 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNLH: A Blind Pixel-level Non-local Method for Real-world Image Denoising
Aug 04, 2019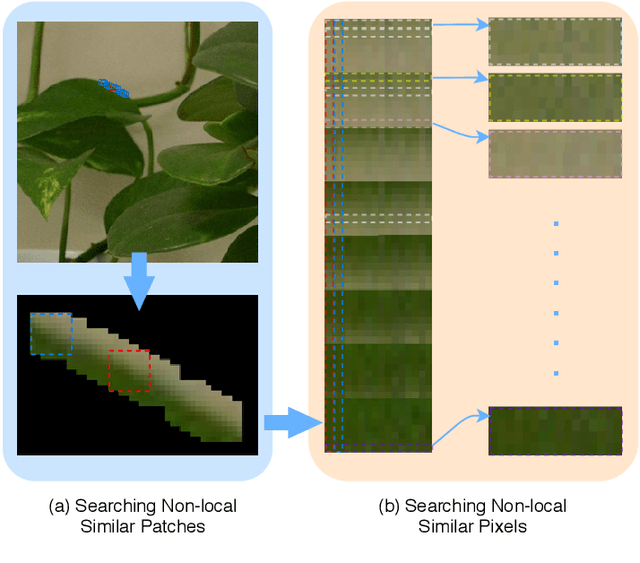
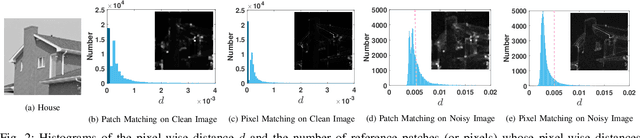
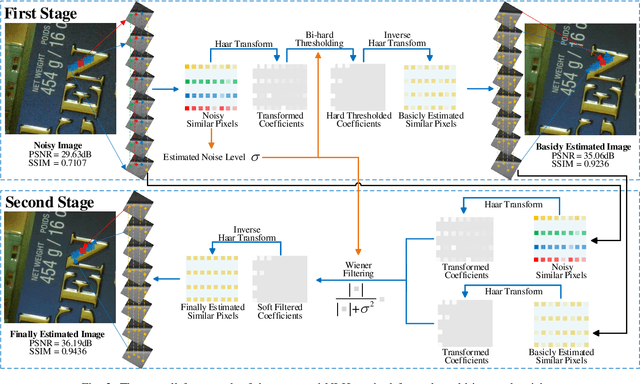

Non-local self similarity (NSS) is a powerful prior of natural images for image denoising. Most of existing denoising methods employ similar patches, which is a patch-level NSS prior. In this paper, we take one step forward by introducing a pixel-level NSS prior, i.e., searching similar pixels across a non-local region. This is motivated by the fact that finding closely similar pixels is more feasible than similar patches in natural images, which can be used to enhance image denoising performance. With the introduced pixel-level NSS prior, we propose an accurate noise level estimation method, and then develop a blind image denoising method based on the lifting Haar transform and Wiener filtering techniques. Experiments on benchmark datasets demonstrate that, the proposed method achieves much better performance than state-of-the-art methods on real-world image denoising. The code will be released.
