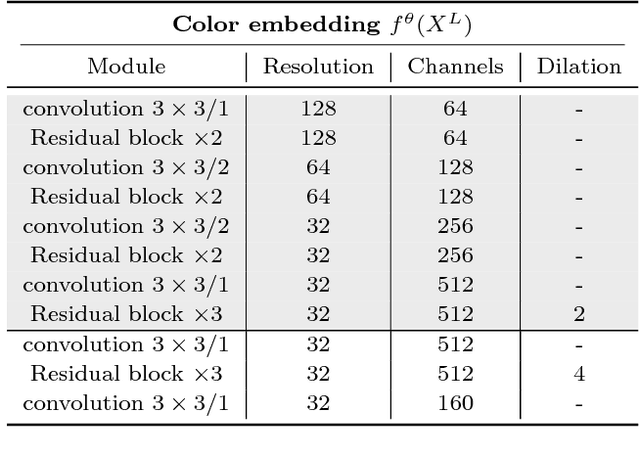
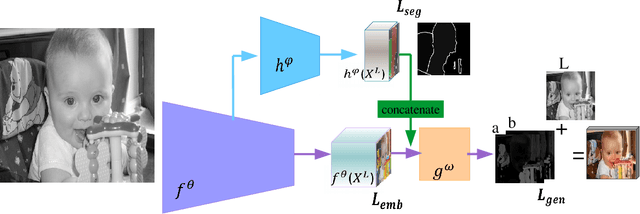
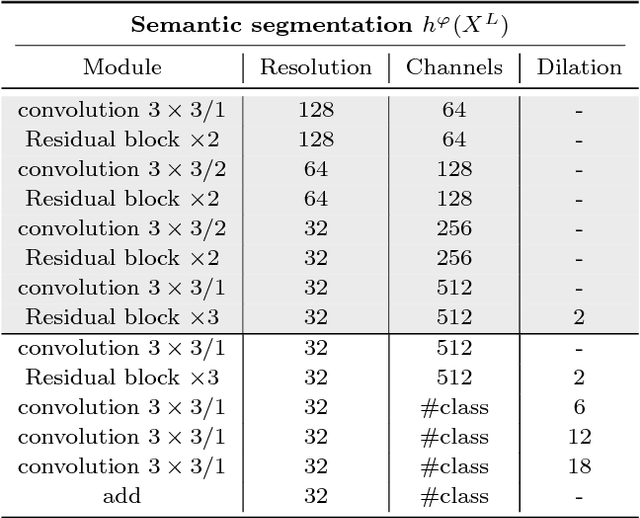
While many image colorization algorithms have recently shown the capability of producing plausible color versions from gray-scale photographs, they still suffer from limited semantic understanding. To address this shortcoming, we propose to exploit pixelated object semantics to guide image colorization. The rationale is that human beings perceive and distinguish colors based on the semantic categories of objects. Starting from an autoregressive model, we generate image color distributions, from which diverse colored results are sampled. We propose two ways to incorporate object semantics into the colorization model: through a pixelated semantic embedding and a pixelated semantic generator. Specifically, the proposed convolutional neural network includes two branches. One branch learns what the object is, while the other branch learns the object colors. The network jointly optimizes a color embedding loss, a semantic segmentation loss and a color generation loss, in an end-to-end fashion. Experiments on PASCAL VOC2012 and COCO-stuff reveal that our network, when trained with semantic segmentation labels, produces more realistic and finer results compared to the colorization state-of-the-art.
Max-margin Class Imbalanced Learning with Gaussian Affinity
Jan 23, 2019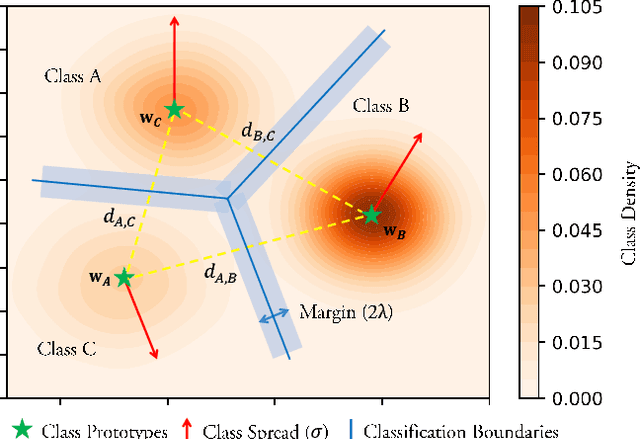
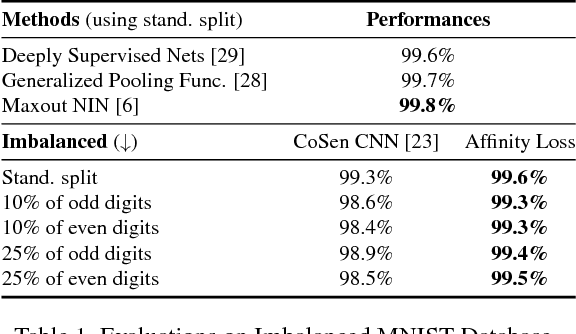
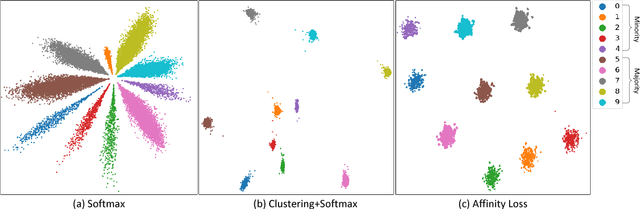
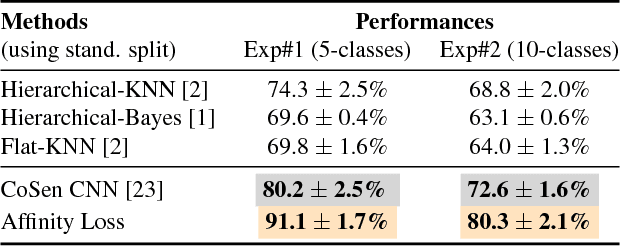
Real-world object classes appear in imbalanced ratios. This poses a significant challenge for classifiers which get biased towards frequent classes. We hypothesize that improving the generalization capability of a classifier should improve learning on imbalanced datasets. Here, we introduce the first hybrid loss function that jointly performs classification and clustering in a single formulation. Our approach is based on an `affinity measure' in Euclidean space that leads to the following benefits: (1) direct enforcement of maximum margin constraints on classification boundaries, (2) a tractable way to ensure uniformly spaced and equidistant cluster centers, (3) flexibility to learn multiple class prototypes to support diversity and discriminability in feature space. Our extensive experiments demonstrate the significant performance improvements on visual classification and verification tasks on multiple imbalanced datasets. The proposed loss can easily be plugged in any deep architecture as a differentiable block and demonstrates robustness against different levels of data imbalance and corrupted labels.