ET-Net: A Generic Edge-aTtention Guidance Network for Medical Image Segmentation
Jul 25, 2019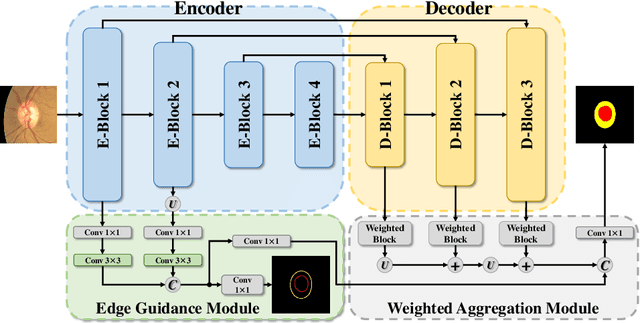
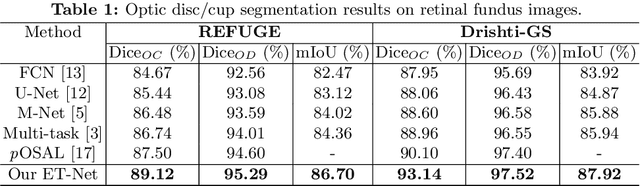
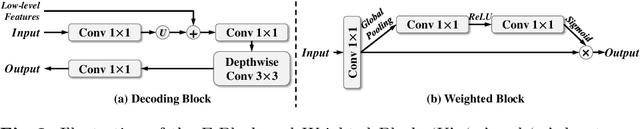
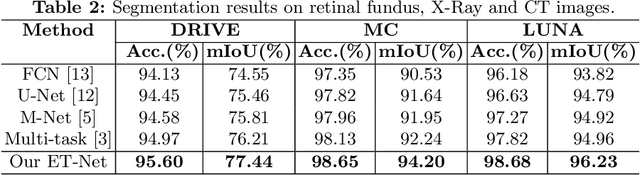
Segmentation is a fundamental task in medical image analysis. However, most existing methods focus on primary region extraction and ignore edge information, which is useful for obtaining accurate segmentation. In this paper, we propose a generic medical segmentation method, called Edge-aTtention guidance Network (ET-Net), which embeds edge-attention representations to guide the segmentation network. Specifically, an edge guidance module is utilized to learn the edge-attention representations in the early encoding layers, which are then transferred to the multi-scale decoding layers, fused using a weighted aggregation module. The experimental results on four segmentation tasks (i.e., optic disc/cup and vessel segmentation in retinal images, and lung segmentation in chest X-Ray and CT images) demonstrate that preserving edge-attention representations contributes to the final segmentation accuracy, and our proposed method outperforms current state-of-the-art segmentation methods. The source code of our method is available at https://github.com/ZzzJzzZ/ETNet.
Evaluation of Retinal Image Quality Assessment Networks in Different Color-spaces
Jul 18, 2019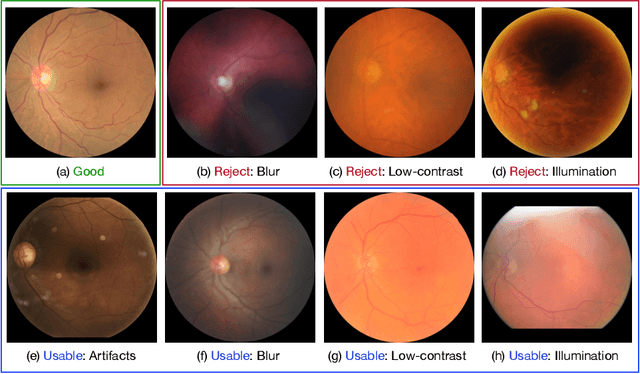
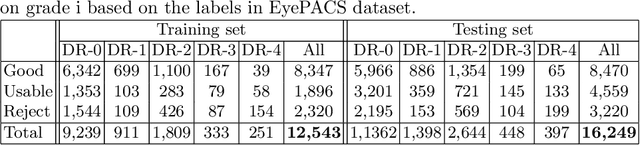
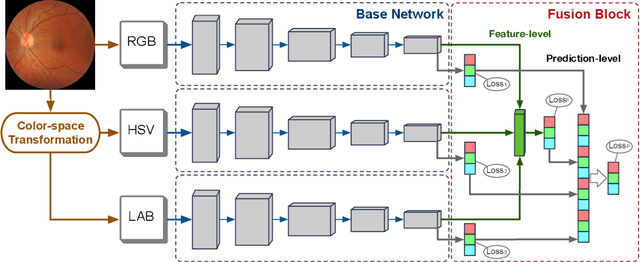
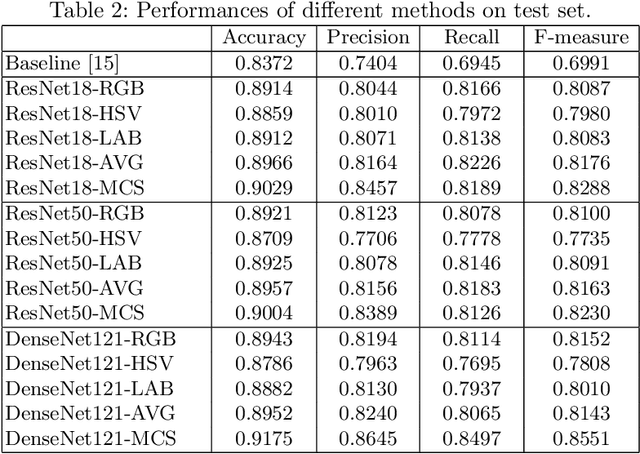
Retinal image quality assessment (RIQA) is essential for controlling the quality of retinal imaging and guaranteeing the reliability of diagnoses by ophthalmologists or automated analysis systems. Existing RIQA methods focus on the RGB color-space and are developed based on small datasets with binary quality labels (i.e., `Accept' and `Reject'). In this paper, we first re-annotate an Eye-Quality (EyeQ) dataset with 28,792 retinal images from the EyePACS dataset, based on a three-level quality grading system (i.e., `Good', `Usable' and `Reject') for evaluating RIQA methods. Our RIQA dataset is characterized by its large-scale size, multi-level grading, and multi-modality. Then, we analyze the influences on RIQA of different color-spaces, and propose a simple yet efficient deep network, named Multiple Color-space Fusion Network (MCF-Net), which integrates the different color-space representations at both a feature-level and prediction-level to predict image quality grades. Experiments on our EyeQ dataset show that our MCF-Net obtains a state-of-the-art performance, outperforming the other deep learning methods. Furthermore, we also evaluate diabetic retinopathy (DR) detection methods on images of different quality, and demonstrate that the performances of automated diagnostic systems are highly dependent on image quality.
Coupled-Projection Residual Network for MRI Super-Resolution
Jul 12, 2019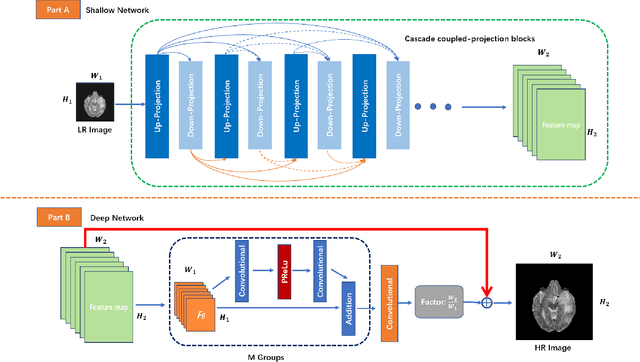
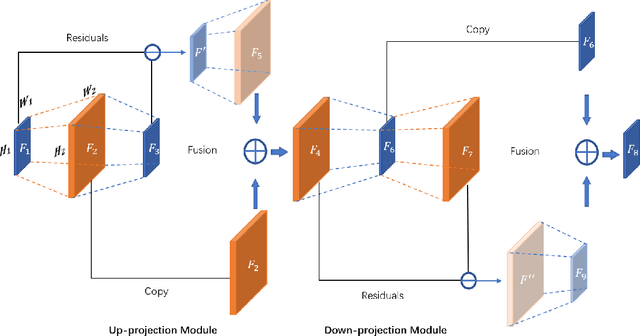
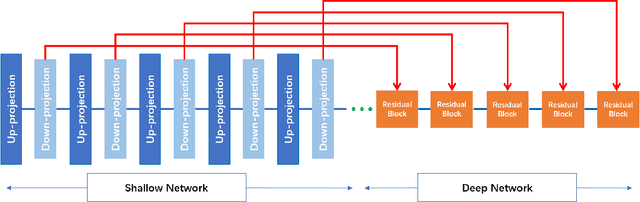
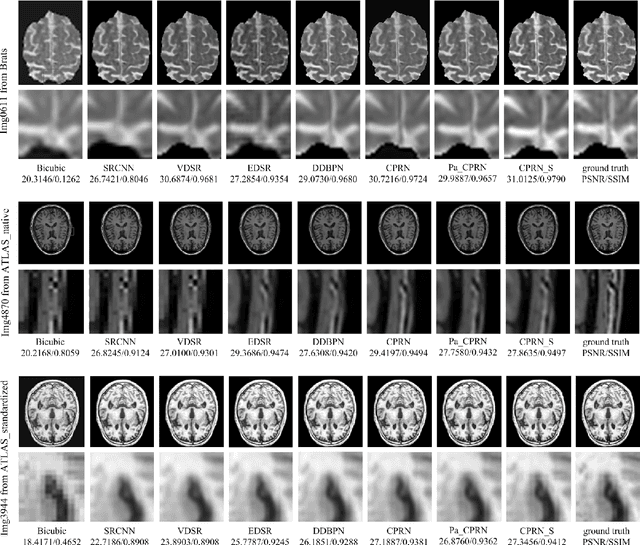
Magnetic Resonance Imaging(MRI) has been widely used in clinical application and pathology research by helping doctors make more accurate diagnoses. On the other hand, accurate diagnosis by MRI remains a great challenge as images obtained via present MRI techniques usually have low resolutions. Improving MRI image quality and resolution thus becomes a critically important task. This paper presents an innovative Coupled-Projection Residual Network (CPRN) for MRI super-resolution. The CPRN consists of two complementary sub-networks: a shallow network and a deep network that keep the content consistency while learning high frequency differences between low-resolution and high-resolution images. The shallow sub-network employs coupled-projection for better retaining the MRI image details, where a novel feedback mechanism is introduced to guide the reconstruction of high-resolution images. The deep sub-network learns from the residuals of the high-frequency image information, where multiple residual blocks are cascaded to magnify the MRI images at the