Striking the Right Balance with Uncertainty
Jan 22, 2019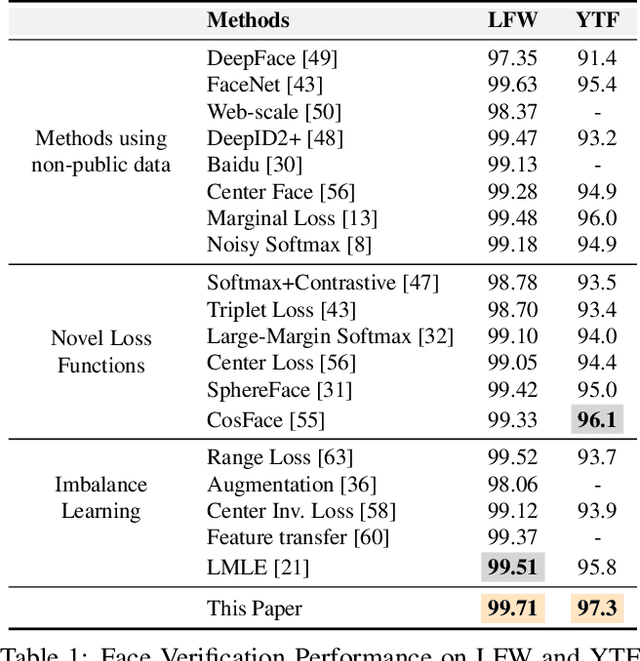
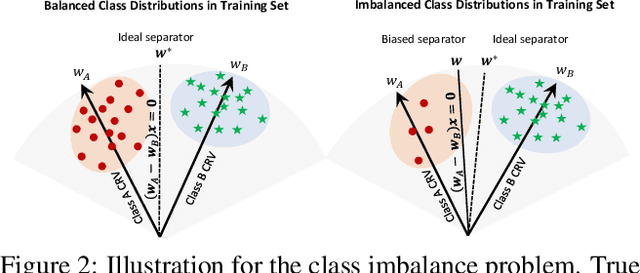
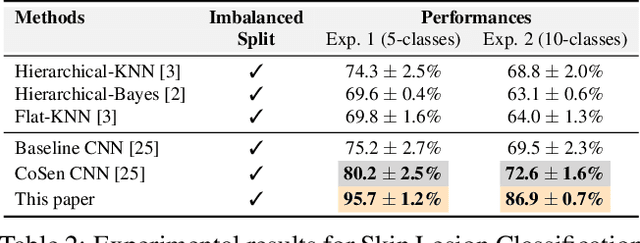
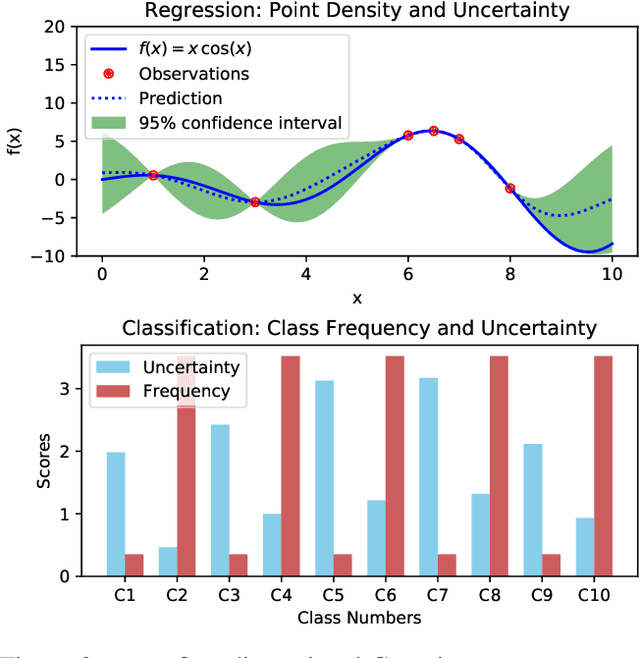
Learning unbiased models on imbalanced datasets is a significant challenge. Rare classes tend to get a concentrated representation in the classification space which hampers the generalization of learned boundaries to new test examples. In this paper, we demonstrate that the Bayesian uncertainty estimates directly correlate with the rarity of classes and the difficulty level of individual samples. Subsequently, we present a novel framework for uncertainty based class imbalance learning that follows two key insights: First, classification boundaries should be extended further away from a more uncertain (rare) class to avoid overfitting and enhance its generalization. Second, each sample should be modeled as a multi-variate Gaussian distribution with a mean vector and a covariance matrix defined by the sample's uncertainty. The learned boundaries should respect not only the individual samples but also their distribution in the feature space. Our proposed approach efficiently utilizes sample and class uncertainty information to learn robust features and more generalizable classifiers. We systematically study the class imbalance problem and derive a novel loss formulation for max-margin learning based on Bayesian uncertainty measure. The proposed method shows significant performance improvements on six benchmark datasets for face verification, attribute prediction, digit/object classification and skin lesion detection.