last network layer. Finally, the features from the shallow and deep sub-networks are fused for the reconstruction of high-resolution MRI images. For effective fusion of features from the deep and shallow sub-networks, a step-wise connection (CPRN S) is designed as inspired by the human cognitive processes (from simple to complex). Experiments over three public MRI datasets show that our proposed CPRN achieves superior MRI super-resolution performance as compared with the state-of-the-art. Our source code will be publicly available at http://www.yongxu.org/lunwen.html.
Noisy-As-Clean: Learning Unsupervised Denoising from the Corrupted Image
Jul 04, 2019
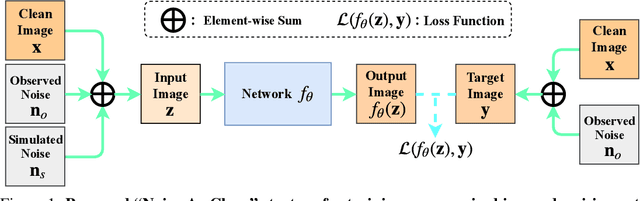
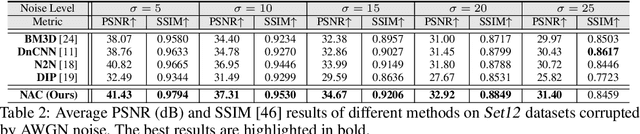
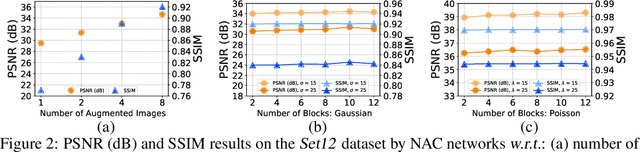
In the past few years, supervised networks have achieved promising performance on image denoising. These methods learn image priors and synthetic noise statistics from plenty pairs of noisy and clean images. Recently, several unsupervised denoising networks are proposed only using external noisy images for training. However, the networks learned from external data inherently suffer from the domain gap dilemma, i.e., the image priors and noise statistics are very different between the training data and the corrupted test images. This dilemma becomes more clear when dealing with the signal dependent realistic noise in real photographs. In this work, we provide a statistically useful conclusion: it is possible to learn an unsupervised network only with the corrupted image, approximating the optimal parameters of a supervised network learned with pairs of noisy and clean images. This is achieved by proposing a "Noisy-As-Clean" strategy: taking the corrupted image as "clean" target and the simulated noisy images (based on the corrupted image) as inputs. Extensive experiments show that the unsupervised denoising networks learned with our "Noisy-As-Clean" strategy surprisingly outperforms previous supervised networks on removing several typical synthetic noise and realistic noise. The code will be publicly released.
STAR: A Structure and Texture Aware Retinex Model
Jun 30, 2019



Retinex theory is developed mainly to decompose an image into the illumination and reflectance components by analyzing local image derivatives. In this theory, larger derivatives are attributed to the changes in piece-wise constant reflectance, while smaller derivatives are emerged in the smooth illumination. In this paper, we propose to utilize the exponentiated derivatives (with an exponent $\gamma$) of an observed image to generate a structure map when being amplified with $\gamma>1$ and a texture map when being shrank with $\gamma<1$. To this end, we design exponential filters for the local derivatives, and present their capability on extracting accurate structure and texture maps, influenced by the choices of exponents $\gamma$ on the local derivatives. The extracted structure and texture maps are employed to regularize the illumination and reflectance components in Retinex decomposition. A novel Structure and Texture Aware Retinex (STAR) model is further proposed for illumination and reflectance decomposition of a single image. We solve the STAR model in an alternating minimization manner. Each sub-problem is transformed into a vectorized least squares regression with closed-form solution. Comprehensive experiments demonstrate that, the proposed STAR model produce better quantitative and qualitative performance than previous competing methods, on illumination and reflectance estimation, low-light image enhancement, and color correction. The code will be publicly released.
Human vs Machine Attention in Neural Networks: A Comparative Study
Jun 24, 2019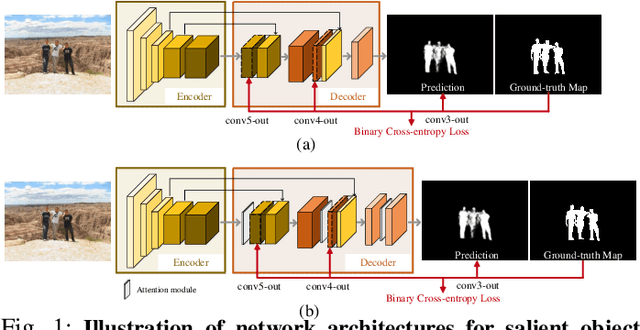
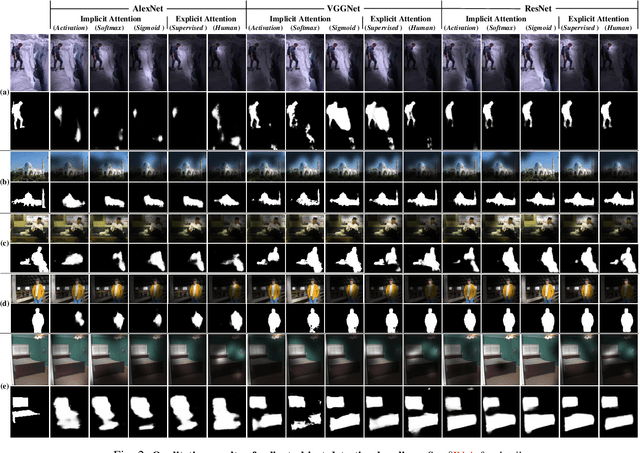
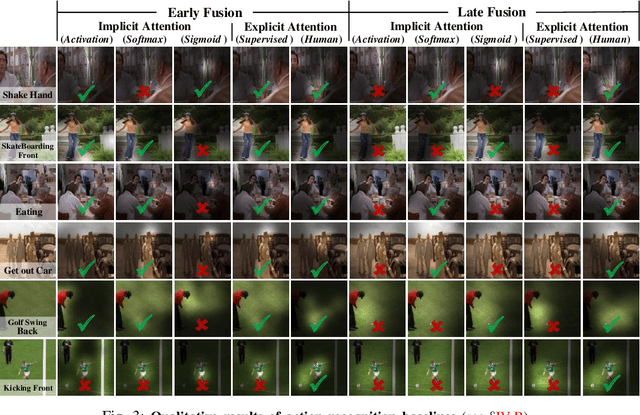
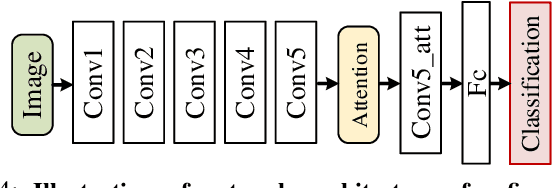
Recent years have witnessed a surge in the popularity of attention mechanisms encoded within deep neural networks. Inspired by the selective attention in the visual cortex, artificial attention is designed to focus a neural network on the most task-relevant input signal. Many works claim that the attention mechanism offers an extra dimension of interpretability by explaining where the neural networks look. However, recent studies demonstrate that artificial attention maps do not always coincide with common intuition. In view of these conflicting evidences, here we make a systematic study on using artificial attention and human attention in neural network design. With three example computer vision tasks (i.e., salient object segmentation, video action recognition, and fine-grained image classification), diverse representative network backbones (i.e., AlexNet, VGGNet, ResNet) and famous architectures (i.e., Two-stream, FCN), corresponding real human gaze data, and systematically conducted large-scale quantitative studies, we offer novel insights into existing artificial attention mechanisms and give preliminary answers to several key questions related to human and artificial attention mechanisms. Our overall results demonstrate that human attention is capable of bench-marking the meaningful `ground-truth' in attention-driven tasks, where the more the artificial attention is close to the human attention, the better the performance; for higher-level vision tasks, it is case-by-case. We believe it would be advisable for attention-driven tasks to explicitly force a better alignment between artificial and human attentions to boost the performance; such alignment would also benefit making the deep networks more transparent and explainable for higher-level computer vision tasks.