Image Super-Resolution as a Defense Against Adversarial Attacks
Jan 07, 2019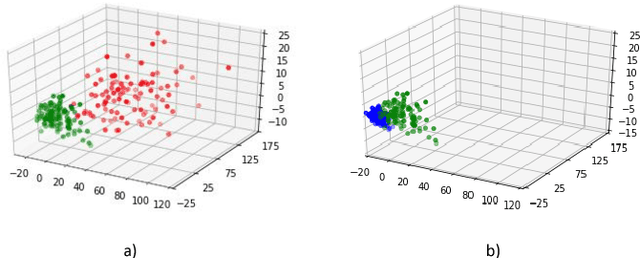
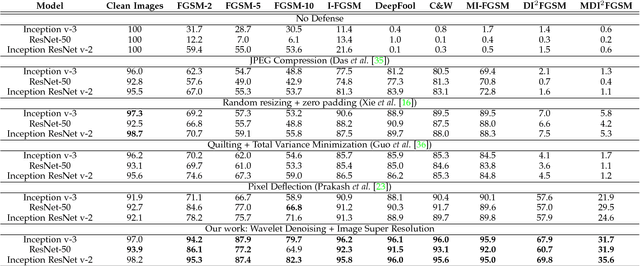
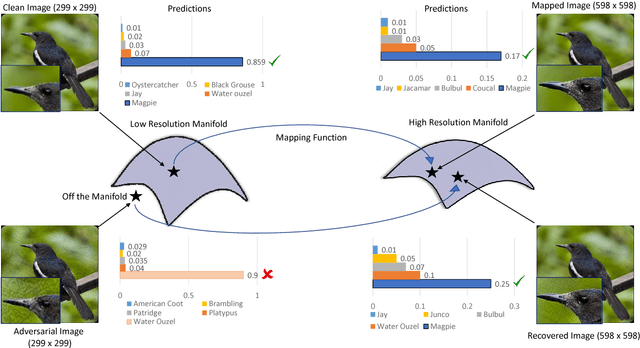
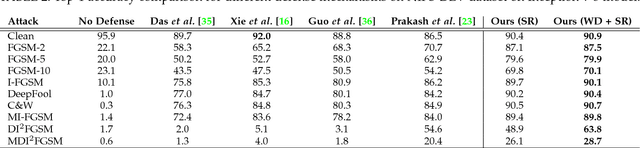
Convolutional Neural Networks have achieved significant success across multiple computer vision tasks. However, they are vulnerable to carefully crafted, human imperceptible adversarial noise patterns which constrain their deployment in critical security-sensitive systems. This paper proposes a computationally efficient image enhancement approach that provides a strong defense mechanism to effectively mitigate the effect of such adversarial perturbations. We show that the deep image restoration networks learn mapping functions that can bring \textit{off-the-manifold} adversarial samples onto the natural image manifold, thus restoring classifier beliefs towards correct classes. A distinguishing feature of our approach is that, in addition to providing robustness against attacks, it simultaneously enhances image quality and retains models performance on clean images. Furthermore, the proposed method does not modify the classifier or requires a separate mechanism to detect adversarial images. The effectiveness of the scheme has been demonstrated through extensive experiments, where it has proven a strong defense in both white-box and black-box attack settings. The proposed scheme is simple and has the following advantages: (1) it does not require any model training or parameter optimization, (2) it complements other existing defense mechanisms, (3) it is agnostic to the attacked model and attack type and (4) it provides superior performance across all popular attack algorithms. Our codes are publicly available at https://github.com/aamir-mustafa/super-resolution-adversarial-defense.