Dynamic Distribution Pruning for Efficient Network Architecture Search
Jun 09, 2019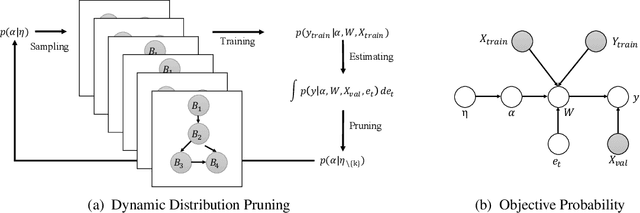
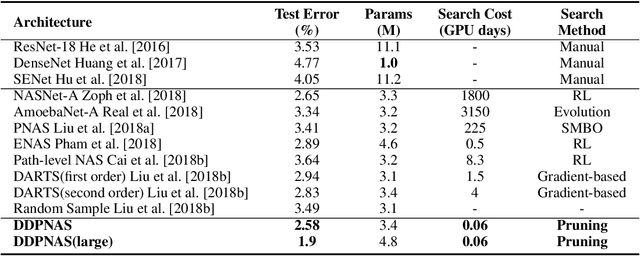
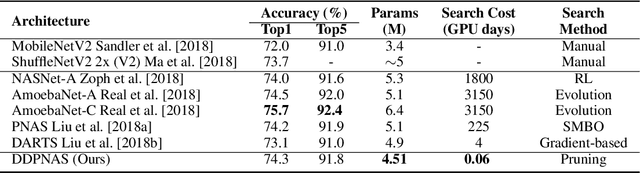
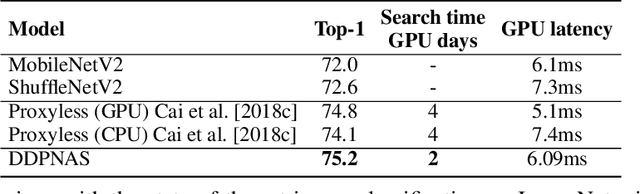
Network architectures obtained by Neural Architecture Search (NAS) have shown state-of-the-art performance in various computer vision tasks. Despite the exciting progress, the computational complexity of the forward-backward propagation and the search process makes it difficult to apply NAS in practice. In particular, most previous methods require thousands of GPU days for the search process to converge. In this paper, we propose a dynamic distribution pruning method towards extremely efficient NAS, which samples architectures from a joint categorical distribution. The search space is dynamically pruned every a few epochs to update this distribution, and the optimal neural architecture is obtained when there is only one structure remained. We conduct experiments on two widely-used datasets in NAS. On CIFAR-10, the optimal structure obtained by our method achieves the state-of-the-art $1.9$\% test error, while the search process is more than $1,000$ times faster (only $1.5$ GPU hours on a Tesla V100) than the state-of-the-art NAS algorithms. On ImageNet, our model achieves 75.2\% top-1 accuracy under the MobileNet settings, with a time cost of only $2$ GPU days that is $100\%$ acceleration over the fastest NAS algorithm. The code is available at \url{ https://github.com/tanglang96/DDPNAS}
Extreme Points Derived Confidence Map as a Cue For Class-Agnostic Segmentation Using Deep Neural Network
Jun 06, 2019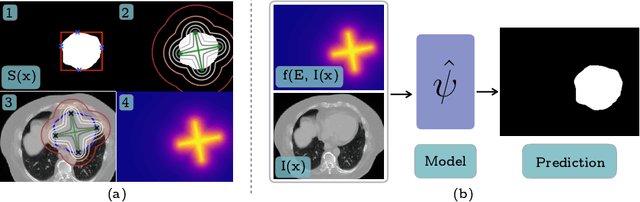
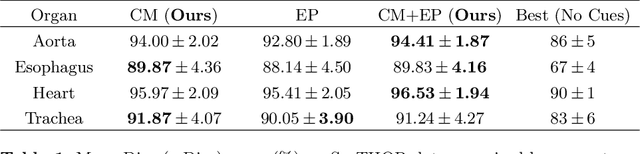
To automate the process of segmenting an anatomy of interest, we can learn a model from previously annotated data. The learning-based approach uses annotations to train a model that tries to emulate the expert labeling on a new data set. While tremendous progress has been made using such approaches, labeling of medical images remains