3D PersonVLAD: Learning Deep Global Representations for Video-based Person Re-identification
Jan 04, 2019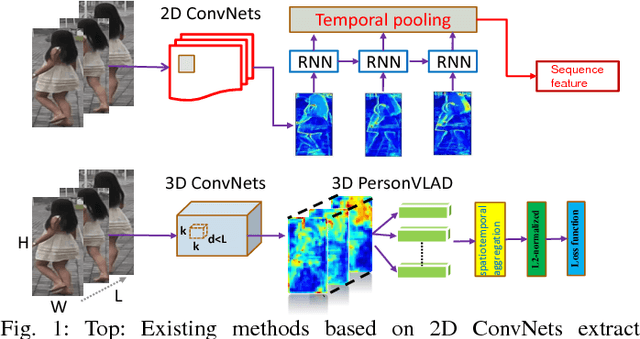
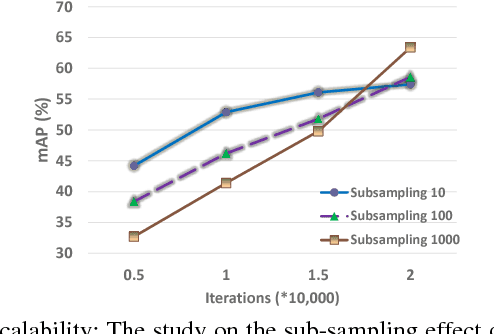
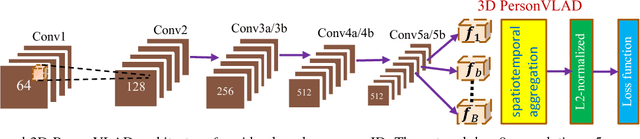
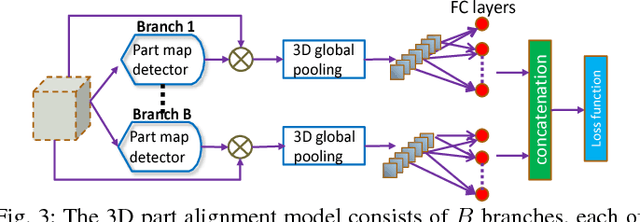
In this paper, we introduce a global video representation to video-based person re-identification (re-ID) that aggregates local 3D features across the entire video extent. Most of the existing methods rely on 2D convolutional networks (ConvNets) to extract frame-wise deep features which are pooled temporally to generate the video-level representations. However, 2D ConvNets lose temporal input information immediately after the convolution, and a separate temporal pooling is limited in capturing human motion in shorter sequences. To this end, we present a \textit{global} video representation (3D PersonVLAD), complementary to 3D ConvNets as a novel layer to capture the appearance and motion dynamics in full-length videos. However, encoding each video frame in its entirety and computing an aggregate global representation across all frames is tremendously challenging due to occlusions and misalignments. To resolve this, our proposed network is further augmented with 3D part alignment module to learn local features through soft-attention module. These attended features are statistically aggregated to yield identity-discriminative representations. Our global 3D features are demonstrated to achieve state-of-the-art results on three benchmark datasets: MARS \cite{MARS}, iLIDS-VID \cite{VideoRanking}, and PRID 2011
Object-centric Auto-encoders and Dummy Anomalies for Abnormal Event Detection in Video
Dec 11, 2018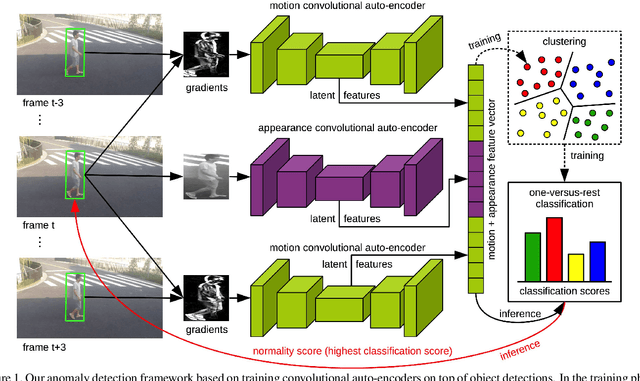
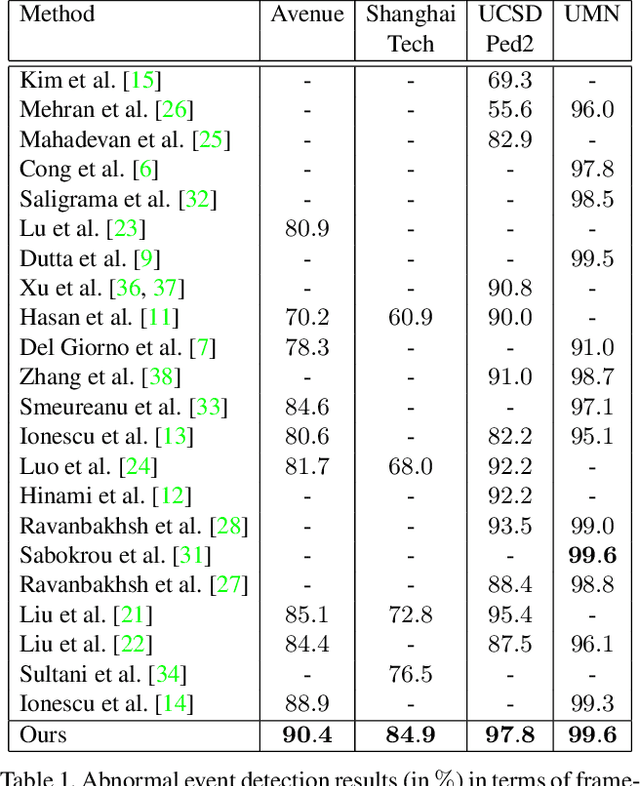


Abnormal event detection in video is a challenging vision problem. Most existing approaches formulate abnormal event detection as an outlier detection task, due to the scarcity of anomalous data during training. Because of the lack of prior information regarding abnormal events, these methods are not fully-equipped to differentiate between normal and abnormal events. In this work, we formalize abnormal event detection as a one-versus-rest binary classification problem. Our contribution is two-fold. First, we introduce an unsupervised feature learning framework based on object-centric convolutional auto-encoders to encode both motion and appearance information. Second, we propose a supervised classification approach based on clustering the training samples into normality clusters. A one-versus-rest abnormal event classifier is then employed to separate each normality cluster from the rest. For the purpose of training the classifier, the other clusters act as dummy anomalies. During inference, an object is labeled as abnormal if the highest classification score assigned by the one-versus-rest classifiers is negative. Comprehensive experiments are performed on four benchmarks: Avenue, ShanghaiTech, UCSD and UMN. Our approach provides superior results on all four data sets. On the large-scale ShanghaiTech data set, our method provides an absolute gain of 12.1% in terms of frame-level AUC compared to the state-of-the-art method [Liu et al., CVPR 2018].
ActionXPose: A Novel 2D Multi-view Pose-based Algorithm for Real-time Human Action Recognition
Oct 29, 2018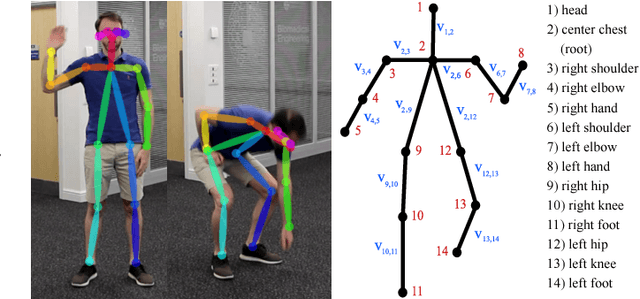
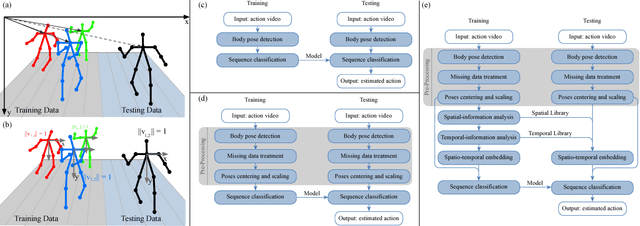
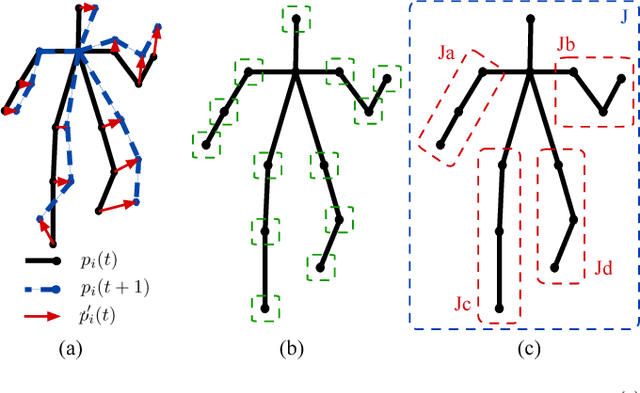

We present ActionXPose, a novel 2D pose-based algorithm for posture-level Human Action Recognition (HAR). The proposed approach exploits 2D human poses provided by OpenPose detector from RGB videos. ActionXPose aims to process poses data to be provided to a Long Short-Term Memory Neural Network and to a 1D Convolutional Neural Network, which solve the classification problem. ActionXPose is one of the first algorithms that exploits 2D human poses for HAR. The algorithm has real-time performance and it is robust to camera