a time-consuming and expensive task. In this paper, we evaluate the utility of extreme points in learning to segment. Specifically, we propose a novel approach to compute a confidence map from extreme points that quantitatively encodes the priors derived from extreme points. We use the confidence map as a cue to train a deep neural network based on ResNet-101 and PSP module to develop a class-agnostic segmentation model that outperforms state-of-the-art method that employs extreme points as a cue. Further, we evaluate a realistic use-case by using our model to generate training data for supervised learning (U-Net) and observed that U-Net performs comparably when trained with either the generated data or the ground truth data. These findings suggest that models trained using cues can be used to generate reliable training data.
Dynamic Neural Network Decoupling
Jun 04, 2019
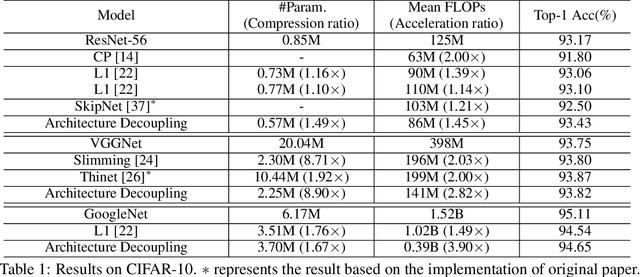
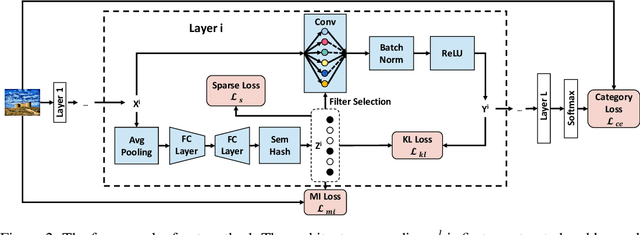
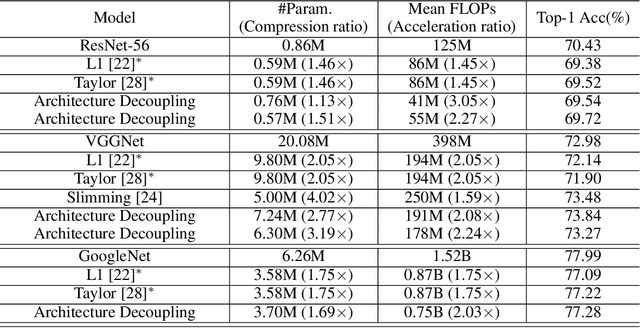
Convolutional neural networks (CNNs) have achieved a superior performance by taking advantages of the complex network architectures and huge numbers of parameters, which however become uninterpretable and challenge their full potential to practical applications. Towards better understand the rationale behind the network decisions, we propose a novel architecture decoupling method, which dynamically discovers the hierarchical path consisting of activated filters for each input image. In particular, architecture controlling module is introduced in each layer to encode the network architecture and identify the activated filters corresponding to the specific input. Then, mutual information between architecture encoding and the attribute of input image is maximized to decouple the network architecture, and subsequently disentangles the filters by limiting the outputs of filter during training. Extensive experiments show that several merits have been achieved based on the proposed architecture decoupling, i.e., interpretation, acceleration and adversarial attacking.