movings, subject proximity changes, viewpoint changes, subject appearance changes and provide high generalization degree. In fact, extensive simulations show that ActionXPose can be successfully trained using different datasets at once. State-of-the-art performance on popular datasets for posture-related HAR problems (i3DPost, KTH) are provided and results are compared with those obtained by other methods, including the selected ActionXPose baseline. Moreover, we also proposed two novel datasets called MPOSE and ISLD recorded in our Intelligent Sensing Lab, to show ActionXPose generalization performance.
Cycle-Consistent Deep Generative Hashing for Cross-Modal Retrieval
Oct 29, 2018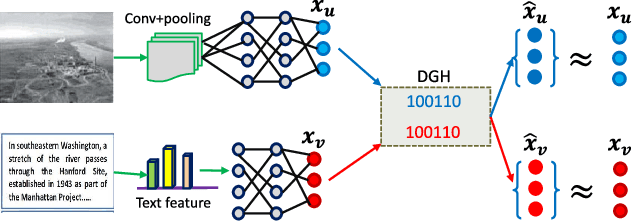
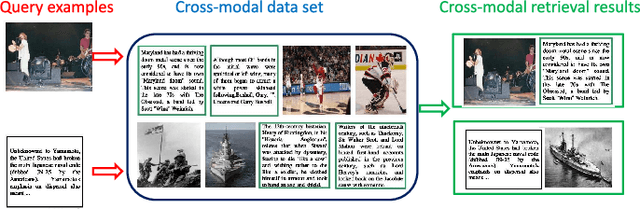
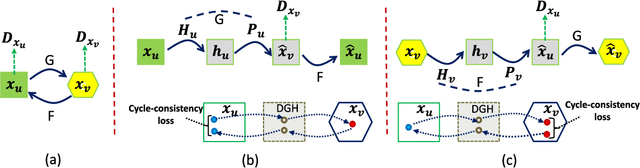
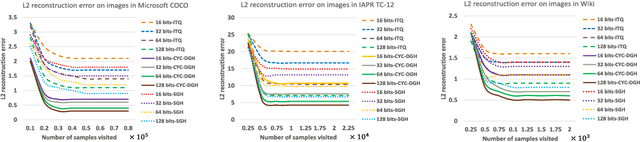
In this paper, we propose a novel deep generative approach to cross-modal retrieval to learn hash functions in the absence of paired training samples through the cycle consistency loss. Our proposed approach employs adversarial training scheme to lean a couple of hash functions enabling translation between modalities while assuming the underlying semantic relationship. To induce the hash codes with semantics to the input-output pair, cycle consistency loss is further proposed upon the adversarial training to strengthen the correlations between inputs and corresponding outputs. Our approach is generative to learn hash functions such that the learned hash codes can maximally correlate each input-output correspondence, meanwhile can also regenerate the inputs so as to minimize the information loss. The learning to hash embedding is thus performed to jointly optimize the parameters of the hash functions across modalities as well as the associated generative models. Extensive experiments on a variety of large-scale cross-modal data sets demonstrate that our proposed method achieves better retrieval results than the state-of-the-arts.